
Chapter 13 — Shannon’s Theory of Secrecy Systems#
“The problems of cryptography and secrecy systems furnish an interesting application of communication theory.” — Claude E. Shannon, Communication Theory of Secrecy Systems, 1949
In this chapter we study Shannon’s information-theoretic framework for cryptographic security. We formalize the notions of perfect secrecy, entropy, and unicity distance, implement tools for computing these quantities, and experimentally verify Shannon’s fundamental theorems about the one-time pad and the limits of unconditional security.
13.1 Historical Context#
In September 1945, an internal Bell Labs memorandum titled “A Mathematical Theory of Cryptography” circulated among a small group of cleared researchers. Its author, Claude Elwood Shannon (1916–2001), had spent the war years at Bell Labs working on fire-control systems, cryptographic teletype links, and the theoretical foundations of secrecy.
The declassified and expanded version appeared in 1949 as “Communication Theory of Secrecy Systems” in the Bell System Technical Journal. This paper, alongside Shannon’s landmark 1948 paper “A Mathematical Theory of Communication,” created the field of information theory and provided the first rigorous, mathematical definition of cryptographic security.
Before Shannon, cryptographic security was an art: ciphers were considered “good” or “bad” based on intuition, experience, and the failure of known attacks. Shannon changed this by asking a precise question: under what conditions is it information-theoretically impossible for an adversary to learn anything about the plaintext from the ciphertext?
His answers were both illuminating and sobering:
Perfect secrecy is achievable — the one-time pad (Vernam cipher) provides it.
Perfect secrecy is expensive — it requires keys at least as long as the message.
Practical ciphers inevitably leak information — the unicity distance tells us how much ciphertext is needed to uniquely determine the key.
Tip
Shannon’s 1949 paper unified three previously separate intellectual traditions: Kerckhoffs’ principles of cipher design (1883), Vernam’s one-time pad (1917), and Friedman’s statistical methods of cryptanalysis (1920s). Information theory provided the common language that connected them all.
13.2 Formal Definitions#
Definition 13.1 (Cryptosystem)
A cryptosystem (or secrecy system) is a five-tuple \((\mathcal{P}, \mathcal{C}, \mathcal{K}, E, D)\) where:
\(\mathcal{P}\) is a finite set of plaintexts,
\(\mathcal{C}\) is a finite set of ciphertexts,
\(\mathcal{K}\) is a finite set of keys, chosen according to a probability distribution,
\(E = \{E_k : \mathcal{P} \to \mathcal{C} \mid k \in \mathcal{K}\}\) is a family of encryption functions,
\(D = \{D_k : \mathcal{C} \to \mathcal{P} \mid k \in \mathcal{K}\}\) is a family of decryption functions,
satisfying \(D_k(E_k(p)) = p\) for all \(k \in \mathcal{K}\) and \(p \in \mathcal{P}\).
Definition 13.2 (Perfect Secrecy)
A cryptosystem provides perfect secrecy if for every plaintext \(p \in \mathcal{P}\) and every ciphertext \(c \in \mathcal{C}\) with \(\Pr[C = c] > 0\):
Equivalently, the random variables \(P\) and \(C\) are statistically independent: observing the ciphertext provides zero information about the plaintext, regardless of the adversary’s computational power.
Definition 13.3 (Shannon Entropy)
The entropy of a discrete random variable \(X\) with probability mass function \(p(x)\) is defined as:
with the convention that \(0 \log_2 0 = 0\). Entropy measures the average uncertainty (in bits) about \(X\) before it is observed.
The conditional entropy of \(X\) given \(Y\) is:
The mutual information between \(X\) and \(Y\) is:
Perfect secrecy is equivalent to \(I(P; C) = 0\).
Definition 13.4 (Unicity Distance)
The unicity distance \(n_0\) of a cipher is the minimum amount of ciphertext (in characters) needed such that the expected number of spurious keys drops to zero. It is approximated by:
where \(H(K) = \log_2 |\mathcal{K}|\) is the key entropy (assuming uniformly distributed keys) and \(D = R - r_L\) is the redundancy of the plaintext language, with \(R = \log_2 |\mathcal{A}|\) being the absolute rate and \(r_L\) being the actual per-character entropy of the language.
For English, \(R = \log_2 26 \approx 4.70\) bits and \(r_L \approx 1.0\)–\(1.5\) bits per letter, giving redundancy \(D \approx 3.2\)–\(3.7\) bits per letter.
13.3 Key Theorems#
Theorem 13.1 (Shannon’s Theorem — Perfect Secrecy Requires Large Keys)
If a cryptosystem \((\mathcal{P}, \mathcal{C}, \mathcal{K}, E, D)\) provides perfect secrecy, then \(|\mathcal{K}| \geq |\mathcal{P}|\).
That is, the number of keys must be at least as large as the number of possible plaintexts.
Proof
Suppose \(|\mathcal{K}| < |\mathcal{P}|\). Fix a ciphertext \(c\) with \(\Pr[C = c] > 0\). The set of plaintexts reachable from \(c\) is:
Since \(|\mathcal{P}(c)| \leq |\mathcal{K}| < |\mathcal{P}|\), there exists some \(p^* \in \mathcal{P}\) with \(p^* \notin \mathcal{P}(c)\). For this plaintext:
But if \(\Pr[P = p^*] > 0\), then \(\Pr[P = p^* \mid C = c] \neq \Pr[P = p^*]\), violating perfect secrecy. \(\blacksquare\)
Theorem 13.2 (One-Time Pad Achieves Perfect Secrecy)
Let \(\mathcal{P} = \mathcal{C} = \mathcal{K} = \{0, 1, \ldots, n-1\}^L\) (strings of length \(L\) over an alphabet of size \(n\)). Define encryption as \(E_k(p) = (p + k) \bmod n\) (component-wise) with \(k\) chosen uniformly at random. Then this cryptosystem — the one-time pad — achieves perfect secrecy.
Proof
For any plaintext \(p\) and ciphertext \(c\), there is exactly one key \(k = (c - p) \bmod n\) such that \(E_k(p) = c\). Since \(k\) is uniformly distributed:
This probability is the same for all \(p\). By Bayes’ theorem:
Since \(\Pr[C = c] = \sum_{p'} \Pr[C = c \mid P = p'] \cdot \Pr[P = p'] = \frac{1}{n^L} \sum_{p'} \Pr[P = p'] = \frac{1}{n^L}\),
we get \(\Pr[P = p \mid C = c] = \Pr[P = p]\). \(\blacksquare\)
Danger
Reusing a one-time pad key destroys perfect secrecy.
If two messages \(p_1, p_2\) are encrypted with the same key \(k\), then \(c_1 \oplus c_2 = p_1 \oplus p_2\), leaking the XOR of the plaintexts. This was exploited in the VENONA project to break Soviet one-time pad messages where key material was inadvertently reused.
13.4 Implementation#
We implement the ShannonAnalyzer class, a one-time pad, and tools for computing
unicity distance and spurious keys.
import numpy as np
import math
from collections import Counter
class ShannonAnalyzer:
"""
Tools for computing information-theoretic quantities relevant
to Shannon's theory of secrecy systems.
All logarithms are base 2 (measuring information in bits).
"""
@staticmethod
def entropy(probs):
"""
Compute Shannon entropy H(X) = -sum p(x) log2 p(x).
Parameters
----------
probs : array-like
Probability distribution (must sum to 1).
Returns
-------
float
Entropy in bits.
"""
p = np.asarray(probs, dtype=float)
p = p[p > 0] # exclude zero entries (0 log 0 = 0)
return -np.sum(p * np.log2(p))
@staticmethod
def joint_entropy(joint_probs):
"""
Compute joint entropy H(X, Y) from a joint distribution table.
Parameters
----------
joint_probs : 2D array
Joint probability table p(x, y).
Returns
-------
float
Joint entropy in bits.
"""
p = np.asarray(joint_probs, dtype=float).ravel()
p = p[p > 0]
return -np.sum(p * np.log2(p))
@staticmethod
def conditional_entropy(joint_probs):
"""
Compute conditional entropy H(X|Y) = H(X,Y) - H(Y).
Parameters
----------
joint_probs : 2D array
Joint probability table p(x, y) with X on rows, Y on columns.
Returns
-------
float
H(X|Y) in bits.
"""
jp = np.asarray(joint_probs, dtype=float)
h_xy = ShannonAnalyzer.joint_entropy(jp)
# Marginal of Y (sum over rows)
p_y = jp.sum(axis=0)
h_y = ShannonAnalyzer.entropy(p_y)
return h_xy - h_y
@staticmethod
def mutual_information(joint_probs):
"""
Compute mutual information I(X;Y) = H(X) - H(X|Y).
Parameters
----------
joint_probs : 2D array
Joint probability table p(x, y).
Returns
-------
float
I(X;Y) in bits.
"""
jp = np.asarray(joint_probs, dtype=float)
p_x = jp.sum(axis=1)
h_x = ShannonAnalyzer.entropy(p_x)
h_x_given_y = ShannonAnalyzer.conditional_entropy(jp)
return h_x - h_x_given_y
@staticmethod
def text_entropy(text, n=1):
"""
Estimate per-character entropy of text using n-gram frequencies.
Parameters
----------
text : str
Input text (only alphabetic characters are used).
n : int
n-gram order (1 = unigram, 2 = bigram, etc.).
Returns
-------
float
Estimated per-character entropy in bits.
"""
cleaned = ''.join(c.upper() for c in text if c.isalpha())
if len(cleaned) < n:
return 0.0
ngrams = [cleaned[i:i+n] for i in range(len(cleaned) - n + 1)]
counts = Counter(ngrams)
total = sum(counts.values())
probs = np.array([c / total for c in counts.values()])
return ShannonAnalyzer.entropy(probs) / n
@staticmethod
def unicity_distance(key_bits, redundancy_per_char):
"""
Compute the unicity distance n_0 = H(K) / D.
Parameters
----------
key_bits : float
Key entropy H(K) in bits.
redundancy_per_char : float
Language redundancy D = R - r_L in bits per character.
Returns
-------
float
Unicity distance in characters.
"""
if redundancy_per_char <= 0:
return float('inf')
return key_bits / redundancy_per_char
@staticmethod
def spurious_keys(key_space_size, n, redundancy_per_char):
"""
Estimate the expected number of spurious keys for ciphertext
of length n.
Parameters
----------
key_space_size : int
Total number of keys |K|.
n : int
Ciphertext length in characters.
redundancy_per_char : float
Language redundancy D bits per character.
Returns
-------
float
Expected number of spurious keys.
"""
# E[spurious keys] ~ |K| * 2^(-nD) - 1
exponent = -n * redundancy_per_char
return max(0.0, key_space_size * (2 ** exponent) - 1)
# --- Quick demo ---
sa = ShannonAnalyzer()
# Entropy of a fair coin
print(f'Entropy of fair coin: {float(sa.entropy([0.5, 0.5])):.4f} bits')
# Entropy of a biased coin
print(f'Entropy of biased (0.9): {float(sa.entropy([0.9, 0.1])):.4f} bits')
# Entropy of a uniform distribution over 26 letters
print(f'Entropy of uniform 26: {float(sa.entropy(np.ones(26)/26)):.4f} bits')
print(f'\nShannonAnalyzer class loaded successfully.')
Entropy of fair coin: 1.0000 bits
Entropy of biased (0.9): 0.4690 bits
Entropy of uniform 26: 4.7004 bits
ShannonAnalyzer class loaded successfully.
import numpy as np
class OneTimePad:
"""
One-time pad (Vernam cipher) over an alphabet of size `mod`.
Default: mod=26 for the standard Latin alphabet.
"""
def __init__(self, mod=26):
self.mod = mod
def generate_key(self, length, rng=None):
"""Generate a uniformly random key of given length."""
if rng is None:
rng = np.random.default_rng()
return rng.integers(0, self.mod, size=length)
def encrypt(self, plaintext_ints, key):
"""Encrypt: c = (p + k) mod n."""
p = np.asarray(plaintext_ints)
k = np.asarray(key)
assert len(p) == len(k), 'Key must be same length as plaintext'
return (p + k) % self.mod
def decrypt(self, ciphertext_ints, key):
"""Decrypt: p = (c - k) mod n."""
c = np.asarray(ciphertext_ints)
k = np.asarray(key)
return (c - k) % self.mod
def encrypt_text(self, plaintext, key):
"""Encrypt a string (uppercase letters only)."""
p_ints = np.array([ord(c) - 65 for c in plaintext.upper() if c.isalpha()])
c_ints = self.encrypt(p_ints, key[:len(p_ints)])
return ''.join(chr(int(c) + 65) for c in c_ints)
def decrypt_text(self, ciphertext, key):
"""Decrypt a string (uppercase letters only)."""
c_ints = np.array([ord(c) - 65 for c in ciphertext.upper() if c.isalpha()])
p_ints = self.decrypt(c_ints, key[:len(c_ints)])
return ''.join(chr(int(p) + 65) for p in p_ints)
# --- Demo ---
otp = OneTimePad(mod=26)
rng = np.random.default_rng(42)
plaintext = 'SHANNONPROVEDPERFECTSECRECY'
key = otp.generate_key(len(plaintext), rng=rng)
ciphertext = otp.encrypt_text(plaintext, key)
recovered = otp.decrypt_text(ciphertext, key)
print(f'Plaintext: {plaintext}')
print(f'Key: {" ".join(str(int(k)) for k in key)}')
print(f'Ciphertext: {ciphertext}')
print(f'Decrypted: {recovered}')
print(f'Correct: {recovered == plaintext}')
Plaintext: SHANNONPROVEDPERFECTSECRECY
Key: 2 20 17 11 11 22 2 18 5 2 13 25 19 19 18 20 13 3 21 11 13 9 4 24 20 16 10
Ciphertext: UBRYYKPHWQIDWIWLSHXEFNGPYSI
Decrypted: SHANNONPROVEDPERFECTSECRECY
Correct: True
import numpy as np
import math
class UnicityDistanceCalculator:
"""
Compute unicity distance and spurious key counts for various
classical ciphers.
The English language redundancy D is estimated as:
D = log2(26) - r_L
where r_L is the per-character entropy rate of English.
"""
# Estimated per-character entropy of English at different n-gram levels
ENGLISH_ENTROPY_ESTIMATES = {
'unigram': 4.19, # from letter frequencies
'bigram': 3.56, # from bigram frequencies
'trigram': 3.0, # from trigram frequencies
'shannon': 1.3, # Shannon's estimate (long-range correlations)
}
ABSOLUTE_RATE = math.log2(26) # ~4.70 bits/char
CIPHER_KEY_SIZES = {
'shift': {'key_bits': math.log2(26), # 26 keys
'description': 'Shift (Caesar) cipher: 26 keys'},
'affine': {'key_bits': math.log2(12 * 26), # 312 keys
'description': 'Affine cipher: 312 keys'},
'vigenere_3': {'key_bits': 3 * math.log2(26),
'description': 'Vigenere with key length 3'},
'vigenere_5': {'key_bits': 5 * math.log2(26),
'description': 'Vigenere with key length 5'},
'vigenere_10': {'key_bits': 10 * math.log2(26),
'description': 'Vigenere with key length 10'},
'vigenere_20': {'key_bits': 20 * math.log2(26),
'description': 'Vigenere with key length 20'},
'substitution': {'key_bits': math.log2(math.factorial(26)), # 26! keys
'description': 'Simple substitution: 26! keys'},
'enigma': {'key_bits': math.log2(60 * 26**3 * 150738274937250),
'description': 'Enigma (3 rotors + plugboard)'},
}
def __init__(self, english_entropy_model='shannon'):
self.r_L = self.ENGLISH_ENTROPY_ESTIMATES[english_entropy_model]
self.D = self.ABSOLUTE_RATE - self.r_L
def compute(self, cipher_name):
"""Compute unicity distance for a named cipher."""
info = self.CIPHER_KEY_SIZES[cipher_name]
n0 = info['key_bits'] / self.D
return {
'cipher': cipher_name,
'description': info['description'],
'key_bits': info['key_bits'],
'redundancy': self.D,
'unicity_distance': n0
}
def compute_all(self):
"""Compute unicity distance for all known ciphers."""
results = []
for name in self.CIPHER_KEY_SIZES:
results.append(self.compute(name))
return results
# --- Demo ---
udc = UnicityDistanceCalculator(english_entropy_model='shannon')
print(f'English redundancy D = {float(udc.D):.2f} bits/char')
print(f'(using Shannon\'s estimate r_L = {udc.r_L} bits/char)\n')
results = udc.compute_all()
print(f'{"Cipher":<22} {"H(K) bits":>10} {"n_0 (chars)":>12}')
print('=' * 48)
for r in results:
print(f'{r["cipher"]:<22} {float(r["key_bits"]):>10.1f} {float(r["unicity_distance"]):>12.1f}')
English redundancy D = 3.40 bits/char
(using Shannon's estimate r_L = 1.3 bits/char)
Cipher H(K) bits n_0 (chars)
================================================
shift 4.7 1.4
affine 8.3 2.4
vigenere_3 14.1 4.1
vigenere_5 23.5 6.9
vigenere_10 47.0 13.8
vigenere_20 94.0 27.6
substitution 88.4 26.0
enigma 67.1 19.7
13.5 Experiments#
Experiment 1: Entropy of English vs. Random Text#
We compare the per-character entropy of English text at different n-gram levels with the entropy of uniformly random text. As the n-gram order increases, the estimated entropy of English decreases, reflecting the long-range statistical structure (redundancy) in natural language.
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
from collections import Counter
# A substantial English sample for entropy estimation
english_sample = (
"the problems of cryptography and secrecy systems furnish an interesting "
"application of communication theory the theory of secrecy systems was "
"first studied on a scientific basis by shannon in his classified report "
"of nineteen forty five which was later published in nineteen forty nine "
"in this paper shannon introduced the concepts of perfect secrecy entropy "
"redundancy and the unicity distance these ideas provided the first "
"rigorous mathematical framework for analyzing the security of cryptographic "
"systems the fundamental insight is that natural language contains a great "
"deal of redundancy which can be exploited by a cryptanalyst to narrow down "
"the set of possible keys english has a per character entropy rate of roughly "
"one to one and a half bits far below the maximum of about four point seven "
"bits that would be achieved by a uniform random distribution over the "
"twenty six letters this redundancy means that with enough ciphertext the "
"correct key can in principle be uniquely determined the amount of ciphertext "
"needed is the unicity distance which is computed as the ratio of the key "
"entropy to the language redundancy per character for the simple substitution "
"cipher with its enormous key space of twenty six factorial the unicity "
"distance is still only about twenty five characters"
) * 4 # Repeat for more data
def compute_ngram_entropy(text, n):
"""Compute per-character entropy using n-gram frequencies."""
cleaned = ''.join(c.upper() for c in text if c.isalpha())
if len(cleaned) < n:
return 0.0
ngrams = [cleaned[i:i+n] for i in range(len(cleaned) - n + 1)]
counts = Counter(ngrams)
total = sum(counts.values())
probs = np.array([c / total for c in counts.values()])
h = -np.sum(probs * np.log2(probs))
return h / n
# Generate random text for comparison
rng = np.random.default_rng(42)
random_text = ''.join(chr(rng.integers(0, 26) + 65)
for _ in range(len(english_sample)))
ngram_orders = [1, 2, 3, 4, 5, 6]
english_entropies = [compute_ngram_entropy(english_sample, n)
for n in ngram_orders]
random_entropies = [compute_ngram_entropy(random_text, n)
for n in ngram_orders]
# Plot
fig, ax = plt.subplots(figsize=(9, 5))
ax.plot(ngram_orders, english_entropies, 'o-', color='#2c3e50',
linewidth=2, markersize=8, label='English text')
ax.plot(ngram_orders, random_entropies, 's--', color='#e74c3c',
linewidth=2, markersize=8, label='Random text')
ax.axhline(y=np.log2(26), color='gray', linestyle=':',
alpha=0.6, label=f'Max entropy (log$_2$ 26 = {float(np.log2(26)):.2f})')
ax.axhline(y=1.3, color='#27ae60', linestyle=':',
alpha=0.6, label="Shannon's estimate (~1.3 bits)")
ax.set_xlabel('n-gram Order', fontsize=12)
ax.set_ylabel('Per-character Entropy (bits)', fontsize=12)
ax.set_title('Entropy of English vs. Random Text at Different n-gram Levels',
fontsize=13, fontweight='bold')
ax.set_xticks(ngram_orders)
ax.set_xticklabels([f'{n}-gram' for n in ngram_orders])
ax.legend(fontsize=10)
ax.grid(True, alpha=0.3)
ax.set_ylim(0, 5.5)
plt.tight_layout()
plt.savefig('entropy_english_vs_random.png', dpi=150, bbox_inches='tight')
plt.show()
print('\nPer-character entropy estimates (bits):')
print(f'{"n-gram":>8} {"English":>10} {"Random":>10} {"Gap":>10}')
print('-' * 42)
for n, he, hr in zip(ngram_orders, english_entropies, random_entropies):
print(f'{n:>8} {float(he):>10.3f} {float(hr):>10.3f} {float(hr - he):>10.3f}')
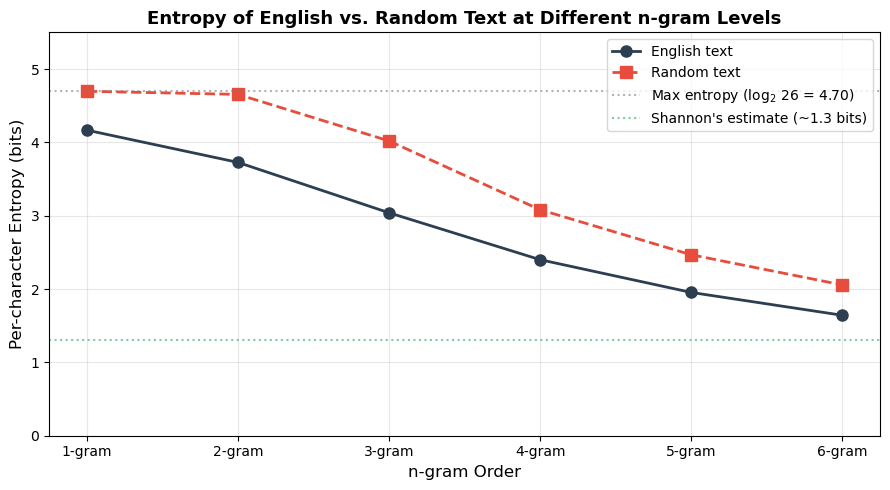
Per-character entropy estimates (bits):
n-gram English Random Gap
------------------------------------------
1 4.166 4.697 0.530
2 3.727 4.654 0.927
3 3.040 4.019 0.980
4 2.400 3.081 0.681
5 1.954 2.468 0.514
6 1.642 2.056 0.414
Observation
As the n-gram order increases, the estimated per-character entropy of English decreases substantially (from about 4.2 bits at the unigram level to below 3 bits at the 5-gram level), while random text stays near the theoretical maximum of \(\log_2 26 \approx 4.70\) bits. The gap between these curves is the redundancy that cryptanalysts exploit. Shannon estimated that accounting for all long-range correlations, the true entropy of English is roughly 1.0–1.5 bits per character.
Experiment 2: Demonstrating Perfect Secrecy#
We verify Shannon’s Theorem 13.2 by computing the mutual information \(I(P; C)\) between plaintext and ciphertext for the one-time pad. For perfect secrecy, this must be exactly zero.
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
from collections import Counter
def compute_mi_empirical(plain_ints, cipher_ints, alphabet_size):
"""
Compute empirical mutual information I(P;C) from observed
plaintext-ciphertext pairs.
"""
n = len(plain_ints)
# Build joint frequency table
joint = np.zeros((alphabet_size, alphabet_size))
for p, c in zip(plain_ints, cipher_ints):
joint[p, c] += 1
joint /= n # normalize to joint distribution
# Marginals
p_x = joint.sum(axis=1)
p_y = joint.sum(axis=0)
# Mutual information
mi = 0.0
for i in range(alphabet_size):
for j in range(alphabet_size):
if joint[i, j] > 0 and p_x[i] > 0 and p_y[j] > 0:
mi += joint[i, j] * np.log2(joint[i, j] / (p_x[i] * p_y[j]))
return mi
# --- Compare OTP, Shift cipher, and identity (no encryption) ---
rng = np.random.default_rng(42)
n_samples = 100000
mod = 26
# Non-uniform plaintext distribution (English-like)
english_freq = np.array([
8.167, 1.492, 2.782, 4.253, 12.702, 2.228, 2.015, 6.094, 6.966, 0.153,
0.772, 4.025, 2.406, 6.749, 7.507, 1.929, 0.095, 5.987, 6.327, 9.056,
2.758, 0.978, 2.360, 0.150, 1.974, 0.074
])
english_freq /= english_freq.sum()
plaintext = rng.choice(mod, size=n_samples, p=english_freq)
# 1. One-time pad (fresh random key for each character)
otp_key = rng.integers(0, mod, size=n_samples)
otp_cipher = (plaintext + otp_key) % mod
mi_otp = compute_mi_empirical(plaintext, otp_cipher, mod)
# 2. Shift cipher (single fixed key)
shift_key = 7
shift_cipher = (plaintext + shift_key) % mod
mi_shift = compute_mi_empirical(plaintext, shift_cipher, mod)
# 3. No encryption (identity)
mi_identity = compute_mi_empirical(plaintext, plaintext, mod)
# 4. Vigenere with short key
vig_key = np.array([3, 14, 3, 4]) # 'CODE'
vig_cipher = (plaintext + np.tile(vig_key, n_samples // len(vig_key) + 1)[:n_samples]) % mod
mi_vig = compute_mi_empirical(plaintext, vig_cipher, mod)
print(f'Mutual Information I(P; C):')
print(f' One-time pad: {float(mi_otp):.6f} bits (expect ~0)')
print(f' Shift cipher (k=7): {float(mi_shift):.6f} bits (expect = H(P))')
print(f' Vigenere (key=CODE): {float(mi_vig):.6f} bits')
print(f' No encryption: {float(mi_identity):.6f} bits (= H(P))')
# Plot joint distributions
fig, axes = plt.subplots(1, 3, figsize=(15, 4.5))
configs = [
('One-Time Pad', plaintext, otp_cipher, mi_otp),
('Shift Cipher (k=7)', plaintext, shift_cipher, mi_shift),
('No Encryption', plaintext, plaintext, mi_identity),
]
for ax, (title, p_arr, c_arr, mi_val) in zip(axes, configs):
joint = np.zeros((mod, mod))
for p, c in zip(p_arr, c_arr):
joint[p, c] += 1
joint /= n_samples
im = ax.imshow(joint, aspect='auto', cmap='YlOrRd', origin='lower')
ax.set_xlabel('Ciphertext letter')
ax.set_ylabel('Plaintext letter')
ax.set_title(f'{title}\nI(P;C) = {float(mi_val):.4f} bits', fontsize=11)
ax.set_xticks(range(0, 26, 5))
ax.set_yticks(range(0, 26, 5))
ax.set_xticklabels([chr(i+65) for i in range(0, 26, 5)])
ax.set_yticklabels([chr(i+65) for i in range(0, 26, 5)])
plt.colorbar(im, ax=ax, fraction=0.046)
plt.tight_layout()
plt.savefig('perfect_secrecy_mi.png', dpi=150, bbox_inches='tight')
plt.show()
Mutual Information I(P; C):
One-time pad: 0.004739 bits (expect ~0)
Shift cipher (k=7): 4.172514 bits (expect = H(P))
Vigenere (key=CODE): 2.976096 bits
No encryption: 4.172514 bits (= H(P))
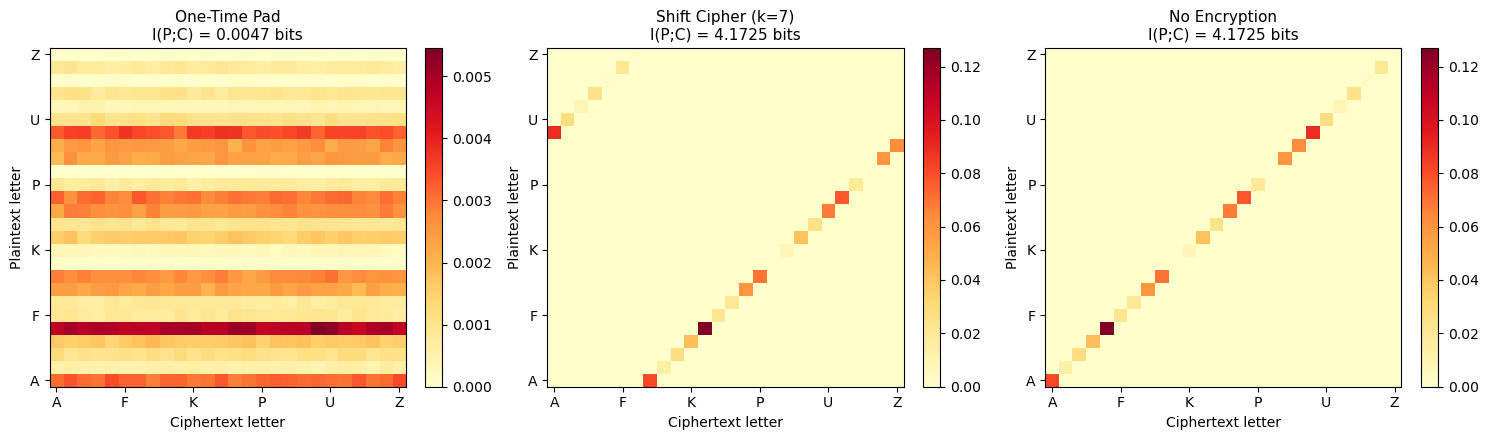
Observation
The one-time pad yields \(I(P; C) \approx 0\) (exactly zero in the infinite-sample limit), confirming perfect secrecy. The joint distribution is uniform across all ciphertext letters for each plaintext letter. In contrast, the shift cipher has \(I(P; C) = H(P)\) — the ciphertext completely determines the plaintext (given the key is fixed and known to the attacker). The Vigenere cipher leaks partial information, with the amount depending on the key length relative to the message.
Experiment 3: Unicity Distance for Various Ciphers#
We compute and compare the unicity distance for the shift, Vigenere (at several key lengths), and simple substitution ciphers, using different estimates of English redundancy.
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
import math
# Cipher key entropies (bits)
ciphers = {
'Shift': math.log2(26),
'Affine': math.log2(312),
'Vigenere (m=3)': 3 * math.log2(26),
'Vigenere (m=5)': 5 * math.log2(26),
'Vigenere (m=10)': 10 * math.log2(26),
'Vigenere (m=20)': 20 * math.log2(26),
'Substitution': math.log2(math.factorial(26)),
}
# Different redundancy estimates
R = math.log2(26) # absolute rate
entropy_estimates = {
'Unigram (4.19)': 4.19,
'Bigram (3.56)': 3.56,
'Shannon (1.3)': 1.3,
}
fig, ax = plt.subplots(figsize=(11, 6))
x = np.arange(len(ciphers))
width = 0.25
colors = ['#3498db', '#e67e22', '#2ecc71']
for i, (model_name, r_L) in enumerate(entropy_estimates.items()):
D = R - r_L
n0_values = [H_K / D for H_K in ciphers.values()]
bars = ax.bar(x + i * width, n0_values, width, label=f'D = {float(D):.2f} ({model_name})',
color=colors[i], alpha=0.85)
# Add value labels on bars
for bar, val in zip(bars, n0_values):
if val < 200:
ax.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 1,
f'{float(val):.0f}', ha='center', va='bottom', fontsize=7)
ax.set_xticks(x + width)
ax.set_xticklabels(ciphers.keys(), rotation=30, ha='right')
ax.set_ylabel('Unicity Distance $n_0$ (characters)', fontsize=12)
ax.set_title('Unicity Distance $n_0 = H(K) / D$ for Various Ciphers',
fontsize=13, fontweight='bold')
ax.legend(fontsize=9, loc='upper left')
ax.grid(True, axis='y', alpha=0.3)
ax.set_ylim(0, max(math.log2(math.factorial(26)) / (R - 4.19),
math.log2(math.factorial(26)) / (R - 1.3)) * 1.15)
plt.tight_layout()
plt.savefig('unicity_distance_comparison.png', dpi=150, bbox_inches='tight')
plt.show()
# Table output
print(f'\nUnicity distances (using Shannon\'s D = {float(R - 1.3):.2f} bits/char):')
print(f'{"Cipher":<22} {"H(K) bits":>10} {"n_0 (chars)":>12}')
print('=' * 48)
D_shannon = R - 1.3
for name, H_K in ciphers.items():
n0 = H_K / D_shannon
print(f'{name:<22} {float(H_K):>10.1f} {float(n0):>12.1f}')
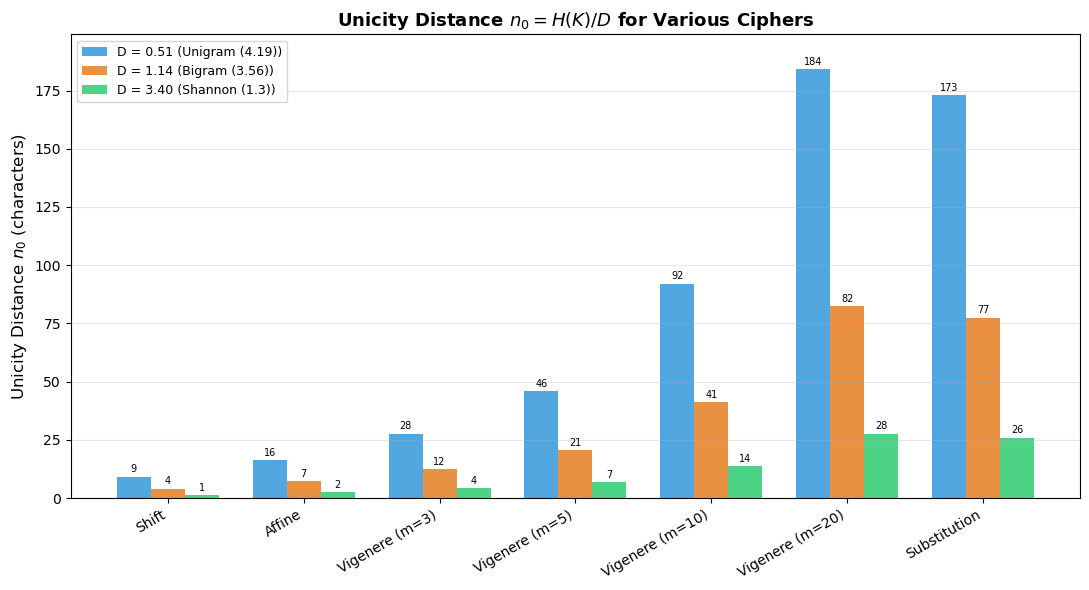
Unicity distances (using Shannon's D = 3.40 bits/char):
Cipher H(K) bits n_0 (chars)
================================================
Shift 4.7 1.4
Affine 8.3 2.4
Vigenere (m=3) 14.1 4.1
Vigenere (m=5) 23.5 6.9
Vigenere (m=10) 47.0 13.8
Vigenere (m=20) 94.0 27.6
Substitution 88.4 26.0
Experiment 4: Spurious Keys vs. Ciphertext Length#
We plot the expected number of spurious keys — keys that decrypt the ciphertext to plausible-looking (but incorrect) plaintext — as a function of ciphertext length. When the spurious key count drops to zero, we have reached the unicity distance.
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
import math
def expected_spurious_keys(key_space_size, n, D):
"""
E[spurious keys] ~ |K| * 2^{-nD} - 1
"""
exponent = -n * D
# Avoid overflow: compute in log space if needed
log2_result = np.log2(float(key_space_size)) + exponent / np.log(2) * np.log(2)
# Actually: log2(|K| * 2^{-nD}) = log2(|K|) - nD
log2_result = np.log2(float(key_space_size)) - n * D
return np.maximum(0.0, 2.0 ** log2_result - 1)
D = np.log2(26) - 1.3 # Shannon's redundancy estimate
# Ciphertext lengths to plot
n_values = np.linspace(1, 100, 500)
cipher_configs = [
('Shift (|K|=26)', 26, '#e74c3c'),
('Vigenere m=5 (|K|=26$^5$)', 26**5, '#3498db'),
('Vigenere m=10 (|K|=26$^{10}$)', 26**10, '#e67e22'),
('Substitution (|K|=26!)', math.factorial(26), '#2ecc71'),
]
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
# Left: log scale
for name, K_size, color in cipher_configs:
spurious = expected_spurious_keys(K_size, n_values, D)
# Replace 0 with NaN for log plot
spurious_log = np.where(spurious > 0, spurious, np.nan)
axes[0].semilogy(n_values, spurious_log, label=name, color=color, linewidth=2)
# Mark unicity distance
n0 = np.log2(float(K_size)) / D
axes[0].axvline(x=n0, color=color, linestyle=':', alpha=0.5)
axes[0].axhline(y=1, color='black', linestyle='--', alpha=0.3, label='1 spurious key')
axes[0].set_xlabel('Ciphertext Length $n$ (characters)', fontsize=11)
axes[0].set_ylabel('Expected Spurious Keys (log scale)', fontsize=11)
axes[0].set_title('Spurious Keys vs. Ciphertext Length', fontsize=12, fontweight='bold')
axes[0].legend(fontsize=8, loc='upper right')
axes[0].grid(True, alpha=0.3)
axes[0].set_xlim(0, 100)
# Right: linear scale, zoomed into substitution cipher region
n_sub = np.linspace(1, 50, 500)
K_sub = math.factorial(26)
spurious_sub = expected_spurious_keys(K_sub, n_sub, D)
n0_sub = math.log2(K_sub) / D
axes[1].plot(n_sub, np.log10(spurious_sub + 1), color='#2ecc71', linewidth=2)
axes[1].axvline(x=n0_sub, color='red', linestyle='--', alpha=0.7,
label=f'Unicity distance $n_0$ = {float(n0_sub):.1f}')
axes[1].set_xlabel('Ciphertext Length $n$ (characters)', fontsize=11)
axes[1].set_ylabel('$\\log_{10}$(Spurious Keys + 1)', fontsize=11)
axes[1].set_title('Substitution Cipher: Spurious Key Decay', fontsize=12, fontweight='bold')
axes[1].legend(fontsize=10)
axes[1].grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('spurious_keys_vs_length.png', dpi=150, bbox_inches='tight')
plt.show()
# Print unicity distances
print(f'Unicity distances (D = {float(D):.2f} bits/char):')
for name, K_size, _ in cipher_configs:
n0 = np.log2(float(K_size)) / D
print(f' {name:<40} n_0 = {float(n0):>6.1f} chars')
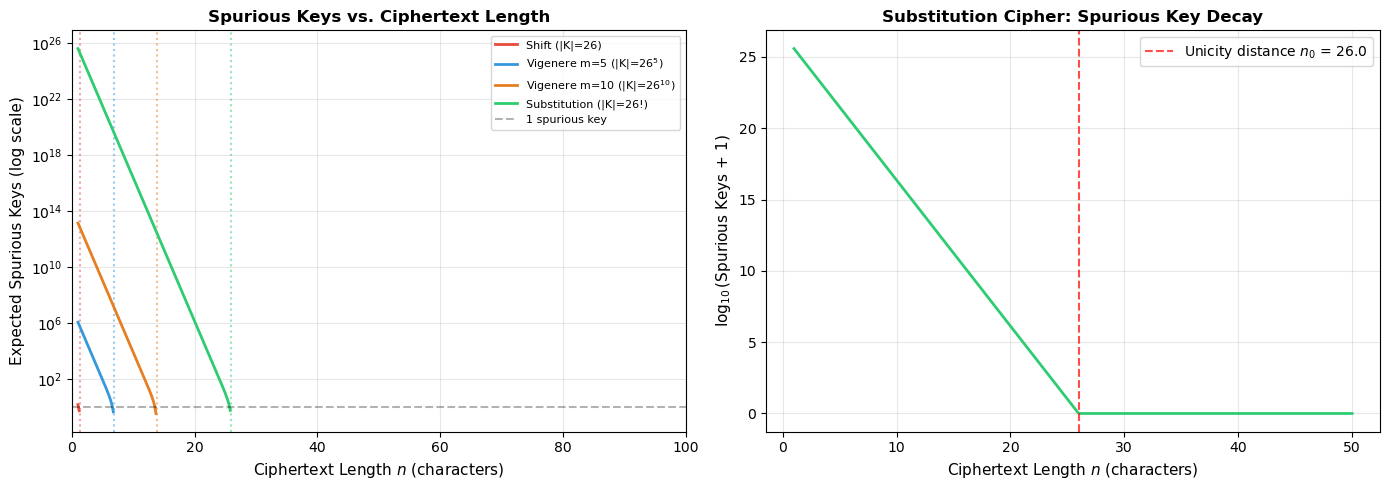
Unicity distances (D = 3.40 bits/char):
Shift (|K|=26) n_0 = 1.4 chars
Vigenere m=5 (|K|=26$^5$) n_0 = 6.9 chars
Vigenere m=10 (|K|=26$^{10}$) n_0 = 13.8 chars
Substitution (|K|=26!) n_0 = 26.0 chars
Observation
The spurious key count decays exponentially with ciphertext length at rate \(D\) (the language redundancy). Even for the simple substitution cipher with its astronomical key space of \(26! \approx 4 \times 10^{26}\), the unicity distance is only about 25 characters — roughly one line of text. This explains why substitution ciphers are breakable from short messages: the English language contains so much redundancy that the key is effectively overdetermined.
13.6 Exercises#
Exercise 13.1 (Warm-up)#
Compute the entropy \(H(X)\) of the following probability distributions:
\(P = (1/4, 1/4, 1/4, 1/4)\)
\(P = (1/2, 1/4, 1/8, 1/8)\)
\(P = (1, 0, 0, 0)\)
Which distribution has the highest entropy? Which has the lowest? Explain why.
Hint
Use \(H(X) = -\sum p(x) \log_2 p(x)\). For (1): all outcomes equally likely gives maximum entropy \(H = \log_2 4 = 2\) bits. For (3): a deterministic distribution has \(H = 0\) bits. Entropy is maximized by the uniform distribution.
Exercise 13.2 (Applied)#
Write code to verify experimentally that the one-time pad provides perfect secrecy for binary strings. Generate 50,000 random binary plaintexts of length 8, encrypt each with a fresh random key, and compute the empirical mutual information \(I(P; C)\). Compare with the shift cipher using a fixed key.
Hint
Work with mod=2 and length-8 strings. For the OTP, the key is 8 fresh random
bits per message. For the shift cipher analog in binary (XOR with a fixed key),
the ciphertext is fully determined by the plaintext, so \(I(P;C) = H(P)\).
Compute MI by building the joint frequency table over all character positions.
Exercise 13.3 (Analysis)#
The Vigenere cipher with key length \(m\) has key entropy \(H(K) = m \log_2 26\). Derive the unicity distance as a function of \(m\) and English redundancy \(D\). At what key length \(m\) does the unicity distance exceed 1000 characters?
Hint
\(n_0 = m \cdot \log_2(26) / D\). Using \(D \approx 3.4\) bits/char: \(n_0 > 1000\) requires \(m > 1000 \cdot 3.4 / 4.7 \approx 723\). When \(m\) equals the message length, we have a one-time pad and \(n_0 \to \infty\).
Exercise 13.4 (Theory)#
Prove that for any cryptosystem with perfect secrecy, \(H(K) \geq H(P)\). That is, the key must carry at least as much entropy as the plaintext.
(This is a strengthening of Theorem 13.1 from key space size to key entropy.)
Hint
Start with \(H(K) \geq H(K \mid C) = H(K, P \mid C) - H(P \mid C)\). Perfect secrecy gives \(H(P \mid C) = H(P)\), and \(H(K, P \mid C) \geq H(P \mid C)\) since the key and plaintext together determine the ciphertext. Use the chain rule: \(H(K \mid C) \geq H(P \mid C) = H(P)\). Since \(H(K) \geq H(K \mid C)\) (conditioning cannot increase entropy), we get \(H(K) \geq H(P)\).
Exercise 13.5 (Challenge)#
Implement a simulation of the spurious key phenomenon for the shift cipher. For each ciphertext length \(n\) from 1 to 30:
Generate 1000 random English-like plaintexts of length \(n\) (using letter frequencies).
Encrypt each with a random shift.
For each ciphertext, try all 26 keys and count how many produce text whose letter frequencies are “plausible” (e.g., chi-squared statistic below a threshold).
Plot the average number of plausible keys vs. \(n\) and compare with the theoretical formula \(|K| \cdot 2^{-nD}\).
Hint
For the plausibility test, compute \(\chi^2 = \sum_i (O_i - E_i)^2 / E_i\) where \(O_i\) are observed counts and \(E_i\) are expected counts from English frequencies. Use a threshold around 40–60 for a 26-letter alphabet. At short lengths, many keys will produce plausible output (spurious keys); at longer lengths, only the correct key (and possibly one or two others) will pass the test.
13.7 Summary#
Concept |
Key Point |
|---|---|
Cryptosystem |
Formal five-tuple \((\mathcal{P}, \mathcal{C}, \mathcal{K}, E, D)\) |
Perfect secrecy |
\(\Pr[P = p \mid C = c] = \Pr[P = p]\); ciphertext reveals nothing |
Shannon entropy |
\(H(X) = -\sum p(x) \log_2 p(x)\); average uncertainty in bits |
Mutual information |
\(I(P; C) = 0\) iff perfect secrecy |
Shannon’s theorem |
Perfect secrecy requires \(\lvert\mathcal{K}\rvert \geq \lvert\mathcal{P}\rvert\) |
One-time pad |
Achieves perfect secrecy with key as long as the message |
Language redundancy |
English: \(D \approx 3.2\)–3.7 bits/char; enables cryptanalysis |
Unicity distance |
\(n_0 = H(K) / D\); ciphertext needed to uniquely determine the key |
Spurious keys |
\(\approx \lvert\mathcal{K}\rvert \cdot 2^{-nD} - 1\); decay exponentially with ciphertext length |
Tip
Shannon’s framework reveals a fundamental tension in cryptography: unconditional security (perfect secrecy) requires impractically long keys, while practical ciphers with short keys inevitably leak information. This tension motivated the shift from information-theoretic security to computational security — the foundation of modern cryptography, where we rely on problems being hard to solve rather than impossible.
References#
Shannon, C. E. (1949). “Communication Theory of Secrecy Systems.” Bell System Technical Journal, 28(4), 656–715. The foundational paper that created the information-theoretic study of cryptographic security. Introduces perfect secrecy, unicity distance, and proves the one-time pad theorem. [6]
Shannon, C. E. (1948). “A Mathematical Theory of Communication.” Bell System Technical Journal, 27(3), 379–423. The paper that launched information theory, defining entropy and establishing the fundamental limits of data compression and communication. [7]
Kerckhoffs, A. (1883). “La cryptographie militaire.” Journal des sciences militaires, 9, 5–38. The classic formulation of Kerckhoffs’ principle: a cipher should remain secure even if everything about the system, except the key, is public knowledge. [8]
Stinson, D. R. and Paterson, M. (2018). Cryptography: Theory and Practice, 4th ed. CRC Press. Chapter 2 provides a modern textbook treatment of Shannon’s theory, including detailed proofs of the perfect secrecy theorems.
Cover, T. M. and Thomas, J. A. (2006). Elements of Information Theory, 2nd ed. Wiley. The standard graduate reference for information theory, with applications to cryptography in Chapter 16.
Singh, S. (1999). The Code Book. Doubleday. An accessible historical account including Shannon’s contributions and the story of the VENONA project. [3]