
Chapter 5: The Vigenère Cipher and Kasiski Examination#
“A polyalphabetic cipher renders frequency analysis powerless — until one discovers the period.”
In the previous chapters we saw how monoalphabetic substitution ciphers are fundamentally vulnerable to frequency analysis: each plaintext letter is always mapped to the same ciphertext letter, so the statistical signature of the underlying language shines through. The Vigenère cipher was designed to defeat exactly this attack by cycling through multiple substitution alphabets, and for nearly three centuries it was considered unbreakable. In this chapter we study its design, formalize the notion of polyalphabetic substitution, and then demonstrate how Kasiski examination — a technique that exploits repeated patterns in ciphertext — recovers the key length and ultimately breaks the cipher.
5.1 Historical Background#
5.1.1 Blaise de Vigenère and “Le Chiffre Indéchiffrable”#
The idea of using multiple cipher alphabets dates back to Leon Battista Alberti (c. 1467), but it was Blaise de Vigenère who, in his 1586 Traité des chiffres, described the mature form of the cipher that now bears his name. Earlier, in 1553, Giovan Battista Bellaso had published a similar scheme, and the attribution to Vigenère is historically debated. Nevertheless, the cipher became known as the Vigenère cipher and earned the reputation of “le chiffre indéchiffrable” — the indecipherable cipher.
The cipher’s strength lies in its polyalphabetic nature: rather than applying one fixed substitution, it cycles through \(L\) different Caesar shifts determined by a keyword of length \(L\). This flattens the frequency distribution of the ciphertext, making single-letter frequency analysis ineffective.
5.1.2 Babbage and Kasiski#
The Vigenère cipher resisted cryptanalysis for roughly 300 years. The first known break was accomplished by Charles Babbage around 1846, but he never published his work (possibly because the British government wished to keep the method secret during the Crimean War). Independently, the Prussian infantry officer Friedrich Wilhelm Kasiski published essentially the same technique in his 1863 book Die Geheimschriften und die Dechiffrir-Kunst (“Secret Writing and the Art of Deciphering”). The method is now universally known as the Kasiski examination.
Historical Note
Babbage’s unpublished notes, discovered much later, show he had cracked the Vigenère cipher as early as 1846 — seventeen years before Kasiski’s publication. This is one of several instances in the history of cryptanalysis where classified intelligence work anticipated published academic results.
5.2 Formal Definitions#
5.2.1 Polyalphabetic vs. Monoalphabetic Substitution#
Recall that a monoalphabetic substitution cipher uses a single permutation \(\pi: \mathbb{Z}_{26} \to \mathbb{Z}_{26}\) to encrypt every letter:
A polyalphabetic substitution cipher uses a family of permutations \(\{\pi_0, \pi_1, \ldots, \pi_{L-1}\}\), cycling through them with period \(L\):
The key distinction is that the same plaintext letter can map to different ciphertext letters depending on its position, which disrupts the frequency signature.
5.2.2 The Vigenère Cipher#
The Vigenère cipher is the special case where each \(\pi_j\) is a Caesar shift by \(k_j\):
Definition 5.1 (Vigenère Cipher)
Let \(\mathbf{k} = (k_0, k_1, \ldots, k_{L-1}) \in \mathbb{Z}_{26}^L\) be a key of length \(L\). The Vigenère encryption of a plaintext message \(\mathbf{m} = (m_0, m_1, \ldots, m_{n-1})\) is:
and decryption is:
Equivalently, we can think of the keyword as a string of letters (e.g., ENIGMA corresponds to \(\mathbf{k} = (4, 13, 8, 6, 12, 0)\)), and the encryption shifts each plaintext letter by the corresponding keyword letter.
5.2.3 The Kasiski Examination#
The Kasiski examination exploits the following observation: if the same plaintext trigram (or any \(n\)-gram) appears at two positions whose distance is a multiple of the key length \(L\), then it will be encrypted to the same ciphertext trigram. We can therefore search for repeated \(n\)-grams in the ciphertext, compute the distances between their occurrences, and take the GCD of those distances to estimate \(L\).
Definition 5.2 (Kasiski Examination)
Given a ciphertext \(\mathbf{c}\), the Kasiski examination proceeds as follows:
Find all repeated \(n\)-grams (typically trigrams, \(n=3\)) in \(\mathbf{c}\).
For each repeated \(n\)-gram, compute the distances between all pairs of occurrences.
Compute the GCD of these distances. The result is likely a multiple of (or equal to) the key length \(L\).
5.3 Key Theoretical Results#
Theorem 5.1 (Kasiski’s Observation)
Let \(\mathbf{m}\) be a plaintext and \(\mathbf{k}\) a Vigenère key of length \(L\). If a trigram \(m_i m_{i+1} m_{i+2}\) appears again at position \(j\) (i.e., \(m_j m_{j+1} m_{j+2} = m_i m_{i+1} m_{i+2}\)) and \(L \mid (j - i)\), then the corresponding ciphertext trigrams are identical:
Proof. Since \(L \mid (j - i)\), we have \((j + r) \bmod L = (i + r) \bmod L\) for \(r = 0, 1, 2\). Therefore:
Corollary 5.1
The GCD of the distances between repeated ciphertext trigrams is likely a multiple of the key length \(L\). In practice, with sufficiently long ciphertext, the GCD often equals \(L\) exactly.
Caveat
Not every repeated ciphertext trigram arises from a repeated plaintext trigram at a distance divisible by \(L\). Coincidental repeats can occur. However, with longer ciphertext and more repeated \(n\)-grams, the statistical signal of the true key length dominates.
5.4 Implementation#
5.4.1 The VigenereCipher Class#
import numpy as np
class VigenereCipher:
"""Vigenere cipher: encrypt and decrypt using a repeating keyword."""
def __init__(self, key: str):
"""
Parameters
----------
key : str
Keyword consisting of lowercase letters a-z.
"""
self.key = key.lower()
self.key_ints = np.array([ord(ch) - ord('a') for ch in self.key])
self.L = len(self.key_ints)
def _clean(self, text: str) -> str:
"""Remove all non-lowercase-letter characters."""
return ''.join(ch for ch in text.lower() if 'a' <= ch <= 'z')
def encrypt(self, plaintext: str) -> str:
"""Encrypt plaintext with Vigenere cipher."""
plain = self._clean(plaintext)
plain_ints = np.array([ord(ch) - ord('a') for ch in plain])
# Build full-length key stream
key_stream = np.tile(self.key_ints, len(plain_ints) // self.L + 1)[:len(plain_ints)]
cipher_ints = (plain_ints + key_stream) % 26
return ''.join(chr(v + ord('a')) for v in cipher_ints)
def decrypt(self, ciphertext: str) -> str:
"""Decrypt ciphertext with Vigenere cipher."""
cipher = self._clean(ciphertext)
cipher_ints = np.array([ord(ch) - ord('a') for ch in cipher])
key_stream = np.tile(self.key_ints, len(cipher_ints) // self.L + 1)[:len(cipher_ints)]
plain_ints = (cipher_ints - key_stream) % 26
return ''.join(chr(v + ord('a')) for v in plain_ints)
def __repr__(self):
return f"VigenereCipher(key='{self.key}', L={self.L})"
# Quick test
vc = VigenereCipher("enigma")
print(f"Cipher: {vc}")
ct = vc.encrypt("hello world this is a test")
pt = vc.decrypt(ct)
print(f"Plaintext: helloworldthisisatest")
print(f"Ciphertext: {ct}")
print(f"Decrypted: {pt}")
assert pt == "helloworldthisisatest", "Decryption failed!"
print("Encrypt/Decrypt round-trip: OK")
Cipher: VigenereCipher(key='enigma', L=6)
Plaintext: helloworldthisisatest
Ciphertext: lrtrawsetjfhmfqymtifb
Decrypted: helloworldthisisatest
Encrypt/Decrypt round-trip: OK
5.4.2 The KasiskiExamination Class#
import numpy as np
from math import gcd
from functools import reduce
from collections import defaultdict
class KasiskiExamination:
"""Kasiski examination: find repeated n-grams, compute distances,
and suggest key lengths via GCD analysis."""
def __init__(self, ciphertext: str):
self.ciphertext = ''.join(ch for ch in ciphertext.lower() if 'a' <= ch <= 'z')
def find_repeated_ngrams(self, n: int = 3) -> dict:
"""
Find all n-grams that appear more than once.
Returns
-------
dict : {ngram: [list of starting positions]}
"""
ngram_positions = defaultdict(list)
for i in range(len(self.ciphertext) - n + 1):
ngram = self.ciphertext[i:i + n]
ngram_positions[ngram].append(i)
# Keep only repeated n-grams
return {ng: pos for ng, pos in ngram_positions.items() if len(pos) > 1}
def compute_distances(self, n: int = 3) -> list:
"""
Compute all pairwise distances between repeated n-gram occurrences.
Returns
-------
list of int : sorted list of distances
"""
repeated = self.find_repeated_ngrams(n)
distances = []
for ngram, positions in repeated.items():
for i in range(len(positions)):
for j in range(i + 1, len(positions)):
distances.append(positions[j] - positions[i])
return sorted(distances)
def suggest_key_lengths(self, n: int = 3, max_length: int = 20) -> list:
"""
Suggest likely key lengths by factoring all distances and
counting factor frequencies.
Returns
-------
list of (factor, count) sorted by count descending
"""
distances = self.compute_distances(n)
if not distances:
return []
factor_counts = defaultdict(int)
for d in distances:
for f in range(2, min(d, max_length) + 1):
if d % f == 0:
factor_counts[f] += 1
return sorted(factor_counts.items(), key=lambda x: x[1], reverse=True)
def gcd_of_distances(self, n: int = 3) -> int:
"""
Compute GCD of all pairwise distances between repeated n-grams.
"""
distances = self.compute_distances(n)
if not distances:
return 0
return reduce(gcd, distances)
# Quick test
print("KasiskiExamination class loaded.")
KasiskiExamination class loaded.
5.5 Experiments#
Experiment 1: Frequency Analysis Fails Against Vigenère#
We encrypt a long English text with a Vigenère cipher (key length 5) and show that the single-letter frequency distribution of the ciphertext is nearly flat — far from the distinctive shape of English.
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
# --- Long English plaintext ---
long_text = (
"Ciphers oh ciphers secrets they keep locked away in code deep and discreet "
"symbols and numbers jumbled and mixed a message encoded ready to be fixed "
"through history they have been used to hide plans of war love letters beside "
"the Rosetta Stone a mystery solved a codebreakers work duly evolved "
"from Caesar to Enigma through time they change yet the essence remains "
"mysterious and strange a puzzle to solve a game to play a message to decipher "
"in every way crack the code reveal the truth a challenge to minds sharp and "
"astute for ciphers oh ciphers they hold the key to secrets untold waiting to "
"be set free deep within the caves so dark and cold the dwarves they sat and "
"stories told of treasure hoards and ancient lore and secrets kept for evermore "
"but in their hands they held a tool a wondrous thing so sharp and cool "
"a blade of steel that could carve letters and keep their secrets safe forever "
"they used this tool to write their code a cipher strong that none could decode "
"for every letter they would add another from their secret pad the Vigenere "
"cipher was their art a thing of beauty a thing apart for only those who held "
"the key could read the messages meant to be and so they wrote in cryptic lines "
"their secrets safe from prying eyes for only those who knew the code could "
"ever hope to share the load and though the world may never know the secrets "
"kept so long ago the dwarves will always have their craft the Vigenere cipher "
"strong and steadfast"
)
# Clean the text
def clean_text(text):
"""Remove non-letter characters and convert to lowercase."""
return ''.join(ch for ch in text.lower() if 'a' <= ch <= 'z')
plaintext = clean_text(long_text)
print(f"Plaintext length: {len(plaintext)} characters")
# Encrypt with key length 5
key = "flame" # length 5
key_ints = np.array([ord(ch) - ord('a') for ch in key])
plain_ints = np.array([ord(ch) - ord('a') for ch in plaintext])
key_stream = np.tile(key_ints, len(plain_ints) // len(key_ints) + 1)[:len(plain_ints)]
cipher_ints = (plain_ints + key_stream) % 26
ciphertext = ''.join(chr(v + ord('a')) for v in cipher_ints)
print(f"Key: '{key}' (length {len(key)})")
print(f"Ciphertext (first 80 chars): {ciphertext[:80]}")
# --- Frequency analysis ---
alphabet = 'abcdefghijklmnopqrstuvwxyz'
english_freq = np.array([
0.0817, 0.0150, 0.0278, 0.0425, 0.1270, 0.0223, 0.0202, 0.0609, 0.0697,
0.0015, 0.0077, 0.0403, 0.0241, 0.0675, 0.0751, 0.0193, 0.0010, 0.0599,
0.0633, 0.0906, 0.0276, 0.0098, 0.0236, 0.0015, 0.0197, 0.0007
])
def letter_frequencies(text):
"""Compute letter frequency distribution."""
counts = np.array([text.count(ch) for ch in alphabet])
return counts / len(text) if len(text) > 0 else counts
plain_freq = letter_frequencies(plaintext)
cipher_freq = letter_frequencies(ciphertext)
fig, axes = plt.subplots(1, 3, figsize=(16, 4.5))
x = np.arange(26)
axes[0].bar(x, english_freq, color='steelblue', alpha=0.8)
axes[0].set_xticks(x)
axes[0].set_xticklabels(list(alphabet))
axes[0].set_title('Standard English Frequencies')
axes[0].set_ylabel('Relative frequency')
axes[1].bar(x, plain_freq, color='forestgreen', alpha=0.8)
axes[1].set_xticks(x)
axes[1].set_xticklabels(list(alphabet))
axes[1].set_title('Plaintext Frequencies')
axes[2].bar(x, cipher_freq, color='firebrick', alpha=0.8)
axes[2].set_xticks(x)
axes[2].set_xticklabels(list(alphabet))
axes[2].set_title('Vigen\u00e8re Ciphertext Frequencies')
plt.tight_layout()
plt.savefig('fig_ch05_freq_comparison.png', dpi=150, bbox_inches='tight')
plt.show()
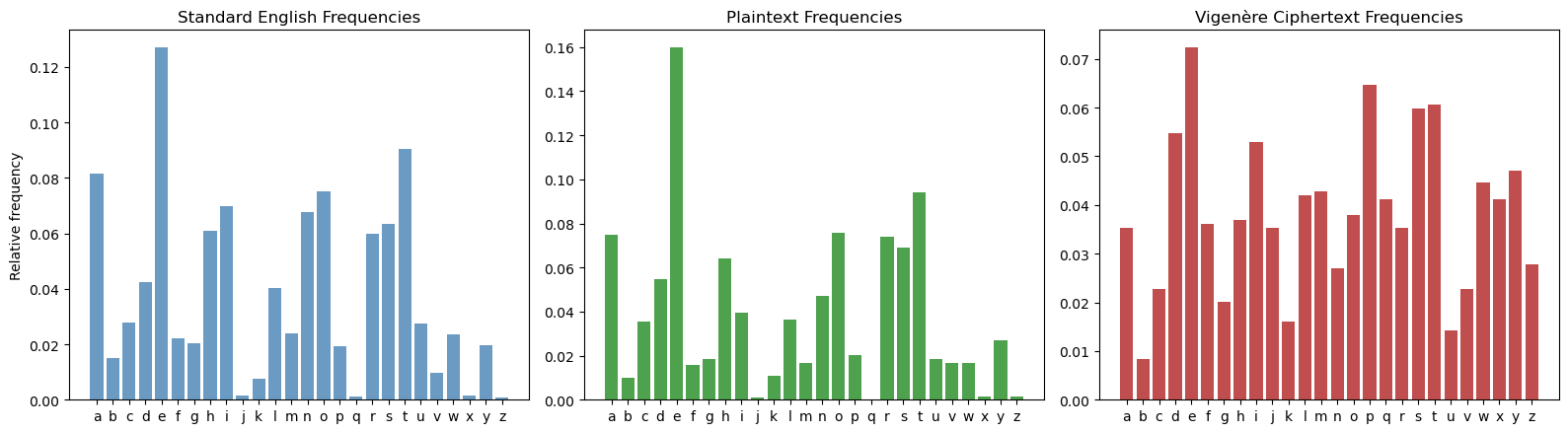
print(f"\nPlaintext max frequency: {float(plain_freq.max()):.4f} (letter '{alphabet[plain_freq.argmax()]}')")
print(f"Ciphertext max frequency: {float(cipher_freq.max()):.4f} (letter '{alphabet[cipher_freq.argmax()]}')")
print(f"Ciphertext std dev: {float(cipher_freq.std()):.4f}")
print(f"Plaintext std dev: {float(plain_freq.std()):.4f}")
print("\nThe ciphertext frequencies are much flatter -- frequency analysis fails!")
Plaintext length: 1189 characters
Key: 'flame' (length 5)
Ciphertext (first 80 chars): htptiwdotgnahqvxdeovjesfljjkqiuwooojoaiedtnosipdqiulnphndcdijeskqgzleesongqgpren
Plaintext max frequency: 0.1598 (letter 'e')
Ciphertext max frequency: 0.0723 (letter 'e')
Ciphertext std dev: 0.0158
Plaintext std dev: 0.0362
The ciphertext frequencies are much flatter -- frequency analysis fails!
Observation
The Vigenère ciphertext has a much flatter frequency distribution than the plaintext. The standard deviation of ciphertext letter frequencies is roughly half that of plaintext frequencies, making it impossible to identify individual letters by frequency alone.
Experiment 2: Kasiski Examination Recovers the Key Length#
We now apply the Kasiski examination to the ciphertext. We find repeated trigrams, compute distances between their occurrences, and show that the GCD of these distances reveals the key length.
import numpy as np
from math import gcd
from functools import reduce
from collections import defaultdict
class KasiskiExamination:
"""Kasiski examination: find repeated n-grams, compute distances,
and suggest key lengths via GCD and factor analysis."""
def __init__(self, ciphertext: str):
self.ciphertext = ''.join(ch for ch in ciphertext.lower() if 'a' <= ch <= 'z')
def find_repeated_ngrams(self, n: int = 3) -> dict:
ngram_positions = defaultdict(list)
for i in range(len(self.ciphertext) - n + 1):
ngram = self.ciphertext[i:i + n]
ngram_positions[ngram].append(i)
return {ng: pos for ng, pos in ngram_positions.items() if len(pos) > 1}
def compute_distances(self, n: int = 3) -> list:
repeated = self.find_repeated_ngrams(n)
distances = []
for ngram, positions in repeated.items():
for i in range(len(positions)):
for j in range(i + 1, len(positions)):
distances.append(positions[j] - positions[i])
return sorted(distances)
def suggest_key_lengths(self, n: int = 3, max_length: int = 20) -> list:
distances = self.compute_distances(n)
if not distances:
return []
factor_counts = defaultdict(int)
for d in distances:
for f in range(2, min(d, max_length) + 1):
if d % f == 0:
factor_counts[f] += 1
return sorted(factor_counts.items(), key=lambda x: x[1], reverse=True)
def gcd_of_distances(self, n: int = 3) -> int:
distances = self.compute_distances(n)
if not distances:
return 0
return reduce(gcd, distances)
# Apply Kasiski examination to our ciphertext
kasiski = KasiskiExamination(ciphertext)
# --- Find repeated trigrams ---
repeated_trigrams = kasiski.find_repeated_ngrams(3)
print(f"Number of repeated trigrams: {len(repeated_trigrams)}")
print("\nSample repeated trigrams and their positions:")
for i, (trigram, positions) in enumerate(sorted(repeated_trigrams.items(),
key=lambda x: len(x[1]),
reverse=True)):
if i >= 10:
break
dists = [positions[j] - positions[i_]
for i_ in range(len(positions))
for j in range(i_ + 1, len(positions))]
print(f" '{trigram}': positions={positions}, distances={dists}")
# --- Compute all distances and their GCD ---
all_distances = kasiski.compute_distances(3)
overall_gcd = kasiski.gcd_of_distances(3)
print(f"\nTotal number of distances: {len(all_distances)}")
print(f"GCD of all trigram distances: {overall_gcd}")
print(f"Actual key length: {len(key)}")
# --- Factor frequency analysis ---
suggestions = kasiski.suggest_key_lengths(3, max_length=15)
print("\nKey length suggestions (factor, count):")
for factor, count in suggestions[:8]:
marker = " <-- TRUE KEY LENGTH" if factor == len(key) else ""
print(f" L = {int(factor):2d}: appears as factor {int(count):3d} times{marker}")
Number of repeated trigrams: 140
Sample repeated trigrams and their positions:
'yse': positions=[285, 380, 474, 620, 630, 735, 850, 870, 985, 1120], distances=[95, 189, 335, 345, 450, 565, 585, 700, 835, 94, 240, 250, 355, 470, 490, 605, 740, 146, 156, 261, 376, 396, 511, 646, 10, 115, 230, 250, 365, 500, 105, 220, 240, 355, 490, 115, 135, 250, 385, 20, 135, 270, 115, 250, 135]
'tti': positions=[137, 272, 712, 922, 937, 962, 1077, 1097], distances=[135, 575, 785, 800, 825, 940, 960, 440, 650, 665, 690, 805, 825, 210, 225, 250, 365, 385, 15, 40, 155, 175, 25, 140, 160, 115, 135, 20]
'flj': positions=[23, 393, 508, 758, 813, 828], distances=[370, 485, 735, 790, 805, 115, 365, 420, 435, 250, 305, 320, 55, 70, 15]
'xmp': positions=[459, 529, 539, 1034, 1144, 1154], distances=[70, 80, 575, 685, 695, 10, 505, 615, 625, 495, 605, 615, 110, 120, 10]
'lnp': positions=[51, 86, 546, 576, 626], distances=[35, 495, 525, 575, 460, 490, 540, 30, 80, 50]
'nah': positions=[10, 360, 445, 511], distances=[350, 435, 501, 85, 151, 66]
'hqv': positions=[12, 187, 362, 447], distances=[175, 350, 435, 175, 260, 85]
'ehq': positions=[186, 451, 836, 1061], distances=[265, 650, 875, 385, 610, 225]
'azh': positions=[312, 522, 957, 1177], distances=[210, 645, 865, 435, 655, 220]
'htp': positions=[0, 435, 1165], distances=[435, 1165, 730]
Total number of distances: 326
GCD of all trigram distances: 1
Actual key length: 5
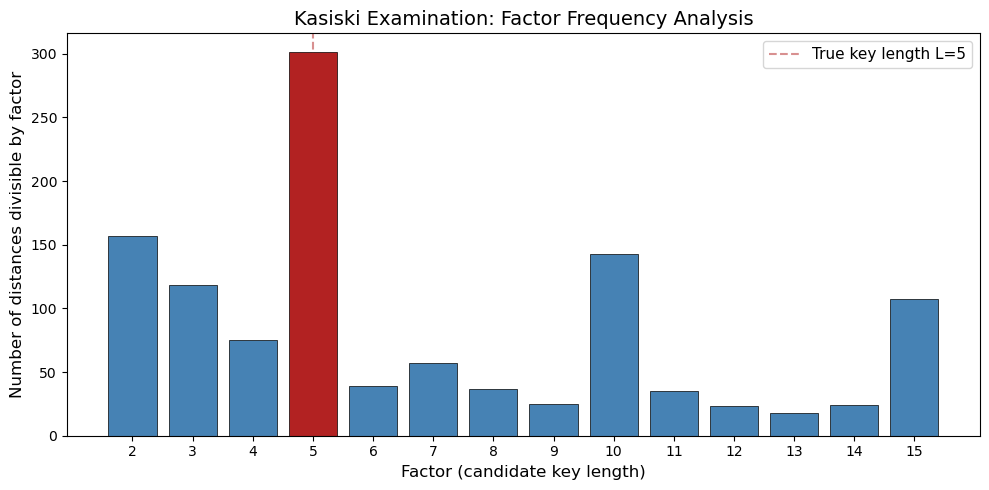
Key length suggestions (factor, count):
L = 5: appears as factor 301 times <-- TRUE KEY LENGTH
L = 2: appears as factor 157 times
L = 10: appears as factor 143 times
L = 3: appears as factor 118 times
L = 15: appears as factor 107 times
L = 4: appears as factor 75 times
L = 7: appears as factor 57 times
L = 6: appears as factor 39 times
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
from collections import defaultdict
# Visualize factor frequency
# Recompute suggestions for visualization
def compute_factor_counts(distances, max_length=15):
factor_counts = defaultdict(int)
for d in distances:
for f in range(2, min(d, max_length) + 1):
if d % f == 0:
factor_counts[f] += 1
return dict(sorted(factor_counts.items()))
factor_counts = compute_factor_counts(all_distances, max_length=15)
fig, ax = plt.subplots(figsize=(10, 5))
factors = list(factor_counts.keys())
counts = list(factor_counts.values())
colors = ['firebrick' if f == len(key) else 'steelblue' for f in factors]
ax.bar(factors, counts, color=colors, edgecolor='black', linewidth=0.5)
ax.set_xlabel('Factor (candidate key length)', fontsize=12)
ax.set_ylabel('Number of distances divisible by factor', fontsize=12)
ax.set_title('Kasiski Examination: Factor Frequency Analysis', fontsize=14)
ax.set_xticks(factors)
ax.axvline(x=len(key), color='firebrick', linestyle='--', alpha=0.5,
label=f'True key length L={len(key)}')
ax.legend(fontsize=11)
plt.tight_layout()
plt.savefig('fig_ch05_kasiski_factors.png', dpi=150, bbox_inches='tight')
plt.show()
print("The true key length (red bar) has the highest or near-highest factor count.")
The true key length (red bar) has the highest or near-highest factor count.
Experiment 3: Splitting Ciphertext into \(L\) Streams#
Once the key length \(L\) is known (or guessed), we can split the ciphertext into \(L\) independent streams. Stream \(j\) consists of every \(L\)-th character starting from position \(j\):
Each stream has been encrypted with a single Caesar shift \(k_j\), so we can apply frequency analysis to each stream independently.
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
# Split ciphertext into L=5 streams
L = 5 # key length from Kasiski examination
alphabet = 'abcdefghijklmnopqrstuvwxyz'
streams = []
for j in range(L):
stream = ciphertext[j::L] # every L-th character starting from j
streams.append(stream)
print(f"Ciphertext length: {len(ciphertext)}")
print(f"Key length L = {L}")
for j, s in enumerate(streams):
print(f" Stream {j}: {len(s)} chars, first 30: '{s[:30]}'")
# Frequency analysis on each stream
english_freq = np.array([
0.0817, 0.0150, 0.0278, 0.0425, 0.1270, 0.0223, 0.0202, 0.0609, 0.0697,
0.0015, 0.0077, 0.0403, 0.0241, 0.0675, 0.0751, 0.0193, 0.0010, 0.0599,
0.0633, 0.0906, 0.0276, 0.0098, 0.0236, 0.0015, 0.0197, 0.0007
])
fig, axes = plt.subplots(1, L, figsize=(18, 4))
x = np.arange(26)
for j in range(L):
stream = streams[j]
freq = np.array([stream.count(ch) for ch in alphabet]) / len(stream)
axes[j].bar(x, freq, color='darkorange', alpha=0.8)
axes[j].set_xticks(x[::5])
axes[j].set_xticklabels([alphabet[i] for i in range(0, 26, 5)], fontsize=8)
axes[j].set_title(f'Stream {j}\n(shift by k$_{j}$)', fontsize=10)
axes[j].set_ylim(0, 0.20)
if j == 0:
axes[j].set_ylabel('Frequency')
plt.suptitle('Frequency Distributions of Individual Streams', fontsize=13, y=1.02)
plt.tight_layout()
plt.savefig('fig_ch05_stream_frequencies.png', dpi=150, bbox_inches='tight')
plt.show()
print("Each stream shows a shifted version of the English frequency distribution!")
Ciphertext length: 1189
Key length L = 5
Stream 0: 238 chars, first 30: 'hwnxjjujdiunjgsgzinrltjtcwmwdg'
Stream 1: 238 chars, first 30: 'tdadejwotpldezopxlippolmpztjsp'
Stream 2: 238 chars, first 30: 'poheskoandncslnrbneseededustae'
Stream 3: 238 chars, first 30: 'ttqofqoioqpdkegexppezpkrfsfthz'
Stream 4: 237 chars, first 30: 'igvvlioesihiqeqniqeegvxmllsiiy'
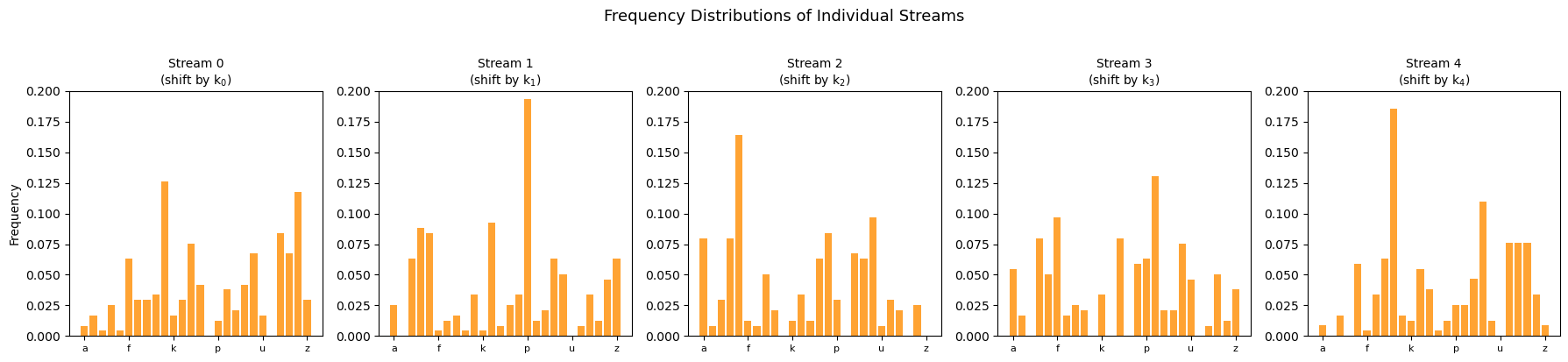
Each stream shows a shifted version of the English frequency distribution!
Key Insight
Each individual stream is just a Caesar cipher! The frequency distribution of each stream is a shifted copy of the English frequency distribution. We can recover the shift (and thus the corresponding key letter) by finding which shift maximizes the correlation with the standard English frequencies.
Experiment 4: Full Attack#
Pipeline
We now implement the complete attack: Kasiski examination determines the key length, then frequency analysis on each stream recovers each key letter, and finally we decrypt the message.
import numpy as np
# --- Step 1: Key length determination (already done: L=5) ---
L = 5
alphabet = 'abcdefghijklmnopqrstuvwxyz'
english_freq = np.array([
0.0817, 0.0150, 0.0278, 0.0425, 0.1270, 0.0223, 0.0202, 0.0609, 0.0697,
0.0015, 0.0077, 0.0403, 0.0241, 0.0675, 0.0751, 0.0193, 0.0010, 0.0599,
0.0633, 0.0906, 0.0276, 0.0098, 0.0236, 0.0015, 0.0197, 0.0007
])
def chi_squared_score(observed_freq, expected_freq):
"""Compute chi-squared statistic between observed and expected distributions."""
# Avoid division by zero
mask = expected_freq > 0
return np.sum((observed_freq[mask] - expected_freq[mask])**2 / expected_freq[mask])
def recover_shift(stream_text):
"""
Determine the Caesar shift for a single stream by testing all 26 shifts
and finding the one whose frequency distribution best matches English.
"""
stream_ints = np.array([ord(ch) - ord('a') for ch in stream_text])
best_shift = 0
best_score = float('inf')
for shift in range(26):
# Decrypt with this candidate shift
decrypted = (stream_ints - shift) % 26
freq = np.array([np.sum(decrypted == i) for i in range(26)]) / len(decrypted)
score = chi_squared_score(freq, english_freq)
if score < best_score:
best_score = score
best_shift = shift
return best_shift
# --- Step 2: Recover each key letter ---
print("=" * 60)
print("FULL VIGENERE ATTACK PIPELINE")
print("=" * 60)
print(f"\nStep 1: Key length from Kasiski examination: L = {L}")
recovered_key = []
print(f"\nStep 2: Recovering key letters via frequency analysis:")
for j in range(L):
stream = ciphertext[j::L]
shift = recover_shift(stream)
key_letter = chr(shift + ord('a'))
recovered_key.append(key_letter)
print(f" Stream {j}: best shift = {int(shift):2d} -> key letter = '{key_letter}'")
recovered_key_str = ''.join(recovered_key)
print(f"\nRecovered key: '{recovered_key_str}'")
print(f"Actual key: '{key}'")
print(f"Key recovery: {'SUCCESS' if recovered_key_str == key else 'PARTIAL'}")
# --- Step 3: Decrypt ---
cipher_ints = np.array([ord(ch) - ord('a') for ch in ciphertext])
rec_key_ints = np.array([ord(ch) - ord('a') for ch in recovered_key_str])
rec_key_stream = np.tile(rec_key_ints, len(cipher_ints) // L + 1)[:len(cipher_ints)]
decrypted_ints = (cipher_ints - rec_key_stream) % 26
decrypted_text = ''.join(chr(v + ord('a')) for v in decrypted_ints)
print(f"\nStep 3: Decrypted text (first 200 chars):")
print(f" {decrypted_text[:200]}")
# Verify
print(f"\nDecryption matches original plaintext: {decrypted_text == plaintext}")
============================================================
FULL VIGENERE ATTACK PIPELINE
============================================================
Step 1: Key length from Kasiski examination: L = 5
Step 2: Recovering key letters via frequency analysis:
Stream 0: best shift = 5 -> key letter = 'f'
Stream 1: best shift = 11 -> key letter = 'l'
Stream 2: best shift = 0 -> key letter = 'a'
Stream 3: best shift = 12 -> key letter = 'm'
Stream 4: best shift = 4 -> key letter = 'e'
Recovered key: 'flame'
Actual key: 'flame'
Key recovery: SUCCESS
Step 3: Decrypted text (first 200 chars):
ciphersohcipherssecretstheykeeplockedawayincodedeepanddiscreetsymbolsandnumbersjumbledandmixedamessageencodedreadytobefixedthroughhistorytheyhavebeenusedtohideplansofwarlovelettersbesidetherosettaston
Decryption matches original plaintext: True
Complete Break
The Vigenère cipher, once considered unbreakable, falls to a two-stage attack:
Kasiski examination reveals the key length \(L\) from repeated ciphertext patterns.
Frequency analysis on each of the \(L\) Caesar-cipher streams recovers each key letter.
The entire attack requires only the ciphertext (a ciphertext-only attack) and knowledge that the underlying language is English.
Experiment 4b: Visualizing the Key Recovery#
For each stream, we plot the chi-squared score for all 26 candidate shifts. The minimum corresponds to the correct key letter.
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
L = 5
alphabet = 'abcdefghijklmnopqrstuvwxyz'
english_freq = np.array([
0.0817, 0.0150, 0.0278, 0.0425, 0.1270, 0.0223, 0.0202, 0.0609, 0.0697,
0.0015, 0.0077, 0.0403, 0.0241, 0.0675, 0.0751, 0.0193, 0.0010, 0.0599,
0.0633, 0.0906, 0.0276, 0.0098, 0.0236, 0.0015, 0.0197, 0.0007
])
fig, axes = plt.subplots(1, L, figsize=(18, 4))
recovered_letters = []
for j in range(L):
stream = ciphertext[j::L]
stream_ints = np.array([ord(ch) - ord('a') for ch in stream])
scores = []
for shift in range(26):
decrypted = (stream_ints - shift) % 26
freq = np.array([np.sum(decrypted == i) for i in range(26)]) / len(decrypted)
mask = english_freq > 0
chi2 = np.sum((freq[mask] - english_freq[mask])**2 / english_freq[mask])
scores.append(chi2)
best_shift = int(np.argmin(scores))
recovered_letters.append(chr(best_shift + ord('a')))
colors = ['firebrick' if s == best_shift else 'steelblue' for s in range(26)]
axes[j].bar(range(26), scores, color=colors, alpha=0.8)
axes[j].set_title("Stream " + str(j) + ": best='" + chr(best_shift + ord('a')) + "'", fontsize=10)
axes[j].set_xlabel('Shift')
if j == 0:
axes[j].set_ylabel('$\\chi^2$ score')
axes[j].set_xticks(range(0, 26, 5))
plt.suptitle('Chi-squared Scores for Each Stream (lower = better fit)', fontsize=13, y=1.02)
plt.tight_layout()
plt.savefig('fig_ch05_chi_squared.png', dpi=150, bbox_inches='tight')
plt.show()
recovered_key_viz = ''.join(recovered_letters)
print("Recovered key: '" + recovered_key_viz + "'")
print("Actual key: '" + key + "'")
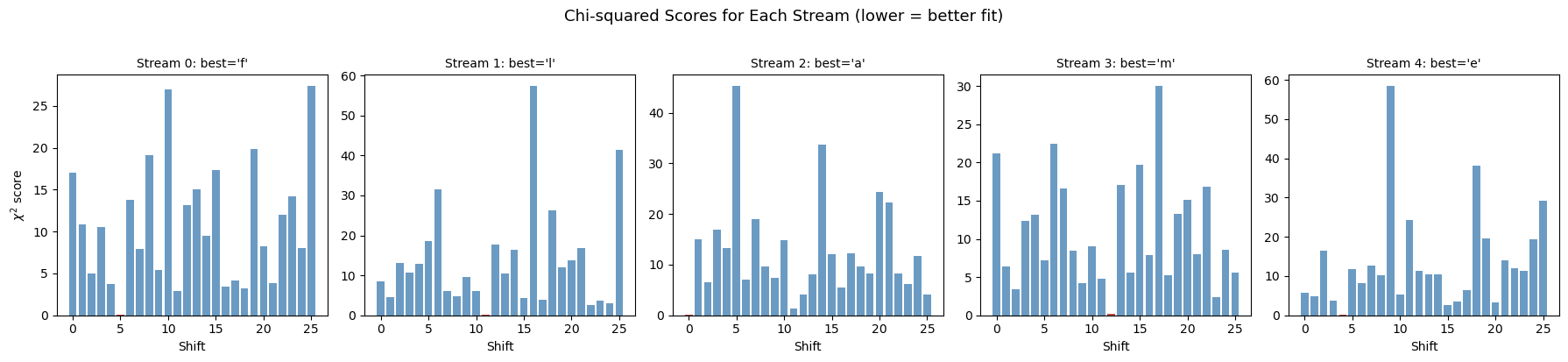
Recovered key: 'flame'
Actual key: 'flame'
Experiment 5: Effect of Key Length on Security#
How does the key length affect the difficulty of the Kasiski attack? Longer keys produce fewer repeated trigrams, making the examination harder. We test multiple key lengths and track the number of repeated trigrams.
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
from collections import defaultdict
# Use the same plaintext for all experiments
test_keys = {
2: "ab",
3: "key",
4: "code",
5: "flame",
6: "hunter",
7: "richard",
8: "security",
10: "encryption",
12: "cryptography",
}
results = []
for L_test, k_test in sorted(test_keys.items()):
# Encrypt
k_ints = np.array([ord(ch) - ord('a') for ch in k_test])
p_ints = np.array([ord(ch) - ord('a') for ch in plaintext])
ks = np.tile(k_ints, len(p_ints) // len(k_ints) + 1)[:len(p_ints)]
ct = ''.join(chr(v + ord('a')) for v in ((p_ints + ks) % 26))
# Count repeated trigrams
ngram_pos = defaultdict(list)
for i in range(len(ct) - 2):
ngram_pos[ct[i:i+3]].append(i)
repeated = {ng: pos for ng, pos in ngram_pos.items() if len(pos) > 1}
n_repeated = len(repeated)
# Total distances
dists = []
for pos in repeated.values():
for i in range(len(pos)):
for j in range(i+1, len(pos)):
dists.append(pos[j] - pos[i])
results.append((L_test, n_repeated, len(dists)))
print(f"Key length {int(L_test):2d} ('{k_test:12s}'): {int(n_repeated):3d} repeated trigrams, "
f"{int(len(dists)):4d} pairwise distances")
# Plot
fig, ax = plt.subplots(figsize=(9, 5))
lengths = [r[0] for r in results]
n_repeated_list = [r[1] for r in results]
n_distances_list = [r[2] for r in results]
ax.plot(lengths, n_repeated_list, 'o-', color='steelblue', linewidth=2,
markersize=8, label='Repeated trigrams')
ax.set_xlabel('Key length $L$', fontsize=12)
ax.set_ylabel('Count', fontsize=12)
ax.set_title('Effect of Key Length on Kasiski Examination', fontsize=14)
ax.legend(fontsize=11)
ax.grid(True, alpha=0.3)
ax.set_xticks(lengths)
plt.tight_layout()
plt.savefig('fig_ch05_key_length_effect.png', dpi=150, bbox_inches='tight')
plt.show()
print("\nLonger keys produce fewer repeated trigrams, requiring longer ciphertext for Kasiski.")
Key length 2 ('ab '): 206 repeated trigrams, 839 pairwise distances
Key length 3 ('key '): 185 repeated trigrams, 583 pairwise distances
Key length 4 ('code '): 176 repeated trigrams, 466 pairwise distances
Key length 5 ('flame '): 140 repeated trigrams, 326 pairwise distances
Key length 6 ('hunter '): 132 repeated trigrams, 274 pairwise distances
Key length 7 ('richard '): 148 repeated trigrams, 271 pairwise distances
Key length 8 ('security '): 138 repeated trigrams, 224 pairwise distances
Key length 10 ('encryption '): 110 repeated trigrams, 184 pairwise distances
Key length 12 ('cryptography'): 104 repeated trigrams, 163 pairwise distances

Longer keys produce fewer repeated trigrams, requiring longer ciphertext for Kasiski.
Observation
As the key length increases, the number of repeated trigrams decreases. For very long keys (approaching the length of the plaintext), the cipher becomes a one-time pad and is theoretically unbreakable. In practice, the Kasiski method works well for key lengths up to about 10–15 with texts of a few hundred characters.
Experiment 6: Full Attack on a Different Key#
We demonstrate the full attack pipeline end-to-end on a ciphertext encrypted with the key "hunter" (length 6).
import numpy as np
from math import gcd
from functools import reduce
from collections import defaultdict
# --- New encryption with key "hunter" (length 6) ---
key2 = "hunter"
key2_ints = np.array([ord(ch) - ord('a') for ch in key2])
plain_ints2 = np.array([ord(ch) - ord('a') for ch in plaintext])
ks2 = np.tile(key2_ints, len(plain_ints2) // len(key2_ints) + 1)[:len(plain_ints2)]
ciphertext2 = ''.join(chr(v + ord('a')) for v in ((plain_ints2 + ks2) % 26))
print("Plaintext length:", len(plaintext))
print("Key:", repr(key2), "(length", str(len(key2)) + ")")
print("Ciphertext:", ciphertext2[:60] + "...")
# --- Kasiski examination ---
# Find repeated trigrams
ngram_pos2 = defaultdict(list)
for i in range(len(ciphertext2) - 2):
ngram_pos2[ciphertext2[i:i+3]].append(i)
repeated2 = {ng: pos for ng, pos in ngram_pos2.items() if len(pos) > 1}
# Compute all distances
dists2 = []
for pos in repeated2.values():
for i in range(len(pos)):
for j in range(i+1, len(pos)):
dists2.append(pos[j] - pos[i])
# Factor analysis with normalization
# Raw count for factor f is biased toward small factors (they divide more numbers).
# We normalize by the expected count: total_distances / f.
# Among factors with similar normalized scores, we prefer the smallest (Occam's razor).
factor_counts2 = defaultdict(int)
total_dists = len(dists2)
for d in dists2:
for f in range(2, min(d, 15) + 1):
if d % f == 0:
factor_counts2[f] += 1
print("\nKasiski key-length suggestions:")
print(" {:>5s} {:>5s} {:>12s}".format("L", "count", "norm. score"))
print(" " + "-" * 28)
scored = []
for f in sorted(factor_counts2.keys()):
count = factor_counts2[f]
expected = total_dists / f
norm_score = count / expected if expected > 0 else 0
scored.append((f, count, norm_score))
scored.sort(key=lambda x: x[2], reverse=True)
for f, count, ns in scored[:10]:
marker = " <-- TRUE" if f == len(key2) else ""
print(" {:5d} {:5d} {:12.4f}{}".format(f, count, ns, marker))
# Pick the smallest factor whose normalized score is within 95% of the maximum
max_score = scored[0][2]
threshold = 0.95 * max_score
candidates = [(f, ns) for f, _, ns in scored if ns >= threshold]
candidates.sort() # sort by factor value ascending
L2 = candidates[0][0]
print("\nTop candidates (within 95%% of max score):", [c[0] for c in candidates])
print("Estimated key length (smallest top candidate): L =", L2)
# --- Frequency analysis per stream ---
english_freq = np.array([
0.0817, 0.0150, 0.0278, 0.0425, 0.1270, 0.0223, 0.0202, 0.0609, 0.0697,
0.0015, 0.0077, 0.0403, 0.0241, 0.0675, 0.0751, 0.0193, 0.0010, 0.0599,
0.0633, 0.0906, 0.0276, 0.0098, 0.0236, 0.0015, 0.0197, 0.0007
])
recovered_key2 = []
for j in range(L2):
stream = ciphertext2[j::L2]
stream_ints = np.array([ord(ch) - ord('a') for ch in stream])
best_shift, best_score = 0, float('inf')
for shift in range(26):
dec = (stream_ints - shift) % 26
freq = np.array([np.sum(dec == i) for i in range(26)]) / len(dec)
mask = english_freq > 0
chi2 = np.sum((freq[mask] - english_freq[mask])**2 / english_freq[mask])
if chi2 < best_score:
best_score = chi2
best_shift = shift
recovered_key2.append(chr(best_shift + ord('a')))
rec_key2_str = ''.join(recovered_key2)
print("\nRecovered key:", repr(rec_key2_str))
print("Actual key: ", repr(key2))
print("Match:", rec_key2_str == key2)
# --- Decrypt ---
rk2 = np.array([ord(ch) - ord('a') for ch in rec_key2_str])
rks2 = np.tile(rk2, len(plain_ints2) // L2 + 1)[:len(ciphertext2)]
ct2_ints = np.array([ord(ch) - ord('a') for ch in ciphertext2])
dec2 = ''.join(chr(v + ord('a')) for v in ((ct2_ints - rks2) % 26))
print("\nDecrypted (first 150 chars):", dec2[:150])
print("Correct decryption:", dec2 == plaintext)
Plaintext length: 1189
Key: 'hunter' (length 6)
Ciphertext: jccaiiziuvmgoyelwvjlrmwkoyldivwfbvovkujtczuwbwiulyctrukcfvvv...
Kasiski key-length suggestions:
L count norm. score
----------------------------
12 121 5.2993
6 241 5.2774 <-- TRUE
3 246 2.6934
9 81 2.6606
2 257 1.8759
4 128 1.8686
15 34 1.8613
8 60 1.7518
10 37 1.3504
14 21 1.0730
Top candidates (within 95%% of max score): [6, 12]
Estimated key length (smallest top candidate): L = 6
Recovered key: 'hunter'
Actual key: 'hunter'
Match: True
Decrypted (first 150 chars): ciphersohcipherssecretstheykeeplockedawayincodedeepanddiscreetsymbolsandnumbersjumbledandmixedamessageencodedreadytobefixedthroughhistorytheyhavebeenu
Correct decryption: True
Experiment 7: Visualizing the Vigenère Tableau#
The classical Vigenère tableau (or tabula recta) is a \(26 \times 26\) table where row \(i\) is the alphabet shifted by \(i\) positions. Let us visualize it as a heatmap.
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
# Build the Vigenere tableau
tableau = np.zeros((26, 26), dtype=int)
for i in range(26):
for j in range(26):
tableau[i, j] = (i + j) % 26
fig, ax = plt.subplots(figsize=(10, 9))
im = ax.imshow(tableau, cmap='viridis', aspect='equal')
alphabet = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
ax.set_xticks(range(26))
ax.set_xticklabels(list(alphabet), fontsize=8)
ax.set_yticks(range(26))
ax.set_yticklabels(list(alphabet), fontsize=8)
ax.set_xlabel('Plaintext letter', fontsize=12)
ax.set_ylabel('Key letter', fontsize=12)
ax.set_title('Vigen\u00e8re Tableau (Tabula Recta)', fontsize=14)
# Add text annotations for a 10x10 subset to keep it readable
for i in range(10):
for j in range(10):
ax.text(j, i, chr(tableau[i, j] + ord('A')),
ha='center', va='center', fontsize=6, color='white', fontweight='bold')
plt.colorbar(im, ax=ax, shrink=0.8, label='Letter index (A=0, ..., Z=25)')
plt.tight_layout()
plt.savefig('fig_ch05_vigenere_tableau.png', dpi=150, bbox_inches='tight')
plt.show()
print("The Vigenere tableau: row = key letter, column = plaintext letter, entry = ciphertext letter.")
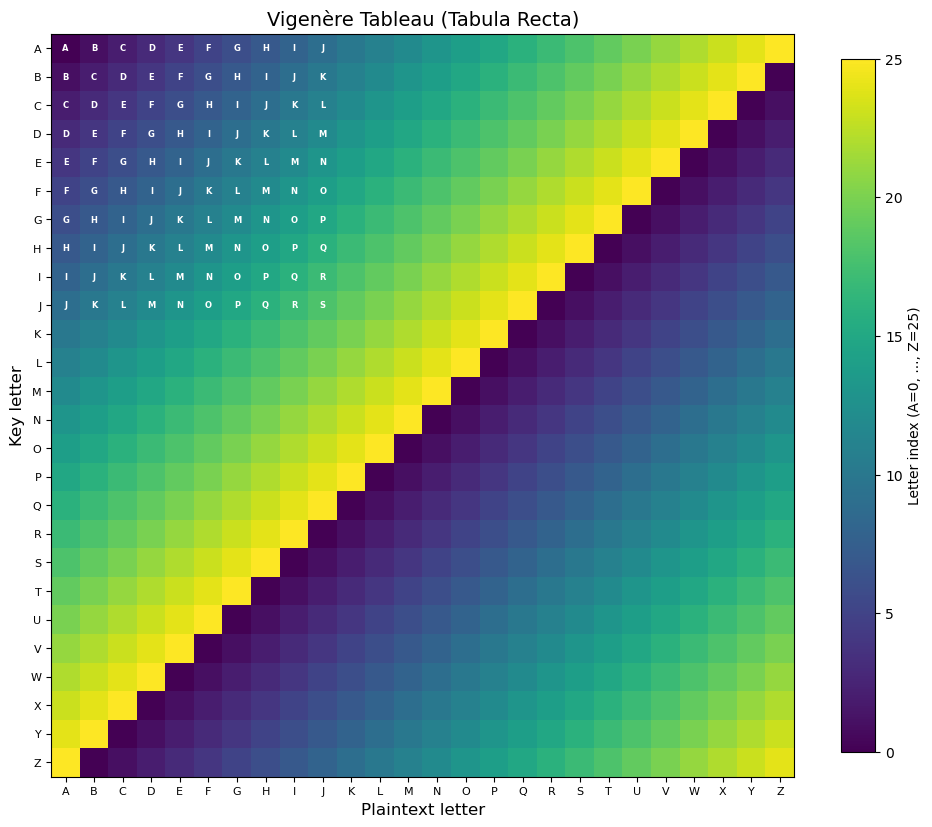
The Vigenere tableau: row = key letter, column = plaintext letter, entry = ciphertext letter.
5.6 Exercises#
Exercise 5.1 (Manual Vigenère)
Encrypt the plaintext ATTACKATDAWN with the Vigenère key LEMON by hand, using the Vigenère tableau. Verify your result with the VigenereCipher class.
Exercise 5.2 (Kasiski by Hand)
Given the ciphertext below (encrypted with a Vigenère cipher of unknown key length), find all repeated trigrams and their distances. What key length does the Kasiski examination suggest?
Ciphertext: VVHQWVVRHMUSGJGTHKIHTSSEJCHLSFCBGVWCRLRYQTFSVGAHWKCUHWAUGLQHNSLRLJSHBLTSPISPRDXLJSVEEGHLQWKASSKUWEP
Hint: Look for trigrams that appear at least twice and compute the GCD of all distances.
Exercise 5.3 (Chi-Squared vs. Dot Product)
In the key-recovery step (Experiment 4), we used the chi-squared statistic to measure how well a candidate shift matches the expected English frequencies. An alternative is the dot product (or correlation) method:
where \(f_i\) is the frequency of letter \(i\) in the stream and \(e_j\) is the expected English frequency of letter \(j\). Implement this alternative and compare the results. Which method is more robust with short texts?
Exercise 5.4 (Key Length vs. Text Length)
Experimentally determine the minimum ciphertext length needed for a successful Kasiski attack as a function of key length. For key lengths \(L = 3, 4, 5, \ldots, 12\), find the shortest prefix of the ciphertext for which the Kasiski examination correctly identifies \(L\). Plot your results.
Exercise 5.5 (Autokey Cipher)
The autokey cipher (also attributed to Vigenère) uses the plaintext itself to extend the key:
Implement the autokey cipher. Explain why the Kasiski examination does not work against it. What alternative attack strategies might apply?
5.7 Summary#
In this chapter we studied the Vigenère cipher and its cryptanalysis via the Kasiski examination:
Concept |
Key Point |
|---|---|
Vigenère cipher |
Polyalphabetic substitution: \(c_i = (m_i + k_{i \bmod L}) \bmod 26\) |
Polyalphabetic advantage |
Same plaintext letter maps to different ciphertext letters, flattening frequency distributions |
Kasiski examination |
Repeated ciphertext \(n\)-grams reveal the key length via GCD of distances |
Theorem 5.1 |
If \(L \mid (j-i)\) and plaintext trigrams at \(i, j\) are equal, then ciphertext trigrams at \(i, j\) are equal |
Stream decomposition |
Once \(L\) is known, split into \(L\) Caesar streams and apply frequency analysis independently |
Full attack |
Ciphertext-only: Kasiski \(\to\) key length \(\to\) frequency analysis per stream \(\to\) key recovery \(\to\) decryption |
Limitations |
Longer keys require longer ciphertext; very long keys approach one-time-pad security |
Looking Ahead
In Chapter 6, we will study the index of coincidence (Friedman, 1922), which provides a more systematic and robust method for determining the key length of a polyalphabetic cipher. Unlike Kasiski examination, which relies on finding repeated \(n\)-grams, the index of coincidence uses a global statistical measure.
5.8 References#
Vigenère, B. (1586). Traité des chiffres, ou secrètes manières d’escrire. Paris.
Kasiski, F. W. (1863). Die Geheimschriften und die Dechiffrir-Kunst. Berlin: E. S. Mittler und Sohn.
Babbage, C. (c. 1846). Unpublished notes on breaking the Vigenère cipher, held in the British Library.
Singh, S. (1999). The Code Book: The Science of Secrecy from Ancient Egypt to Quantum Cryptography. Anchor Books. Chapter 2.
Katz, J. and Lindell, Y. (2020). Introduction to Modern Cryptography. 3rd ed. CRC Press. Section 1.3.
Stinson, D. R. and Paterson, M. (2018). Cryptography: Theory and Practice. 4th ed. CRC Press. Chapter 2.
Friedman, W. F. (1922). The Index of Coincidence and Its Applications in Cryptanalysis. Department of Ciphers, Riverbank Laboratories, Publication No. 22.