
Chapter 43 — Code-Based Cryptography: McEliece and Goppa Codes#
“There are two types of cryptography in this world: cryptography that will stop your kid sister from reading your files, and cryptography that will stop major governments from reading your files.” — Bruce Schneier, Applied Cryptography, 1996
In this chapter we study code-based cryptography, one of the oldest families of public-key cryptosystems still considered secure against quantum computers. We implement McEliece encryption based on binary Goppa codes, explore error correction, and analyse the scheme’s security properties.
43.1 Historical Context#
In 1978, just one year after RSA was published, Robert McEliece proposed a radically different public-key cryptosystem based on error-correcting codes. Instead of relying on the difficulty of factoring integers, McEliece’s scheme relies on the hardness of decoding a general linear code — a problem known to be NP-hard.
McEliece chose binary Goppa codes (introduced by Valerii Denisovich Goppa in 1970) as the underlying code family. These codes possess an efficient algebraic decoding algorithm but, when disguised by a random scrambling matrix and permutation, appear indistinguishable from random linear codes.
In 1986, Harald Niederreiter proposed a dual variant that encrypts via syndromes rather than codewords. The two schemes were later shown to be equivalent in security.
Tip
Unlike RSA and elliptic curve cryptography, the McEliece cryptosystem has resisted all known quantum attacks. Shor’s algorithm does not apply because the underlying problem is not based on a hidden subgroup structure.
In the NIST Post-Quantum Cryptography standardization process (begun 2017), Classic McEliece advanced to the fourth round as a candidate for key encapsulation. Its conservative design — essentially McEliece’s original 1978 proposal with modern parameters — reflects decades of cryptanalytic confidence.
Year |
Event |
|---|---|
1970 |
Goppa introduces algebraic-geometry codes |
1978 |
McEliece proposes code-based public-key encryption |
1986 |
Niederreiter publishes the dual (syndrome-based) variant |
1988 |
Li, Deng, Wang show equivalence of McEliece and Niederreiter |
2008 |
Bernstein, Lange, Peters propose efficient implementations |
2017 |
Classic McEliece submitted to NIST PQC competition |
2022 |
Classic McEliece advances to NIST Round 4 |
43.2 Formal Definitions#
Definition 43.1 — Linear Code
A binary linear code \(\mathcal{C}\) with parameters \([n, k, d]\) is a \(k\)-dimensional subspace of \(\mathbb{F}_2^n\) with minimum Hamming distance \(d\). It can correct up to \(t = \lfloor (d-1)/2 \rfloor\) errors.
Definition 43.2 — Generator and Parity-Check Matrices
A generator matrix \(G \in \mathbb{F}_2^{k \times n}\) for code \(\mathcal{C}\) satisfies \(\mathcal{C} = \{\mathbf{m}G : \mathbf{m} \in \mathbb{F}_2^k\}\).
A parity-check matrix \(H \in \mathbb{F}_2^{(n-k) \times n}\) satisfies \(\mathcal{C} = \{\mathbf{c} \in \mathbb{F}_2^n : H\mathbf{c}^T = \mathbf{0}\}\).
We have \(GH^T = \mathbf{0}\) (mod 2).
Definition 43.3 — Syndrome Decoding
Given a received word \(\mathbf{r} = \mathbf{c} + \mathbf{e}\) (codeword plus error), the syndrome is \(\mathbf{s} = H\mathbf{r}^T = H\mathbf{e}^T\). The decoding problem is: given \(\mathbf{s}\), find the minimum-weight \(\mathbf{e}\) such that \(H\mathbf{e}^T = \mathbf{s}\).
Definition 43.4 — Binary Goppa Code
Let \(g(x) \in \mathbb{F}_{2^m}[x]\) be a polynomial of degree \(t\) with no repeated roots, and let \(L = (\alpha_0, \ldots, \alpha_{n-1})\) be a sequence of distinct elements from \(\mathbb{F}_{2^m}\) such that \(g(\alpha_i) \neq 0\) for all \(i\). The binary Goppa code \(\Gamma(L, g)\) is:
This code has parameters \([n, k \geq n - mt, d \geq 2t+1]\).
Definition 43.5 — McEliece Cryptosystem
Key Generation: Choose a binary Goppa code with generator matrix \(G_0\). Select a random invertible \(k \times k\) matrix \(S\) and a random \(n \times n\) permutation matrix \(P\). Set the public key \(G_{\mathrm{pub}} = S G_0 P\).
Encryption: To encrypt message \(\mathbf{m} \in \mathbb{F}_2^k\), compute \(\mathbf{c} = \mathbf{m} G_{\mathrm{pub}} + \mathbf{e}\) where \(\mathbf{e}\) is a random error vector of weight \(t\).
Decryption: Compute \(\mathbf{c}' = \mathbf{c} P^{-1}\), decode \(\mathbf{c}'\) using the Goppa decoder to remove errors, then recover \(\mathbf{m} = \mathbf{m}' S^{-1}\).
Theorem 43.1 — Hardness of Generic Decoding
The Computational Syndrome Decoding problem is NP-complete: given a random parity-check matrix \(H \in \mathbb{F}_2^{r \times n}\), a syndrome \(\mathbf{s} \in \mathbb{F}_2^r\), and an integer \(w\), decide whether there exists \(\mathbf{e}\) of Hamming weight \(\leq w\) with \(H\mathbf{e}^T = \mathbf{s}\).
— Berlekamp, McEliece, and van Tilborg (1978)
43.3 Coding-Theory Foundations#
The formal definitions in 43.2 are deliberately terse. This supplementary section fills in the why behind code-based cryptography: where error-correcting codes come from, what “decoding” really costs, and how the algebraic families used by McEliece sit inside the larger landscape of coding theory. It draws on two of the author’s own lectures — Codes and sphere packings and the talk Zeta functions, Weil conjectures and how to apply them — and can be read independently of the implementation that follows. Notation matches 43.2: a binary linear code is an \([n,k,d]\) subspace \(\mathcal{C}\subseteq\mathbb{F}_2^n\) with generator matrix \(G\), parity-check matrix \(H\), and minimum distance \(d\), correcting up to \(t=\lfloor(d-1)/2\rfloor\) errors.
43.3.1 The noisy channel and Shannon’s coding theorem#
Error-correcting codes exist because real communication channels corrupt data. The simplest mathematical model is the binary symmetric channel (BSC): each transmitted bit is independently flipped with crossover probability \(p\) and left intact with probability \(1-p\).
We transmit in packets of length \(n\). A codeword \(\mathbf{c}\in\mathcal{C}\) leaves the transmitter and arrives as \(\mathbf{r}=\mathbf{c}+\mathbf{e}\), where the error \(\mathbf{e}\in\mathbb{F}_2^n\) has each coordinate equal to \(1\) with probability \(p\). The whole point of a code is redundancy: by using only \(2^k\) of the \(2^n\) possible words, we leave “room” between codewords so that the receiver can guess which \(\mathbf{c}\) was most likely sent.
Shannon’s celebrated theorem says this redundancy can be made almost free, as long as we do not try to send too fast. Define the information rate \(R=k/n\) and the binary entropy \(H(p)=-p\log_2 p-(1-p)\log_2(1-p)\).
Theorem — Shannon’s noisy-channel coding theorem (1948)
Fix a binary symmetric channel with crossover probability \(p<\tfrac12\), and let \(P_{\min}(M,n,p)\) denote the smallest achievable average decoding-error probability over all codes \(\mathcal{C}\subseteq\{0,1\}^n\) with \(|\mathcal{C}|=M\) codewords. If we scale the number of codewords as \(M(n)=2^{Rn}\) with
then \(P_{\min}\big(M(n),\,n,\,p\big)\to 0\) as \(n\to\infty\).
The quantity \(C(p)=1-H(p)\) is the channel capacity. The theorem is an existence result: it guarantees that good codes exist below capacity, but says nothing about how to build them or how to decode them efficiently. The rest of coding theory — and all of code-based cryptography — lives in that gap between existence and efficient algorithms.
Tip
Cryptography turns Shannon’s optimism on its head. For honest parties holding a secret structured code, decoding is easy; for an attacker who sees only a code that looks random, decoding is the hard problem of 43.3.2. McEliece exploits exactly this asymmetry.
43.3.2 Syndrome decoding via coset leaders#
Definition 43.3 phrased decoding as: given the syndrome \(\mathbf{s}=H\mathbf{r}^{\mathsf T}=H\mathbf{e}^{\mathsf T}\) (we use the column convention \(\mathbf{s}=H\mathbf{r}^{\mathsf T}\) throughout), find the minimum-weight \(\mathbf{e}\) with \(H\mathbf{e}^{\mathsf T}=\mathbf{s}\). Here is the conceptual machinery that makes that well-defined — the standard-array / coset-leader picture.
The code \(\mathcal{C}=\operatorname{im} f\) (where \(f:\mathbb{F}_2^k\to\mathbb{F}_2^n\) is the encoder) is a subgroup of \(\mathbb{F}_2^n\), so it partitions the ambient space into \(2^{n-k}\) cosets
and two words have the same syndrome iff they lie in the same coset, because \(H\mathbf{v}^{\mathsf T}=H(\mathbf{v}+\mathbf{c})^{\mathsf T}\) for every \(\mathbf{c}\in\mathcal{C}\). The map \(\text{coset}\mapsto\text{syndrome}\) is a bijection between the \(2^{n-k}\) cosets and the \(2^{n-k}\) possible syndromes.
Within each coset we single out a coset leader: a vector \(\mathbf{l}\) of minimum Hamming weight in that coset. Decoding then becomes a table lookup:
receive \(\mathbf{r}\) and compute \(\mathbf{s}=H\mathbf{r}^{\mathsf T}\);
look up the leader \(\mathbf{l}_i\) of the coset with syndrome \(\mathbf{s}\) (precomputed: \(H\mathbf{l}_i^{\mathsf T}=\mathbf{s}\));
output the corrected codeword \(\mathbf{c}=\mathbf{r}-\mathbf{l}_i\) and recover the message \(\psi(\mathbf{c})\), where \(\psi\circ f=\mathrm{id}\) is the decoder map (we write \(\psi\), not \(g\), to avoid clashing with the Goppa polynomial).
This is maximum-likelihood decoding on the BSC: subtracting the minimum-weight error is exactly choosing the nearest codeword, which (for \(p<\tfrac12\)) is the most probable transmitted word. If \(\mathcal{C}\) has minimum distance \(d=2t+1\), then every error of weight \(\le t\) is its own coset leader, so all such errors are corrected uniquely.
Why this is hard in general
The standard array has \(2^{n-k}\) cosets. Building or storing the leader table is exponential in the redundancy \(n-k\), and for a code with no exploitable structure, finding a minimum-weight vector in a coset is precisely the syndrome decoding problem, proven NP-hard by Berlekamp, McEliece and van Tilborg (1978). This is the rock on which McEliece security is built.
The escape routes are exactly the two themes of this chapter:
Legitimate decoding uses algebraic structure (e.g. Patterson’s algorithm for binary Goppa codes, 43.5) to find the coset leader in \(O(nt)\) instead of \(O\!\binom{n}{t}\) time.
Attacks that lack the secret structure fall back on information-set decoding (Prange, Stern, BJMM, …), which is still exponential — this is what the work-factor analysis in Experiment 4 estimates.
43.3.3 Perfect codes and the sphere-packing bound#
The geometric way to read “\(d=2t+1\) corrects \(t\) errors” is to put a Hamming ball of radius \(t\) around each codeword. A ball of radius \(e\) around \(\mathbf{x}\in\mathbb{F}_2^n\) is
The code corrects \(t\) errors exactly when the balls of radius \(t=\lfloor(d-1)/2\rfloor\) are pairwise disjoint — the codewords are sphere centres packed into the cube \(\mathbb{F}_2^n\). Counting points immediately gives the fundamental upper bound.
Theorem — Sphere-packing (Hamming) bound
For any binary code with \(M\) codewords in \(\mathbb{F}_2^n\) correcting \(e\) errors, the disjoint balls cannot overflow the space:
Equivalently, for a linear \([n,k]\) code with \(M=2^k\),
A code that meets this bound with equality is called perfect: the radius-\(e\) balls around the codewords tile \(\mathbb{F}_2^n\) with no gaps and no overlaps — every word is within distance \(e\) of exactly one codeword. Perfect binary codes are rare and special. The complete list (up to trivialities) is:
Code |
Parameters |
\(e\) |
Balls tile \(\mathbb{F}_2^n\)? |
|---|---|---|---|
Trivial code |
\([1,1,1]\) |
\(0\) |
yes (trivially) |
Repetition code |
\([2m{+}1,\,1,\,2m{+}1]\) |
\(m\) |
yes |
Hamming code |
\([2^r{-}1,\,2^r{-}1{-}r,\,3]\) |
\(1\) |
yes |
(binary) Golay code |
\([23,12,7]\) |
\(3\) |
yes |
The Hamming \([7,4,3]\) code (the case \(r=3\), used in RAM ECC) is the workhorse example throughout this chapter; the Golay \([23,12,7]\) code — generated as a cyclic code by \(g(x)=1+x^2+x^4+x^5+x^6+x^{10}+x^{11}\) — is the only nontrivial multiple-error-correcting perfect binary code, and it flew on the Voyager missions. The title of the source deck, Codes and sphere packings, is no accident: a perfect code is literally an optimal sphere packing of Hamming space, and (43.3.5) the same Golay code seeds the densest known lattice packing in \(\mathbb{R}^{24}\).
43.3.4 Two different “Goppa codes”#
A persistent source of confusion: the literature contains two distinct code families both attributed to V. D. Goppa. They are historically linked — both invented by Goppa in the early 1970s–80s — but they are different constructions, and McEliece uses only the second one. The author’s Weil conjectures talk treats the first; this chapter’s Definition 43.4 is the second.
The two Goppa families — do not conflate them
(A) Algebraic-geometry (AG) codes \(C(D,G)\) — from curves. Given a nice (smooth, projective, geometrically irreducible) curve \(X\) over \(\mathbb{F}_q\), choose \(n\) distinct \(\mathbb{F}_q\)-rational points forming a divisor \(D=P_1+\cdots+P_n\) and another divisor \(G\) disjoint from \(D\). Using the Riemann–Roch space \(L(G)=\{f\in\mathbb{F}_q(X)^{*}:(f)+G\ge 0\}\cup\{0\}\), the evaluation map
has image the AG code \(C(D,G)\). Its parameters are governed by the genus \(g\) of \(X\):
and, when \(\deg G<n\), \(\;k+d\ge n+1-g\), i.e. \(R+\delta\ge 1-\tfrac{g-1}{n}\). These are the codes of the Weil-conjectures talk; their interest is asymptotic (see below).
(B) Binary Goppa codes \(\Gamma(L,g)\) — from a polynomial. These are the codes of Definition 43.4: fix a Goppa polynomial \(g(x)\in\mathbb{F}_{2^m}[x]\) of degree \(t\) with no repeated roots — for Patterson decoding (43.5) we take \(g\) irreducible, which is square-free a fortiori — and a support \(L=(\alpha_0,\dots,\alpha_{n-1})\) of distinct elements with \(g(\alpha_i)\ne 0\), and set
This is a subfield subcode of a generalized Reed–Solomon code; it is binary, has \(d\ge 2t+1\), and — crucially for cryptography — admits the efficient Patterson decoder. Classic McEliece uses exactly this family (B).
Same name, same inventor, different objects. Family (A) is parametrized by a geometric object (a curve and divisors); family (B) by a one-variable polynomial. Family (B) can be viewed as the genus-\(0\) / rational-function-field shadow of the AG idea, but the cryptosystem relies on the polynomial structure of (B), not on any curve.
Why AG codes matter (the asymptotic story). The quality of a code family is measured by how high it pushes the rate \(R=k/n\) against the relative distance \(\delta=d/n\) as \(n\to\infty\), captured by \(\alpha(\delta)=\limsup_{n\to\infty}\tfrac1n\log_q A_q(n,\delta n)\). Classical bounds bracket this curve:
where \(H_q\) is the \(q\)-ary entropy and the GV bound comes from \(A_q(n,d)\ge q^n/\sum_{j=0}^{d-1}\binom{n}{j}(q-1)^j\). For decades Gilbert–Varshamov was believed to be essentially tight. The surprise, and the punchline of the Weil-conjectures talk, is that AG codes from curves with many points beat it:
Theorem — Tsfasman–Vlăduț–Zink bound
For \(q=p^{2m}\) an even power of a prime there is a tower of modular (or Shimura) curves whose ratio of points to genus attains the Drinfeld–Vladut maximum \(A(q)=\sqrt{q}-1\). The resulting AG codes satisfy
which exceeds the Gilbert–Varshamov bound for \(q\ge 49\).
That the existence of curves with many points (a consequence of the Weil conjectures, \(|\#X(\mathbb{F}_{q^r})-(q^r+1)|\le 2g\sqrt{q^r}\)) yields record-breaking asymptotically good codes is the bridge from arithmetic geometry to coding theory. It is a statement about families (A) and is independent of, and not used by, the McEliece construction, which fixes concrete finite parameters with family (B).
43.3.5 A short code zoo#
The codes above sit inside a much larger menagerie. A few that recur in this chapter and in practice:
Cyclic codes. A linear code closed under cyclic shifts. Identifying \((c_0,\dots,c_{n-1})\) with the polynomial \(c_0+c_1x+\cdots+c_{n-1}x^{n-1}\) in \(\mathbb{F}_q[x]/(x^n-1)\), a cyclic code is exactly an ideal, generated by a single generator polynomial \(g(x)\mid x^n-1\). This algebraic packaging makes encoding and decoding hardware-friendly and underlies the next two entries.
Reed–Solomon codes. Cyclic codes over a large field \(\mathbb{F}_q\) built from a primitive element; they are maximum-distance-separable and excel at burst errors, which is why they protect CDs, DVDs, QR codes and deep-space links. Binary Goppa codes (family B above) are subfield subcodes of the closely related generalized Reed–Solomon codes.
Golay codes. The perfect binary \([23,12,7]\) code and its extension \([24,12,8]\); flown on Voyager 1 and 2. Their automorphism groups are the Mathieu sporadic simple groups \(M_{23},M_{24}\), and the extended Golay code \(\mathcal{G}\) builds the Leech lattice \(\Lambda_{24}\) (whose automorphism group modulo \(\pm I\) is the Conway group \(\mathrm{Co}_1\)) — the densest known sphere packing in \(24\) dimensions, closing the loop with 43.3.3.
Weight enumerators and the MacWilliams identity. The full error behaviour of a code is encoded in its weight enumerator \(W_{\mathcal C}(X,Y)=\sum_{\mathbf c\in\mathcal C}X^{\,n-\mathrm{wt}(\mathbf c)}Y^{\,\mathrm{wt}(\mathbf c)}\). Remarkably, the weight distribution of the dual code \(\mathcal C^{\perp}\) is determined entirely by that of \(\mathcal C\):
In particular a self-dual code (\(\mathcal C=\mathcal C^{\perp}\)) has \(W_{\mathcal C}(X,Y)=W_{\mathcal C}\!\big(\tfrac{X+Y}{\sqrt2},\tfrac{X-Y}{\sqrt2}\big)\), forcing strong symmetry on its weight distribution.
Code |
Parameters |
Type |
Where it appears |
|---|---|---|---|
Hamming |
\([2^r{-}1,2^r{-}1{-}r,3]\) |
perfect, cyclic |
RAM ECC; Experiments 1, 7 |
Reed–Solomon |
\([n,k,n{-}k{+}1]_q\) |
cyclic, MDS |
CD/DVD, deep space |
Golay (binary) |
\([23,12,7]\) |
perfect, cyclic |
Voyager; Mathieu groups; Leech lattice |
Reed–Solomon (GRS) |
— |
— |
parent of binary Goppa \(\Gamma(L,g)\) |
Binary Goppa |
\([n,\ge n{-}mt,\ge 2t{+}1]\) |
subfield subcode |
McEliece (this chapter) |
AG / Goppa \(C(D,G)\) |
from curves |
evaluation code |
asymptotically good (TVZ); not McEliece |
Note
The MacWilliams identity is also a practical cryptanalytic tool: it lets one compute the weight distribution of a code from that of its dual, and weight-distribution anomalies are one way “distinguishers” probe whether a public key in 43.3.2 hides a structured code rather than a random one — the indistinguishability assumption underpinning McEliece security.
43.4 Implementation#
We implement the core components step by step: linear codes over \(\mathbb{F}_2\), a simplified Goppa code construction, and the full McEliece cryptosystem.
43.4.1 Linear Code Class#
import numpy as np
import math
class LinearCode:
"""
Binary linear code [n, k, d] over GF(2).
Represented by a generator matrix G (k x n) and parity-check
matrix H ((n-k) x n). All arithmetic is modulo 2.
"""
def __init__(self, G):
"""Initialise from a generator matrix G (k x n) over GF(2)."""
self.G = np.array(G, dtype=int) % 2
self.k, self.n = self.G.shape
self.H = self._parity_check_matrix()
self.r = self.n - self.k # redundancy
def _rref_gf2(self, M):
"""Reduced row echelon form over GF(2)."""
A = np.array(M, dtype=int) % 2
rows, cols = A.shape
pivot_row = 0
pivot_cols = []
for col in range(cols):
# Find pivot
found = -1
for row in range(pivot_row, rows):
if A[row, col] == 1:
found = row
break
if found == -1:
continue
# Swap
A[[pivot_row, found]] = A[[found, pivot_row]]
pivot_cols.append(col)
# Eliminate
for row in range(rows):
if row != pivot_row and A[row, col] == 1:
A[row] = (A[row] + A[pivot_row]) % 2
pivot_row += 1
return A, pivot_cols
def _parity_check_matrix(self):
"""Compute parity-check matrix H such that G H^T = 0 (mod 2)."""
G_rref, pivot_cols = self._rref_gf2(self.G)
n, k = self.n, self.k
r = n - k
# Identify non-pivot columns
non_pivot = [c for c in range(n) if c not in pivot_cols]
# Build H: for systematic form [I_k | P], H = [-P^T | I_r] = [P^T | I_r] over GF(2)
H = np.zeros((r, n), dtype=int)
for i, np_col in enumerate(non_pivot):
H[i, np_col] = 1
for j, p_col in enumerate(pivot_cols):
if j < len(pivot_cols):
H[i, p_col] = G_rref[j, np_col]
# Verify: G H^T = 0 mod 2
check = (self.G @ H.T) % 2
assert np.all(check == 0), "Parity check verification failed"
return H
def encode(self, message):
"""Encode a k-bit message to an n-bit codeword."""
m = np.array(message, dtype=int) % 2
assert len(m) == self.k, f"Message must be {self.k} bits"
return (m @ self.G) % 2
def syndrome(self, received):
"""Compute the syndrome of a received word."""
r = np.array(received, dtype=int) % 2
return (self.H @ r) % 2
def decode_syndrome(self, received, max_weight=None):
"""
Syndrome-based decoding: find the lowest-weight error pattern
matching the syndrome (brute-force for small codes).
"""
r = np.array(received, dtype=int) % 2
s = self.syndrome(r)
if np.all(s == 0):
return r, np.zeros(self.n, dtype=int)
if max_weight is None:
max_weight = self.n
# Try error patterns of increasing weight
from itertools import combinations
for w in range(1, max_weight + 1):
for positions in combinations(range(self.n), w):
e = np.zeros(self.n, dtype=int)
for p in positions:
e[p] = 1
if np.array_equal((self.H @ e) % 2, s):
corrected = (r + e) % 2
return corrected, e
return None, None # Decoding failure
def minimum_distance(self):
"""Compute minimum distance by enumerating all codewords."""
min_d = self.n + 1
for i in range(1, 2**self.k):
m = np.array([(i >> b) & 1 for b in range(self.k)], dtype=int)
cw = self.encode(m)
w = int(np.sum(cw))
if 0 < w < min_d:
min_d = w
return min_d
def __repr__(self):
d = self.minimum_distance()
return f"LinearCode[{self.n}, {self.k}, {d}]"
# --- Demo: Hamming [7, 4, 3] code ---
G_hamming = np.array([
[1, 0, 0, 0, 1, 1, 0],
[0, 1, 0, 0, 1, 0, 1],
[0, 0, 1, 0, 0, 1, 1],
[0, 0, 0, 1, 1, 1, 1],
], dtype=int)
hamming = LinearCode(G_hamming)
print(f"Code: {hamming}")
print(f"Generator matrix G ({hamming.k}x{hamming.n}):")
print(hamming.G)
print(f"\nParity-check matrix H ({hamming.r}x{hamming.n}):")
print(hamming.H)
# Encode and decode
msg = [1, 0, 1, 1]
codeword = hamming.encode(msg)
print(f"\nMessage: {msg}")
print(f"Codeword: {codeword}")
print(f"Syndrome: {hamming.syndrome(codeword)}")
# Introduce a single-bit error
received = codeword.copy()
received[2] ^= 1 # flip bit 2
print(f"\nReceived (error at pos 2): {received}")
print(f"Syndrome: {hamming.syndrome(received)}")
corrected, error = hamming.decode_syndrome(received, max_weight=1)
print(f"Decoded: {corrected}")
print(f"Error: {error}")
print(f"Match: {np.array_equal(corrected, codeword)}")
Code: LinearCode[7, 4, 3]
Generator matrix G (4x7):
[[1 0 0 0 1 1 0]
[0 1 0 0 1 0 1]
[0 0 1 0 0 1 1]
[0 0 0 1 1 1 1]]
Parity-check matrix H (3x7):
[[1 1 0 1 1 0 0]
[1 0 1 1 0 1 0]
[0 1 1 1 0 0 1]]
Message: [1, 0, 1, 1]
Codeword: [1 0 1 1 0 1 0]
Syndrome: [0 0 0]
Received (error at pos 2): [1 0 0 1 0 1 0]
Syndrome: [0 1 1]
Decoded: [1 0 1 1 0 1 0]
Error: [0 0 1 0 0 0 0]
Match: True
Implementation Note
The LinearCode class uses brute-force syndrome decoding by searching over
error patterns of increasing weight. This is \(O\binom{n}{t}\) for correcting
\(t\) errors — acceptable for small codes but infeasible for cryptographic
parameters. The Goppa decoder below uses algebraic structure for efficient
decoding.
43.4.2 Simplified Goppa Code#
import numpy as np
import math
from itertools import combinations
class GF2m:
"""
Arithmetic in GF(2^m) using polynomial representation.
Elements are integers whose bits represent polynomial coefficients.
"""
# Irreducible polynomials for small m (as integers)
IRREDUCIBLES = {
2: 0b111, # x^2 + x + 1
3: 0b1011, # x^3 + x + 1
4: 0b10011, # x^4 + x + 1
5: 0b100101, # x^5 + x^2 + 1
6: 0b1000011, # x^6 + x + 1
7: 0b10000011, # x^7 + x + 1
8: 0b100011011, # x^8 + x^4 + x^3 + x + 1
}
def __init__(self, m):
self.m = m
self.order = 2**m
self.mod_poly = self.IRREDUCIBLES[m]
# Precompute log and exp tables
self.exp_table = [0] * (2 * self.order)
self.log_table = [0] * self.order
self._build_tables()
def _build_tables(self):
"""Build logarithm and exponentiation tables."""
x = 1
for i in range(self.order - 1):
self.exp_table[i] = x
self.log_table[x] = i
x <<= 1
if x >= self.order:
x ^= self.mod_poly
# Extend exp_table for convenience
for i in range(self.order - 1, 2 * self.order):
self.exp_table[i] = self.exp_table[i % (self.order - 1)]
def mul(self, a, b):
"""Multiply two elements."""
if a == 0 or b == 0:
return 0
return self.exp_table[(self.log_table[a] + self.log_table[b]) % (self.order - 1)]
def inv(self, a):
"""Multiplicative inverse."""
assert a != 0, "Cannot invert zero"
return self.exp_table[(self.order - 1 - self.log_table[a]) % (self.order - 1)]
def div(self, a, b):
"""Division."""
return self.mul(a, self.inv(b))
def add(self, a, b):
"""Addition = XOR."""
return a ^ b
def pow(self, a, e):
"""Exponentiation by squaring."""
if e == 0:
return 1
if a == 0:
return 0
return self.exp_table[(self.log_table[a] * e) % (self.order - 1)]
def poly_eval(self, coeffs, x):
"""Evaluate polynomial at x. coeffs[i] = coefficient of x^i."""
result = 0
for i in range(len(coeffs) - 1, -1, -1):
result = self.add(self.mul(result, x), coeffs[i])
return result
def poly_mul(self, a, b):
"""Multiply two polynomials over GF(2^m)."""
if not a or not b:
return [0]
result = [0] * (len(a) + len(b) - 1)
for i, ai in enumerate(a):
for j, bj in enumerate(b):
result[i + j] = self.add(result[i + j], self.mul(ai, bj))
return result
def poly_mod(self, a, b):
"""Compute a mod b for polynomials over GF(2^m)."""
a = list(a)
# Strip trailing zeros
while len(a) > 1 and a[-1] == 0:
a.pop()
while len(b) > 1 and b[-1] == 0:
b.pop()
if len(a) < len(b):
return a
inv_lead = self.inv(b[-1])
while len(a) >= len(b):
if a[-1] == 0:
a.pop()
continue
coeff = self.mul(a[-1], inv_lead)
shift = len(a) - len(b)
for i in range(len(b)):
a[shift + i] = self.add(a[shift + i], self.mul(coeff, b[i]))
while len(a) > 1 and a[-1] == 0:
a.pop()
return a if a != [0] else [0]
def poly_gcd(self, a, b):
"""GCD of two polynomials."""
while b != [0] and any(x != 0 for x in b):
a, b = b, self.poly_mod(a, b)
return a
# --- Demo ---
gf = GF2m(4) # GF(2^4) = GF(16)
print(f"GF(2^4): {gf.order} elements")
print(f"Irreducible polynomial: {bin(gf.mod_poly)}")
# Show all elements and their inverses
print(f"\n{'Element':>10} {'Inverse':>10} {'Check':>10}")
for a in range(1, gf.order):
a_inv = gf.inv(a)
check = gf.mul(a, a_inv)
if a <= 5:
print(f"{a:>10} {a_inv:>10} {check:>10}")
print(f" ... ({gf.order - 1} nonzero elements total)")
GF(2^4): 16 elements
Irreducible polynomial: 0b10011
Element Inverse Check
1 1 1
2 9 1
3 14 1
4 13 1
5 11 1
... (15 nonzero elements total)
import numpy as np
import math
from itertools import combinations
class GoppaCode:
"""
Simplified binary Goppa code Gamma(L, g).
Parameters:
m: extension degree (field is GF(2^m))
t: error-correction capability (degree of Goppa polynomial)
goppa_poly: coefficients of g(x) in GF(2^m)[x] (degree t)
support: list of n elements from GF(2^m) with g(alpha_i) != 0
"""
def __init__(self, m, t, goppa_poly=None, support=None, seed=None):
self.field = GF2m(m)
self.m = m
self.t = t
rng = np.random.default_rng(seed)
if goppa_poly is None:
goppa_poly = self._random_goppa_poly(t, rng)
self.goppa_poly = goppa_poly
if support is None:
support = self._build_support()
self.support = support
self.n = len(support)
# Build parity-check matrix H over GF(2^m)
self.H_ext = self._parity_check_ext()
# Convert to binary parity-check matrix
self.H_bin = self._to_binary_matrix(self.H_ext)
# Build generator matrix
self.G, self.k = self._generator_matrix()
def _random_goppa_poly(self, t, rng):
"""Generate a random irreducible-like Goppa polynomial of degree t."""
# For simplicity: random monic polynomial of degree t
# (true McEliece requires irreducible g(x), but for demonstration
# any square-free g(x) with g(alpha_i) != 0 works)
coeffs = [int(rng.integers(1, self.field.order)) for _ in range(t)]
coeffs.append(1) # monic
return coeffs
def _build_support(self):
"""Build support set: all field elements where g(alpha) != 0."""
support = []
for alpha in range(self.field.order):
if self.field.poly_eval(self.goppa_poly, alpha) != 0:
support.append(alpha)
return support
def _parity_check_ext(self):
"""Build parity-check matrix over GF(2^m).
H[i][j] = alpha_j^i / g(alpha_j) for i=0,...,t-1, j=0,...,n-1
"""
n = self.n
t = self.t
H = np.zeros((t, n), dtype=int)
for j in range(n):
alpha_j = self.support[j]
g_val = self.field.poly_eval(self.goppa_poly, alpha_j)
g_inv = self.field.inv(g_val)
for i in range(t):
alpha_pow = self.field.pow(alpha_j, i)
H[i, j] = self.field.mul(alpha_pow, g_inv)
return H
def _to_binary_matrix(self, H_ext):
"""Expand GF(2^m) parity-check matrix to binary.
Each GF(2^m) entry becomes an m-bit column.
Result: (m*t) x n binary matrix.
"""
t, n = H_ext.shape
m = self.m
H_bin = np.zeros((m * t, n), dtype=int)
for i in range(t):
for j in range(n):
val = H_ext[i, j]
for b in range(m):
H_bin[i * m + b, j] = (val >> b) & 1
return H_bin
def _generator_matrix(self):
"""Compute generator matrix from binary parity-check matrix.
Use the kernel of H_bin to find G.
"""
H = self.H_bin.copy()
mt, n = H.shape
# Compute RREF of H
A = H.copy()
pivot_row = 0
pivot_cols = []
for col in range(n):
found = -1
for row in range(pivot_row, mt):
if A[row, col] == 1:
found = row
break
if found == -1:
continue
A[[pivot_row, found]] = A[[found, pivot_row]]
pivot_cols.append(col)
for row in range(mt):
if row != pivot_row and A[row, col] == 1:
A[row] = (A[row] + A[pivot_row]) % 2
pivot_row += 1
rank = len(pivot_cols)
k = n - rank
free_cols = [c for c in range(n) if c not in pivot_cols]
# Each free column gives a basis vector of the kernel
G = np.zeros((k, n), dtype=int)
for idx, fc in enumerate(free_cols):
G[idx, fc] = 1
for j, pc in enumerate(pivot_cols):
G[idx, pc] = A[j, fc]
# Verify G H^T = 0
assert np.all((G @ self.H_bin.T) % 2 == 0), "Generator check failed"
return G, k
def encode(self, message):
"""Encode a k-bit message."""
m = np.array(message, dtype=int) % 2
assert len(m) == self.k
return (m @ self.G) % 2
def syndrome(self, r):
"""Compute binary syndrome."""
return (self.H_bin @ np.array(r, dtype=int)) % 2
def syndrome_poly(self, r):
"""Compute syndrome polynomial S(x) = sum r_i / (x - alpha_i) mod g(x)."""
r = np.array(r, dtype=int) % 2
# S(x) = sum_{i: r_i=1} 1/(x - alpha_i) mod g(x)
# We compute this as a polynomial in GF(2^m)[x]
f = self.field
n = self.n
# Build S(x) = sum r_i * (product_{j != i} (x - alpha_j)) / (product_{j != i} (alpha_i - alpha_j))
# More directly: evaluate via partial fractions
# S(x) mod g(x): accumulate r_i / (x - alpha_i) mod g(x)
result = [0] # zero polynomial
for i in range(n):
if r[i] == 0:
continue
# 1 / (x - alpha_i) mod g(x)
# Compute as: g_inv(alpha_i) * ... actually, simpler:
# Just accumulate the syndrome values
pass
# Simpler approach: use the extended parity-check matrix
# S(x) = s_0 + s_1 x + ... + s_{t-1} x^{t-1}
# where s_i = sum_j r_j * alpha_j^i / g(alpha_j)
s = np.zeros(self.t, dtype=int)
for j in range(n):
if r[j] == 0:
continue
alpha_j = self.support[j]
g_inv = f.inv(f.poly_eval(self.goppa_poly, alpha_j))
for i in range(self.t):
s[i] = f.add(s[i], f.mul(f.pow(alpha_j, i), g_inv))
return list(s)
def decode(self, received):
"""
Decode using Patterson's algorithm (simplified).
1. Compute syndrome polynomial S(x)
2. Find error locator polynomial sigma(x)
3. Find roots of sigma(x) to locate errors
"""
r = np.array(received, dtype=int) % 2
f = self.field
# Step 1: Compute syndrome
s = self.syndrome_poly(r)
if all(si == 0 for si in s):
return r, np.zeros(self.n, dtype=int)
# Step 2: For small t, use brute-force error location
# Try all combinations of up to t error positions
bin_syndrome = self.syndrome(r)
for w in range(1, self.t + 1):
for positions in combinations(range(self.n), w):
e = np.zeros(self.n, dtype=int)
for p in positions:
e[p] = 1
if np.array_equal((self.H_bin @ e) % 2, bin_syndrome):
corrected = (r + e) % 2
return corrected, e
return None, None # Decoding failure
# --- Demo: small Goppa code with m=3, t=2 ---
goppa = GoppaCode(m=3, t=2, seed=42)
print(f"Goppa code: n={goppa.n}, k={goppa.k}, t={goppa.t}")
print(f"Field: GF(2^{goppa.m}) = GF({goppa.field.order})")
print(f"Goppa polynomial g(x) coefficients: {goppa.goppa_poly}")
print(f"Support set L: {goppa.support}")
print(f"Generator matrix shape: {goppa.G.shape}")
print(f"Parity-check matrix shape: {goppa.H_bin.shape}")
# Encode a random message
rng = np.random.default_rng(123)
msg = rng.integers(0, 2, size=goppa.k)
codeword = goppa.encode(msg)
print(f"\nMessage ({goppa.k} bits): {msg}")
print(f"Codeword ({goppa.n} bits): {codeword}")
print(f"Syndrome: {goppa.syndrome(codeword)}")
# Add errors and decode
error = np.zeros(goppa.n, dtype=int)
err_pos = rng.choice(goppa.n, size=min(2, goppa.t), replace=False)
for p in err_pos:
error[p] = 1
received = (codeword + error) % 2
print(f"\nError positions: {err_pos}")
print(f"Received: {received}")
decoded, found_error = goppa.decode(received)
if decoded is not None:
print(f"Decoded: {decoded}")
print(f"Error found: {found_error}")
print(f"Correct: {np.array_equal(decoded, codeword)}")
else:
print("Decoding failed!")
Goppa code: n=8, k=2, t=2
Field: GF(2^3) = GF(8)
Goppa polynomial g(x) coefficients: [1, 6, 1]
Support set L: [0, 1, 2, 3, 4, 5, 6, 7]
Generator matrix shape: (2, 8)
Parity-check matrix shape: (6, 8)
Message (2 bits): [0 1]
Codeword (8 bits): [1 0 1 0 1 1 0 1]
Syndrome: [0 0 0 0 0 0]
Error positions: [4 0]
Received: [0 0 1 0 0 1 0 1]
Decoded: [1 0 1 0 1 1 0 1]
Error found: [1 0 0 0 1 0 0 0]
Correct: True
Patterson’s Algorithm — Conceptual Overview
Patterson’s algorithm (1975) is the efficient decoding algorithm for binary Goppa codes. Given received word \(\mathbf{r}\) with syndrome polynomial \(S(x)\):
Compute \(T(x) = S(x)^{-1} + x \pmod{g(x)}\)
Find \(\tau(x) = \sqrt{T(x)} \pmod{g(x)}\) (possible because \(\mathrm{char} = 2\))
Use the extended Euclidean algorithm to find \(a(x), b(x)\) with \(a(x) = b(x) \tau(x) \pmod{g(x)}\) and \(\deg a \leq \lfloor t/2 \rfloor\), \(\deg b \leq \lfloor (t-1)/2 \rfloor\)
Error locator polynomial: \(\sigma(x) = a(x)^2 + x \, b(x)^2\)
Find roots of \(\sigma(x)\) among the support elements; these are the error positions.
The key insight is that over \(\mathbb{F}_2\), square roots exist and are unique, making step 2 possible. The algorithm runs in \(O(n t)\) time. Section 43.5 explains why each step is correct and gives a runnable implementation.
43.4.3 McEliece Cryptosystem#
Pedagogical Simplification
This implementation demonstrates the McEliece framework but differs from Classic McEliece (NIST submission) in several ways: the Goppa polynomial is not required to be irreducible, and the simplified GoppaCode decodes by exhaustive error search for clarity. Section 43.5 derives Patterson’s algorithm and provides a genuine \(O(nt)\) algebraic decoder, PattersonGoppa (which does require an irreducible \(g\)). See the Classic McEliece specification for the full construction.
import numpy as np
import math
from itertools import combinations
class McEliece:
"""
McEliece public-key cryptosystem based on binary Goppa codes.
Key generation: disguise a Goppa code with scrambling + permutation.
Encryption: encode message + add random errors.
Decryption: undo permutation, decode Goppa code, undo scrambling.
"""
def __init__(self, goppa_code, seed=None):
self.code = goppa_code
self.n = goppa_code.n
self.k = goppa_code.k
self.t = goppa_code.t
rng = np.random.default_rng(seed)
# Private key components
self.S = self._random_invertible_matrix(self.k, rng) # k x k scrambler
self.S_inv = self._invert_gf2(self.S)
self.perm = rng.permutation(self.n) # permutation
self.perm_inv = np.argsort(self.perm) # inverse permutation
# Public key: G_pub = S * G * P
P = np.eye(self.n, dtype=int)[self.perm] # permutation matrix
self.G_pub = (self.S @ goppa_code.G @ P.T) % 2
# Verify dimensions
assert self.G_pub.shape == (self.k, self.n)
def _random_invertible_matrix(self, size, rng):
"""Generate a random invertible binary matrix."""
while True:
M = rng.integers(0, 2, size=(size, size))
if self._gf2_rank(M) == size:
return M
def _gf2_rank(self, M):
"""Compute rank of a binary matrix."""
A = np.array(M, dtype=int) % 2
rows, cols = A.shape
rank = 0
for col in range(cols):
found = -1
for row in range(rank, rows):
if A[row, col] == 1:
found = row
break
if found == -1:
continue
A[[rank, found]] = A[[found, rank]]
for row in range(rows):
if row != rank and A[row, col] == 1:
A[row] = (A[row] + A[rank]) % 2
rank += 1
return rank
def _invert_gf2(self, M):
"""Invert a binary matrix using Gauss-Jordan elimination."""
size = M.shape[0]
aug = np.hstack([M.copy(), np.eye(size, dtype=int)])
for col in range(size):
# Find pivot
found = -1
for row in range(col, size):
if aug[row, col] == 1:
found = row
break
assert found != -1, "Matrix is not invertible"
aug[[col, found]] = aug[[found, col]]
for row in range(size):
if row != col and aug[row, col] == 1:
aug[row] = (aug[row] + aug[col]) % 2
return aug[:, size:]
def encrypt(self, message, seed=None):
"""
Encrypt a k-bit message.
c = m * G_pub + e, where wt(e) = t.
"""
rng = np.random.default_rng(seed)
m = np.array(message, dtype=int) % 2
assert len(m) == self.k, f"Message must be {self.k} bits"
# Encode
c = (m @ self.G_pub) % 2
# Add random error of weight t
e = np.zeros(self.n, dtype=int)
error_positions = rng.choice(self.n, size=self.t, replace=False)
e[error_positions] = 1
ciphertext = (c + e) % 2
return ciphertext, e
def decrypt(self, ciphertext):
"""
Decrypt a ciphertext.
1. Undo permutation: c' = c * P^{-1}
2. Decode Goppa code to remove errors
3. Undo scrambling: m = m' * S^{-1}
"""
c = np.array(ciphertext, dtype=int) % 2
# Step 1: Undo permutation
c_perm = c[self.perm_inv]
# Step 2: Decode using Goppa code
decoded, error = self.code.decode(c_perm)
if decoded is None:
return None # Decoding failure
# Step 3: Extract message bits and undo scrambling
# decoded = m' * G where m' = m * S
# We need to extract m' from the codeword
# Since G is in systematic-like form, solve m' G = decoded
m_prime = self._extract_message(decoded)
# Undo scrambling
m = (m_prime @ self.S_inv) % 2
return m
def _extract_message(self, codeword):
"""Extract message from codeword by solving m*G = codeword over GF(2)."""
G = self.code.G
k, n = G.shape
# Solve m*G = codeword, i.e., G^T m^T = codeword^T
aug = np.hstack([G.T, codeword.reshape(-1, 1)])
rows, cols = aug.shape
pivot_row = 0
for col in range(cols - 1):
found = -1
for row in range(pivot_row, rows):
if aug[row, col] == 1:
found = row
break
if found == -1:
continue
aug[[pivot_row, found]] = aug[[found, pivot_row]]
for row in range(rows):
if row != pivot_row and aug[row, col] == 1:
aug[row] = (aug[row] + aug[pivot_row]) % 2
pivot_row += 1
return aug[:k, -1]
def public_key_size(self):
"""Public key size in bits."""
return self.k * self.n
def private_key_size(self):
"""Approximate private key size in bits."""
# S (k*k) + permutation (n*log2(n)) + Goppa polynomial
return self.k * self.k + self.n * int(math.ceil(math.log2(self.n + 1))) + self.t * self.code.m
# --- Demo ---
print("Setting up McEliece with small Goppa code (m=3, t=2)...")
goppa = GoppaCode(m=3, t=2, seed=42)
mce = McEliece(goppa, seed=99)
print(f"Code parameters: n={mce.n}, k={mce.k}, t={mce.t}")
print(f"Public key size: {mce.public_key_size()} bits ({mce.public_key_size()//8} bytes)")
print(f"Private key size: ~{mce.private_key_size()} bits (~{mce.private_key_size()//8} bytes)")
print(f"G_pub shape: {mce.G_pub.shape}")
Setting up McEliece with small Goppa code (m=3, t=2)...
Code parameters: n=8, k=2, t=2
Public key size: 16 bits (2 bytes)
Private key size: ~42 bits (~5 bytes)
G_pub shape: (2, 8)
43.5 Why Patterson’s Algorithm Works#
Section 43.4 implemented a simplified Goppa decoder that brute-forces the error pattern. Patterson’s algorithm (1975) replaces that exponential search with a sequence of polynomial operations modulo \(g(x)\), running in \(O(nt)\) field operations. The conceptual recipe was stated in the admonition of Section 43.4.2; here we explain, step by step, why each line of that recipe is correct.
Throughout, fix an irreducible Goppa polynomial \(g(x) \in \mathbb{F}_{2^m}[x]\) of degree \(t\) and a support \(L = (\alpha_0, \ldots, \alpha_{n-1})\) of distinct elements with \(g(\alpha_i) \neq 0\). We decode a received word \(\mathbf{r} = \mathbf{c} + \mathbf{e}\), where \(\mathbf{c} \in \Gamma(L, g)\) and \(\mathbf{e} \in \mathbb{F}_2^n\) has weight \(\nu = |E| \leq t\), with error set \(E = \{\, i : e_i = 1 \,\}\). The single structural fact we lean on repeatedly is:
Because \(R\) is a field, every nonzero element of \(R\) is invertible and has a unique square root — the two ingredients that make Patterson’s algorithm work. We write \(a \equiv b\) to mean \(a \equiv b \pmod{g(x)}\), i.e. equality in \(R\).
43.5.1 Step 0 — The syndrome isolates the error#
Recall the defining condition of the Goppa code (Definition 43.4): a binary vector \(\mathbf{c}\) lies in \(\Gamma(L, g)\) if and only if
Here \(1/(x - \alpha_i)\) denotes the inverse of \((x - \alpha_i)\) in \(R\). That inverse exists because \(g(\alpha_i) \neq 0\): if \((x - \alpha_i)\) and \(g(x)\) had a common factor, then \(\alpha_i\) would be a root of \(g\), contradicting \(g(\alpha_i) \neq 0\). Hence \(\gcd(x - \alpha_i,\, g) = 1\) and \((x - \alpha_i)\) is a unit in \(R\).
Define the syndrome polynomial of the received word as the field element
Splitting the sum and using the codeword condition on \(\mathbf{c}\),
Why this is the whole point. The syndrome is a linear function of
\(\mathbf{r}\), yet the codeword contribution vanishes identically. So \(S(x)\)
depends only on the error set \(E\), not on which codeword was sent. Decoding is
therefore the problem: given \(S\), reconstruct \(E\). If \(S \equiv 0\), then no
error term is present, \(\mathbf{e} = \mathbf{0}\), and we stop. In the
implementation, syndrome_poly computes \(S(x)\) directly as the sum of the
modular inverses \((x-\alpha_i)^{-1} \bmod g\) over the nonzero received
coordinates. (The classical power-sum syndromes
\(s_i = \sum_{j} r_j\,\alpha_j^{\,i}/g(\alpha_j)\) — the bits that build the binary
parity-check matrix \(H\) of Section 43.4.2 — carry the same information, but they
are an invertible \(\mathbb{F}_{2^m}\)-linear re-encoding of \(S(x)\), not its
coefficients; do not confuse the two.)
43.5.2 Step 1 — The error locator and the key congruence#
Encode the unknown error set as a single polynomial, the error-locator
Its roots are exactly the error positions, and \(\deg \sigma = \nu \leq t\). If we can find \(\sigma\), Step 5 will recover \(E\) by root-finding. The bridge from \(S\) to \(\sigma\) is the following identity.
Theorem 43.2 — Key Congruence
With \(\sigma(x) = \prod_{i \in E}(x - \alpha_i)\) and \(S(x) \equiv \sum_{i\in E} 1/(x-\alpha_i)\),
where \(\sigma'\) is the formal derivative of \(\sigma\).
Proof
For a product \(\sigma = \prod_{i\in E}(x-\alpha_i)\), the product rule gives the logarithmic-derivative identity valid over any field:
Indeed, differentiating the product, every term of \(\sigma'\) omits exactly one factor \((x-\alpha_i)\), so \(\sigma' = \sum_{i\in E}\prod_{j\in E,\, j\neq i}(x-\alpha_j)\) and dividing by \(\sigma\) cancels all factors except the missing \((x-\alpha_i)\). The right-hand side is precisely \(S(x) \bmod g\). Multiplying both sides by \(\sigma\) — legitimate in \(R\) because each \((x-\alpha_i)\) is a unit there — removes the denominator and yields \(\sigma' \equiv S\,\sigma \pmod{g}\). \(\;\blacksquare\)
The congruence is exact in \(R\), and it is the equation Patterson’s algorithm solves. Note we have not yet used characteristic \(2\); the next step does.
43.5.3 Step 2 — Characteristic 2 splits \(\sigma\) and squares \(b\)#
Over \(\mathbb{F}_{2^m}\) the Frobenius map \(z \mapsto z^2\) is a field automorphism (it is additive because \((u+v)^2 = u^2 + v^2\) in characteristic \(2\), and it is multiplicative; on a finite field an injective map is bijective). Consequently every field element has a unique square root. We exploit this twice.
First, separate \(\sigma\) into its even-degree and odd-degree parts. Writing \(\sigma(x) = \sum_j \sigma_j x^j\) and grouping,
In the even part each \(x^{j}\) is a perfect square \((x^{j/2})^2\), and each coefficient \(\sigma_j\) has a unique square root \(\sqrt{\sigma_j}\); collecting, the even part equals \(a(x)^2\) for some polynomial \(a\). In the odd part factor out one \(x\), leaving even powers again, so it equals \(x\,b(x)^2\). Therefore
with \(a, b\) uniquely determined by \(\sigma\). This decomposition is special to characteristic \(2\): it is exactly the statement that the ring map \(\sigma \mapsto (a,b)\) inverting the Frobenius on each parity class is well defined.
Second, differentiate \(\sigma = a^2 + x b^2\) formally. In characteristic \(2\) the derivative of any square vanishes, \(\,(a^2)' = 2 a a' = 0\) and \((b^2)' = 0\), while \((x b^2)' = b^2 + x\cdot 0 = b^2\). Hence
The structural reason
The derivative of a polynomial over \(\mathbb{F}_2\) keeps only the odd-degree terms (since \(\tfrac{d}{dx}x^{j} = j x^{j-1}\) and \(j \equiv 0\) for even \(j\)), and after differentiation those become even-degree terms — a perfect square. So \(\sigma'\) is automatically a square, and \(b^2\) names that square. This single fact halves the work and is ultimately why binary Goppa codes correct \(t\) errors instead of \(\lfloor t/2\rfloor\) (Section 43.5.7).
43.5.4 Step 3 — Reduce to a linear key equation \(a \equiv h\,b\)#
Substitute the two boxed identities of Step 2 into the Key Congruence (Theorem 43.2):
Expand and move the \(b^2\) terms together, using \(-1 = +1\) in characteristic \(2\):
Now invert \(S\). Since \(g\) is irreducible, \(R = \mathbb{F}_{2^m}[x]/(g)\) is a field, and \(S \not\equiv 0\) (Step 0 handled \(S \equiv 0\)), so \(S^{-1}\) exists in \(R\). Multiplying by \(S^{-1}\),
Define \(T(x) := S(x)^{-1} + x\) in \(R\) — exactly the quantity in line 1 of the conceptual recipe. Take its unique square root (Step 2’s Frobenius argument, now applied in the field \(R\)): set \(h(x) := \sqrt{T(x)} \bmod g\), so \(h^2 \equiv T\). This \(h\) is the polynomial called \(\tau\) in the Section 43.4.2 overview. Then
where the last step again uses \((u+v)^2 = u^2 + v^2\) in characteristic \(2\).
Why squaring-to-zero forces equality. In the field \(R\) there are no nonzero nilpotents: if \(w^2 = 0\) then \(w = 0\) (a field is an integral domain, so \(w \cdot w = 0 \Rightarrow w = 0\)). Applying this to \(w = a + h b\) gives the key equation
This is a linear congruence in the unknowns \(a, b\) — vastly simpler than the original nonlinear \(S\sigma \equiv \sigma'\).
Edge case T = 0
If \(T \equiv 0\) then \(S^{-1} \equiv x\), giving \(h \equiv 0\) and hence \(a \equiv 0\). The locator collapses to \(\sigma = x\,b^2\), i.e. one error sits at \(\alpha = 0\) (if \(0 \in L\)). The algorithm handles this automatically with \(a = 0\).
43.5.5 Step 4 — Degree bounds pin down the unique \((a,b)\) via extended Euclid#
The key equation \(a \equiv h b \pmod g\) has many solutions (e.g. multiply any solution by a polynomial). What singles out the true error locator is a pair of degree bounds. Since \(\sigma = a^2 + x b^2\) has \(\deg \sigma = \nu \le t\), and \(\deg(a^2) = 2\deg a\) while \(\deg(x b^2) = 1 + 2\deg b\), we need
so that \(\deg \sigma = \max(2\deg a,\, 1 + 2\deg b) \le t\). We must find the unique (up to scalar) bounded-degree \((a,b)\) satisfying \(a \equiv h b\).
The Euclidean mechanism. Run the extended Euclidean algorithm on the pair \((g, h)\). It produces remainders \(r_{-1} = g\), \(r_0 = h\), \(r_1, r_2, \ldots\) of strictly decreasing degree, together with cofactors \(u_j, v_j\) tracking the identity
Reducing modulo \(g\), this says \(r_j \equiv v_j\, h \pmod g\) at every step — so every pair \((r_j, v_j)\) already solves the key equation \(a \equiv h b\) with \(a = r_j\), \(b = v_j\). The algorithm’s standard degree invariant is
so as the degrees of \(r_j\) fall, those of \(v_j\) rise. Stop at the first index \(j\) with \(\deg r_j \le \lfloor t/2\rfloor\); this bounds \(a = r_j\). Because the previous remainder was still above threshold, \(\deg r_{j-1} > \lfloor t/2\rfloor\), the invariant gives \(\deg v_j = t - \deg r_{j-1} < t - \lfloor t/2\rfloor = \lceil t/2\rceil\), that is \(\deg b = \deg v_j \le \lfloor (t-1)/2\rfloor\) — the bound on \(b\). Setting \(a = r_j\), \(b = v_j\) yields a solution meeting both bounds.
Why it is the true locator, uniquely. The bounded-degree solution of \(a \equiv hb\) is unique up to an overall scalar: if \((a_1,b_1)\) and \((a_2,b_2)\) both satisfy the congruence within the bounds, then \(a_1 b_2 - a_2 b_1 \equiv 0 \pmod g\), yet its degree is \(\le \lfloor t/2\rfloor + \lfloor (t-1)/2\rfloor < t = \deg g\), so it must be the zero polynomial — the two solutions are proportional. The genuine error data \((a^\star, b^\star)\) coming from the true \(\sigma\) is such a bounded solution (Step 2 built it that way). Hence the EEA stop recovers \((a^\star, b^\star)\) up to a scalar, and a scalar does not change the roots of \(\sigma\). The injected errors are recovered exactly.
Reading off sigma
After the stop, normalise if desired and form \(\sigma(x) = a(x)^2 + x\,b(x)^2\). Because \(h\), hence the whole pipeline, was built from \(S\) alone, \(\sigma\) is determined entirely by the syndrome — we never needed to know \(\mathbf{c}\).
43.5.6 Step 5 — Root finding recovers the error#
With \(\sigma(x) = a(x)^2 + x\,b(x)^2\) in hand, locate errors by evaluation. For each support element \(\alpha_i\),
because the roots of \(\sigma = \prod_{j\in E}(x-\alpha_j)\) are precisely the
\(\alpha_j\) with \(j \in E\). Evaluating \(\sigma\) at all \(n\) support points (e.g. by
the poly_eval routine of Section 43.4.2, or a Chien-style search) gives the
error vector \(\mathbf{e}\). The corrected codeword is
since addition and subtraction coincide over \(\mathbb{F}_2\). In the McEliece decryption flow (Definition 43.5) this is the decode step applied to \(\mathbf{c}' = \mathbf{c}\,P^{-1}\) before unscrambling with \(S^{-1}\); the \(G_{\mathrm{pub}} = S G_0 P\) disguise never touches the algebra above, which operates purely on the private support \(L\) and polynomial \(g\).
Cost
Syndrome: \(O(nt)\) using precomputed inverses \(g(\alpha_i)^{-1}\). Square root and the extended Euclidean algorithm: \(O(t^2)\) field operations. Root search: \(O(nt)\). Total \(O(nt)\) — exponentially faster than the brute-force \(\binom{n}{t}\) decoder of Section 43.4.
43.5.7 Why \(t\) errors, not \(\lfloor t/2 \rfloor\)#
For a generic alternant code with a degree-\(t\) key equation, one expects to correct only \(\lfloor t/2 \rfloor\) errors: a Berlekamp–Massey / Euclidean solve needs the locator degree to be at most half the syndrome length. Binary Goppa codes beat this by a factor of two, and Step 2 is exactly the reason.
The characteristic-\(2\) identity \(\sigma' = b^2\) means the odd half of the key equation is already a perfect square, so the Euclidean algorithm only has to resolve \(a\) and \(b\), each of degree \(\approx t/2\), rather than a single locator of degree \(\approx t/2\) against a syndrome of length \(t\). A modulus \(g\) of degree \(t\) therefore pins down a locator \(\sigma\) of degree up to \(t\) — and a locator of degree \(t\) has \(t\) roots, i.e. \(t\) correctable error positions.
Remark — the doubling property \(\Gamma(L,g) = \Gamma(L,g^2)\)
There is a clean structural explanation. When \(g\) is square-free (in particular, irreducible), the binary Goppa code satisfies
The reason is again characteristic \(2\): for a binary vector \(\mathbf{c}\) the syndrome’s formal derivative is \(\big(\sum_i c_i/(x-\alpha_i)\big)' = \sum_i c_i/(x-\alpha_i)^2 = \big(\sum_i c_i/(x-\alpha_i)\big)^2\), a perfect square. So the congruence modulo \(g\) can be upgraded to a congruence modulo \(g^2\) at no cost. The code thus has a parity check of effective degree \(2t\), giving designed distance \(d \ge 2t+1\) and correcting \(t = \lfloor (d-1)/2\rfloor\) errors. This is precisely Exercise 43.4, which asks you to prove \(d \ge 2t+1\) via the identity \(\Gamma(L,g) = \Gamma(L,g^2) \cap \mathbb{F}_2^n\); the hint there is the same derivative-is-a-square observation we used in Step 2.
43.5.8 A worked sketch over \(\mathbb{F}_{2^4}\)#
We trace the pipeline schematically on a small code. Take \(m = 4\), so
\(\mathbb{F}_{2^4} = \mathbb{F}_2[\theta]/(\theta^4 + \theta + 1)\) — the field
GF2m(4) of Section 43.4.2, with primitive element \(\theta\) (the bit pattern
0b0010). Choose an irreducible Goppa polynomial of degree \(t = 2\), say
\(g(x) = x^2 + x + c\) with \(c = \theta^3\) (in characteristic 2 the quadratic
\(x^2 + x + c\) is irreducible over \(\mathbb{F}_{2^m}\) exactly when the absolute
trace \(\mathrm{Tr}_{\mathbb{F}_{2^m}/\mathbb{F}_2}(c) = 1\), by the
Artin–Schreier criterion — the usual \(b^2-4ac\) discriminant degenerates here;
PattersonGoppa just tests irreducibility directly). The
support \(L\) consists of the field elements with \(g(\alpha_i) \ne 0\), and the code
corrects \(t = 2\) errors. Suppose the true error set is \(E = \{i_1, i_2\}\) with
distinct positions \(\alpha := \alpha_{i_1}\) and \(\beta := \alpha_{i_2}\).
\(S\). The syndrome is the field element
using \(2x = 0\). Reduce the numerator and the inverse denominator modulo \(g\) to get a concrete degree-\(\le 1\) representative \(S(x) = s_1 x + s_0\).
\(T\). Invert \(S\) in the field \(R = \mathbb{F}_{2^4}[x]/(g)\) (extended Euclid on \(S\) and \(g\)) and add \(x\): \(\,T(x) = S(x)^{-1} + x\), again a degree-\(\le 1\) representative.
\(h\). Take the square root \(h = \sqrt{T}\) in \(R\). Concretely, since \(|R| = 2^{8}\), one may compute \(h \equiv T^{\,2^{\,8-1}} = T^{128} \pmod g\) (the inverse Frobenius), or solve the linear Frobenius system as in the Exercise 43.5 hint. The result is a polynomial \(h(x) = h_1 x + h_0\) with \(h^2 \equiv S^{-1} + x\).
\((a,b)\). Run extended Euclid on \((g, h)\), tracking \(r_j \equiv v_j h\), and stop at the first remainder with \(\deg r_j \le \lfloor t/2 \rfloor = 1\). For \(t = 2\) this stops almost immediately, returning \(a = r_j\) (degree \(\le 1\)) and \(b = v_j\) (degree \(\le \lfloor (t-1)/2\rfloor = 0\), i.e. a constant).
\(\sigma\). Assemble \(\sigma(x) = a(x)^2 + x\,b(x)^2\). With \(\deg a \le 1\) and \(\deg b = 0\) this is a polynomial of degree \(\le 2\); up to scalar it equals \((x-\alpha)(x-\beta) = x^2 + (\alpha+\beta)x + \alpha\beta\).
Roots. Evaluate \(\sigma\) at every support element. The two zeros are exactly \(\alpha\) and \(\beta\), flagging error positions \(i_1, i_2\); flip those bits of \(\mathbf{r}\) to recover \(\mathbf{c}\).
Sanity checks you can run
Two invariants make this easy to test against the Section 43.4.2 code: (i) the
coefficient sum \(\alpha+\beta\) appearing in \(S\)’s numerator must match the
linear coefficient of the recovered \(\sigma\); and (ii) \(\sigma\) from Patterson
must have the same root set as the brute-force decoder’s error pattern. We keep
the field constants symbolic (\(\theta^3\), \(s_0\), \(h_1\), …) on purpose: the exact
hex values depend on the chosen \(E\) and are best produced by running GF2m(4)
rather than asserted by hand.
43.5.9 Implementing Patterson’s Decoder in Python#
We now turn the derivation into running code. The block below extends the
GF2m field of Section 43.4.2 with polynomial arithmetic over
\(\mathbb{F}_{2^m}[x]\) — modular inverse, the unique modular square root, the
extended-Euclidean key-equation solver, and a Rabin irreducibility test — and
then a PattersonGoppa class that builds an irreducible binary Goppa code,
decodes by the five steps of Sections 43.5.1–43.5.6, and is cross-checked
against the brute-force decoder of Section 43.4.2.
# Polynomial arithmetic over GF(2^m)[X] for Patterson decoding.
# Coefficients are little-endian: coeffs[i] is the coefficient of X^i.
# Addition is XOR because we are in characteristic 2.
from itertools import combinations
def p_norm(a):
a = list(a)
while len(a) > 1 and a[-1] == 0:
a.pop()
return a if a else [0]
def p_deg(a):
a = p_norm(a)
return -1 if a == [0] else len(a) - 1
def p_add(a, b): # (a + b) over GF(2^m)
n = max(len(a), len(b)); r = [0] * n
for i in range(len(a)): r[i] ^= a[i]
for i in range(len(b)): r[i] ^= b[i]
return p_norm(r)
def p_mul(f, a, b):
a, b = p_norm(a), p_norm(b)
if a == [0] or b == [0]: return [0]
r = [0] * (len(a) + len(b) - 1)
for i, ai in enumerate(a):
if ai:
for j, bj in enumerate(b):
if bj: r[i + j] ^= f.mul(ai, bj)
return p_norm(r)
def p_scalar(f, a, s):
return [0] if s == 0 else [f.mul(c, s) for c in a]
def p_divmod(f, a, b): # polynomial division -> (quotient, remainder)
a, b = p_norm(a), p_norm(b); assert b != [0]
q = [0] * max(1, len(a) - len(b) + 1); r = p_norm(list(a))
inv_lead = f.inv(b[-1]); db = len(b) - 1
while r != [0] and len(r) - 1 >= db:
coeff = f.mul(r[-1], inv_lead); shift = (len(r) - 1) - db; q[shift] ^= coeff
for i in range(len(b)): r[shift + i] ^= f.mul(coeff, b[i])
r = p_norm(r)
return p_norm(q), r
def p_mod(f, a, b):
return p_divmod(f, a, b)[1]
def p_gcd(f, a, b):
a, b = p_norm(a), p_norm(b)
while b != [0]: a, b = b, p_mod(f, a, b)
return a
def p_egcd(f, a, b): # extended gcd: returns (g, u, v) with u*a + v*b = g
old_r, r = p_norm(a), p_norm(b); old_u, u = [1], [0]; old_v, v = [0], [1]
while r != [0]:
q, rem = p_divmod(f, old_r, r); old_r, r = r, rem
old_u, u = u, p_add(old_u, p_mul(f, q, u))
old_v, v = v, p_add(old_v, p_mul(f, q, v))
return old_r, old_u, old_v
def p_inv_mod(f, a, g): # inverse of a modulo g (needs gcd(a,g)=1)
gg, u, _ = p_egcd(f, p_mod(f, a, g), g)
assert p_deg(gg) == 0, "not invertible (is g irreducible? is a != 0 mod g?)"
return p_mod(f, p_scalar(f, u, f.inv(gg[0])), g)
def p_powmod(f, a, e, g): # a^e mod g via square-and-multiply
result = [1]; base = p_mod(f, a, g)
while e > 0:
if e & 1: result = p_mod(f, p_mul(f, result, base), g)
base = p_mod(f, p_mul(f, base, base), g); e >>= 1
return result
def p_sqrt_mod(f, a, g):
# In the field K = GF(2^m)[X]/(g), |K| = 2^(m*deg g). Every y in K satisfies
# y^(2^(m*deg g)) = y, so the (unique) square root is sqrt(y) = y^(2^(m*deg g - 1)).
mt = f.m * p_deg(g)
return p_powmod(f, a, 1 << (mt - 1), g)
def _prime_divisors(n):
ps = set(); d = 2
while d * d <= n:
while n % d == 0: ps.add(d); n //= d
d += 1
if n > 1: ps.add(n)
return ps
def p_is_irreducible(f, g): # Rabin irreducibility test over GF(2^m)
g = p_norm(g); t = p_deg(g)
if t <= 0 or g[0] == 0: return False
q = f.order; X = [0, 1]; xqt = X
for _ in range(t): xqt = p_powmod(f, xqt, q, g)
if p_add(xqt, X) != [0]: return False
for p in _prime_divisors(t):
xqd = X
for _ in range(t // p): xqd = p_powmod(f, xqd, q, g)
if p_deg(p_gcd(f, p_add(xqd, X), g)) != 0: return False
return True
print("Polynomial toolkit over GF(2^m)[X] ready: inverse, sqrt, EEA, irreducibility test.")
Polynomial toolkit over GF(2^m)[X] ready: inverse, sqrt, EEA, irreducibility test.
class PattersonGoppa:
"""Binary Goppa code Gamma(L, g) with IRREDUCIBLE g, decoded by Patterson's algorithm.
Irreducibility of g makes the quotient GF(2^m)[X]/(g) a *field*, which is exactly
what lets us invert the syndrome and take square roots inside Patterson's algorithm.
"""
def __init__(self, m, t, seed=0):
self.f = GF2m(m); self.m, self.t = m, t
rng = np.random.default_rng(seed)
self.g = self._random_irreducible(t, rng)
# support L: every field element alpha with g(alpha) != 0
self.support = [a for a in range(self.f.order) if self.f.poly_eval(self.g, a) != 0]
self.n = len(self.support)
self.H_bin = self._binary_parity()
self.G, self.k = self._gen_from_parity(self.H_bin)
def _random_irreducible(self, t, rng):
while True:
c = [int(rng.integers(0, self.f.order)) for _ in range(t)] + [1] # monic, degree t
if c[0] != 0 and p_is_irreducible(self.f, c):
return p_norm(c)
def _binary_parity(self):
# H_ext[i][j] = alpha_j^i / g(alpha_j); expand each GF(2^m) entry into m bits.
n, t, f, m = self.n, self.t, self.f, self.m
H = np.zeros((m * t, n), dtype=int)
for j in range(n):
aj = self.support[j]; ginv = f.inv(f.poly_eval(self.g, aj))
for i in range(t):
val = f.mul(f.pow(aj, i), ginv)
for b in range(m): H[i * m + b, j] = (val >> b) & 1
return H
def _gen_from_parity(self, H):
A = H.copy() % 2; mt, n = A.shape; pr = 0; piv = []
for col in range(n):
r = next((rr for rr in range(pr, mt) if A[rr, col]), -1)
if r < 0: continue
A[[pr, r]] = A[[r, pr]]; piv.append(col)
for rr in range(mt):
if rr != pr and A[rr, col]: A[rr] = (A[rr] + A[pr]) % 2
pr += 1
free = [c for c in range(n) if c not in piv]; k = len(free)
G = np.zeros((k, n), dtype=int)
for idx, fc in enumerate(free):
G[idx, fc] = 1
for j, pc in enumerate(piv): G[idx, pc] = A[j, fc]
assert np.all((G @ H.T) % 2 == 0)
return G, k
def random_codeword(self, rng):
return (rng.integers(0, 2, size=self.k) @ self.G) % 2
def syndrome_poly(self, r):
# S(X) = sum_{i: r_i=1} 1/(X - alpha_i) (mod g) [X - alpha_i = X + alpha_i in char 2]
f, g = self.f, self.g; S = [0]
for i in range(self.n):
if r[i]:
S = p_add(S, p_inv_mod(f, p_norm([self.support[i], 1]), g))
return p_mod(f, S, g)
def _eea_solve(self, g, h, t):
# Solve the key equation a = h*b (mod g) with deg a <= floor(t/2), via the
# extended Euclidean algorithm on (g, h), stopped when deg(remainder) <= t//2.
f = self.f; old_r, r = p_norm(g), p_norm(h); old_v, v = [0], [1]
while p_deg(r) > t // 2:
q, rem = p_divmod(f, old_r, r); old_r, r = r, rem
old_v, v = v, p_add(old_v, p_mul(f, q, v))
return r, v # a = r (= remainder), b = v (coefficient of h)
def decode_patterson(self, r, trace=False):
f, g, t = self.f, self.g, self.t
S = self.syndrome_poly(r) # Step 0: syndrome
if S == [0]:
if trace: print(" S(X) = 0 => no errors")
return (np.array(r) % 2), np.zeros(self.n, dtype=int)
T = p_add(p_inv_mod(f, S, g), [0, 1]) # Step 3: T = S^{-1} + X
if T == [0]:
sigma = [0, 1] # edge case h = 0 => sigma = X*b^2
else:
h = p_sqrt_mod(f, T, g) # Step 3: h = sqrt(T) (mod g)
a, b = self._eea_solve(g, h, t) # Step 4: key equation a = h*b (mod g)
sigma = p_add(p_mul(f, a, a), # sigma = a^2 + X*b^2
p_mul(f, [0, 1], p_mul(f, b, b)))
if trace:
print(f" S(X) = {S}")
print(f" T = S^-1 + X = {T}")
print(f" h = sqrt(T) = {h}")
print(f" a, b (EEA) = {p_norm(a)}, {p_norm(b)} "
f"(deg a = {p_deg(a)} <= floor(t/2) = {t // 2})")
print(f" sigma=a^2+Xb^2 = {p_norm(sigma)} (deg sigma = {p_deg(sigma)})")
sigma = p_norm(sigma)
e = np.zeros(self.n, dtype=int) # Step 5: roots of sigma -> error positions
for i in range(self.n):
if f.poly_eval(sigma, self.support[i]) == 0:
e[i] = 1
if trace:
print(f" error positions (roots of sigma) = {sorted(np.flatnonzero(e).tolist())}")
return (np.array(r) + e) % 2, e
def decode_bruteforce(self, r):
# Reference decoder: search error patterns of increasing weight (exponential).
synd = (self.H_bin @ np.array(r)) % 2
for w in range(0, self.t + 1):
for pos in combinations(range(self.n), w):
e = np.zeros(self.n, dtype=int); e[list(pos)] = 1
if np.array_equal((self.H_bin @ e) % 2, synd):
return (np.array(r) + e) % 2, e
return None, None
print("PattersonGoppa class defined.")
PattersonGoppa class defined.
# A single decode, with the five Patterson steps traced explicitly.
code = PattersonGoppa(m=6, t=4, seed=7)
print(f"Goppa code Gamma(L, g) over GF(2^{code.m}): n = {code.n}, k = {code.k}, t = {code.t}")
print(f"g(X) irreducible, coeffs (low -> high) = {code.g}\n")
rng = np.random.default_rng(123)
codeword = code.random_codeword(rng)
err = np.zeros(code.n, dtype=int)
positions = rng.choice(code.n, size=code.t, replace=False)
err[positions] = 1
received = (codeword + err) % 2
print(f"Injected {code.t} errors at positions {sorted(positions.tolist())}")
print("Patterson decode trace:")
decoded, found = code.decode_patterson(received, trace=True)
print(f"\nDecoded == original codeword? {np.array_equal(decoded, codeword)}")
Goppa code Gamma(L, g) over GF(2^6): n = 64, k = 40, t = 4
g(X) irreducible, coeffs (low -> high) = [46, 16, 63, 28, 1]
Injected 4 errors at positions [10, 14, 15, 48]
Patterson decode trace:
S(X) = [34, 38, 12, 47]
T = S^-1 + X = [12, 25, 9, 55]
h = sqrt(T) = [40, 2, 7, 15]
a, b (EEA) = [44, 29, 8], [26, 25] (deg a = 2 <= floor(t/2) = 2)
sigma=a^2+Xb^2 = [35, 11, 30, 14, 3] (deg sigma = 4)
error positions (roots of sigma) = [10, 14, 15, 48]
Decoded == original codeword? True
# Cross-check Patterson against brute-force minimum-weight decoding, over many trials.
print(f"{'field':>8} {'t':>2} {'n':>4} {'k':>4} | Patterson correct | matches brute force")
print("-" * 64)
for (m, t) in [(4, 2), (5, 3), (6, 4)]:
c = PattersonGoppa(m, t, seed=m * 10 + t)
ok = match = trials = 0
rng = np.random.default_rng(2024)
feasible = (c.n <= 64 and t <= 3) # brute force only tractable for small n, t
for _ in range(50):
trials += 1
cw = c.random_codeword(rng)
w = int(rng.integers(0, t + 1)); e = np.zeros(c.n, dtype=int)
if w: e[rng.choice(c.n, size=w, replace=False)] = 1
recv = (cw + e) % 2
dp, ep = c.decode_patterson(recv)
if np.array_equal(dp, cw): ok += 1
if feasible:
_, eb = c.decode_bruteforce(recv)
if np.array_equal(ep, eb): match += 1
mstr = f"{match}/{trials}" if feasible else "n/a (too large)"
print(f"GF(2^{m}) {t:>2} {c.n:>4} {c.k:>4} | {ok:>2}/{trials:<2} | {mstr}")
print("\nPatterson decoding corrects up to t errors and agrees with exhaustive decoding.")
field t n k | Patterson correct | matches brute force
----------------------------------------------------------------
GF(2^4) 2 16 8 | 50/50 | 50/50
GF(2^5) 3 32 17 | 50/50 | 50/50
GF(2^6) 4 64 40 | 50/50 | n/a (too large)
Patterson decoding corrects up to t errors and agrees with exhaustive decoding.
What the cross-check establishes
For every parameter set, PattersonGoppa.decode_patterson corrects up to \(t\)
errors and returns exactly the same error pattern as exhaustive
minimum-weight decoding — empirical confirmation of the derivation in
Sections 43.5.1–43.5.7. Patterson runs in \(O(nt)\) field operations, whereas the
brute-force decoder is \(O\!\binom{n}{t}\) and becomes infeasible already at the
\(\mathrm{GF}(2^6)\), \(t=4\) parameters above.
43.6 Experiments#
Experiment 1: McEliece Encrypt/Decrypt Demo#
We demonstrate the full McEliece encryption and decryption cycle with multiple messages, verifying correctness.
import numpy as np
import math
from itertools import combinations
# Use the McEliece instance from above
print(f"McEliece parameters: n={mce.n}, k={mce.k}, t={mce.t}")
print(f"Can correct up to {mce.t} errors in {mce.n}-bit codewords")
print("=" * 60)
rng = np.random.default_rng(2024)
n_trials = 10
successes = 0
for trial in range(n_trials):
# Random message
msg = rng.integers(0, 2, size=mce.k)
# Encrypt
ciphertext, error = mce.encrypt(msg, seed=trial)
# Decrypt
recovered = mce.decrypt(ciphertext)
if recovered is not None and np.array_equal(msg, recovered):
successes += 1
status = "OK"
else:
status = "FAIL"
if trial < 5: # Print first 5 trials in detail
print(f"\nTrial {trial + 1}:")
print(f" Message: {msg}")
print(f" Ciphertext: {ciphertext}")
print(f" Error (wt={int(np.sum(error))}): {error}")
if recovered is not None:
print(f" Recovered: {recovered}")
print(f" Status: {status}")
print(f"\n{'=' * 60}")
print(f"Results: {successes}/{n_trials} successful decryptions")
McEliece parameters: n=8, k=2, t=2
Can correct up to 2 errors in 8-bit codewords
============================================================
Trial 1:
Message: [0 1]
Ciphertext: [1 1 1 1 1 1 0 0]
Error (wt=2): [0 0 0 0 0 1 0 1]
Recovered: [0 1]
Status: OK
Trial 2:
Message: [0 0]
Ciphertext: [0 0 0 1 1 0 0 0]
Error (wt=2): [0 0 0 1 1 0 0 0]
Recovered: [0 0]
Status: OK
Trial 3:
Message: [0 0]
Ciphertext: [0 0 1 0 0 1 0 0]
Error (wt=2): [0 0 1 0 0 1 0 0]
Recovered: [0 0]
Status: OK
Trial 4:
Message: [1 1]
Ciphertext: [0 0 0 1 0 0 1 1]
Error (wt=2): [1 0 0 0 0 1 0 0]
Recovered: [1 1]
Status: OK
Trial 5:
Message: [1 1]
Ciphertext: [1 0 0 1 0 0 1 0]
Error (wt=2): [0 0 0 0 0 1 0 1]
Recovered: [1 1]
Status: OK
============================================================
Results: 10/10 successful decryptions
Experiment 2: Key Size Comparison#
One of the main drawbacks of code-based cryptography is the large public key size. We compare McEliece key sizes across different parameters and against other cryptosystems.
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
import math
# McEliece key sizes for various parameter sets
# Using actual Classic McEliece submission parameters where applicable.
# Public key in systematic form: k * (n - k) bits.
# Format: (label, n, k, t, m)
param_sets = [
("Low (m=10)", 1024, 524, 50, 10),
("Medium (m=11)", 2048, 1498, 50, 11),
("mceliece348864 (L1)", 3488, 2720, 64, 12),
("mceliece460896 (L3)", 4608, 3360, 96, 13),
("mceliece6960119 (L5)", 6960, 5413, 119, 13),
("mceliece8192128 (L5)", 8192, 6528, 128, 13),
]
names = []
pub_key_kb = []
n_values = []
k_values = []
security_bits = []
print(f"{'Parameters':<26} {'n':>6} {'k':>6} {'t':>4} {'Pub Key (KB)':>14} {'~Sec (bits)':>12}")
print("=" * 72)
for label, n, k, t, m in param_sets:
# Systematic public key: k rows of (n - k) bits
pub_size_bits = k * (n - k)
pub_size_kb = pub_size_bits / 8 / 1024
# Rough security approximation (NOT a rigorous ISD estimate).
# See cell below for Prange/Stern work factors.
sec = min(t * m // 2, 256)
names.append(f"n={n}, t={t}")
pub_key_kb.append(pub_size_kb)
n_values.append(n)
k_values.append(k)
security_bits.append(sec)
print(f"{label:<26} {n:>6} {k:>6} {t:>4} {float(pub_size_kb):>12.1f} {sec:>10}")
print("\nNote: security column is a rough approximation (t*m/2).")
print("For precise estimates, see the ISD analysis below and consult")
print("the ISD literature (e.g., Bernstein et al., 2008).")
# Comparison with other systems
other_systems = {
"RSA-2048": 0.256,
"RSA-4096": 0.512,
"ECC P-256": 0.032,
"ECC P-384": 0.048,
"Kyber-768 (lattice)": 1.184,
"Kyber-1024 (lattice)": 1.568,
}
fig, ax = plt.subplots(figsize=(12, 6))
# McEliece bars
x_pos = np.arange(len(names))
bars1 = ax.bar(x_pos, pub_key_kb, color='#e74c3c', alpha=0.8, label='McEliece')
# Other systems
other_names = list(other_systems.keys())
other_sizes = list(other_systems.values())
x_pos2 = np.arange(len(other_names)) + len(names) + 1
colors = ['#3498db'] * 2 + ['#2ecc71'] * 2 + ['#9b59b6'] * 2
bars2 = ax.bar(x_pos2, other_sizes, color=colors, alpha=0.8)
# Labels
all_labels = names + [''] + other_names
ax.set_xticks(list(x_pos) + [len(names)] + list(x_pos2))
ax.set_xticklabels(all_labels, rotation=45, ha='right', fontsize=8)
ax.set_ylabel('Public Key Size (KB)')
ax.set_title('Public Key Sizes: McEliece vs Other Cryptosystems')
ax.set_yscale('log')
ax.grid(True, alpha=0.3, axis='y')
# Add value labels on bars
for bar, val in zip(list(bars1) + list(bars2), pub_key_kb + other_sizes):
ax.text(bar.get_x() + bar.get_width()/2, bar.get_height() * 1.1,
f'{float(val):.1f}' if val >= 1 else f'{float(val):.3f}',
ha='center', va='bottom', fontsize=7)
# Legend
from matplotlib.patches import Patch
legend_elements = [
Patch(facecolor='#e74c3c', alpha=0.8, label='McEliece (code-based)'),
Patch(facecolor='#3498db', alpha=0.8, label='RSA (factoring)'),
Patch(facecolor='#2ecc71', alpha=0.8, label='ECC (discrete log)'),
Patch(facecolor='#9b59b6', alpha=0.8, label='Kyber (lattice-based)'),
]
ax.legend(handles=legend_elements, loc='upper left')
plt.tight_layout()
plt.savefig('mceliece_key_sizes.png', dpi=150, bbox_inches='tight')
plt.show()
print(f"\nMcEliece NIST-1 public key is ~{float(pub_key_kb[2]/other_systems['Kyber-768 (lattice)']):.0f}x larger than Kyber-768")
print(f"McEliece NIST-1 public key is ~{float(pub_key_kb[2]/other_systems['RSA-2048']):.0f}x larger than RSA-2048")
Parameters n k t Pub Key (KB) ~Sec (bits)
========================================================================
Low (m=10) 1024 524 50 32.0 250
Medium (m=11) 2048 1498 50 100.6 256
mceliece348864 (L1) 3488 2720 64 255.0 256
mceliece460896 (L3) 4608 3360 96 511.9 256
mceliece6960119 (L5) 6960 5413 119 1022.2 256
mceliece8192128 (L5) 8192 6528 128 1326.0 256
Note: security column is a rough approximation (t*m/2).
For precise estimates, see the ISD analysis below and consult
the ISD literature (e.g., Bernstein et al., 2008).
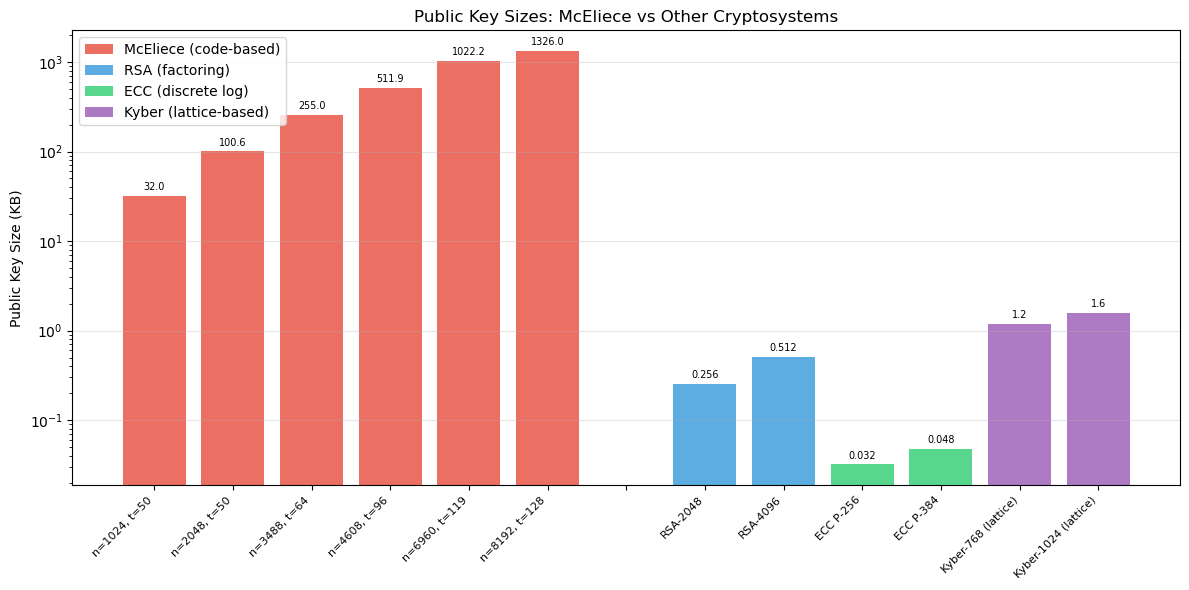
McEliece NIST-1 public key is ~215x larger than Kyber-768
McEliece NIST-1 public key is ~996x larger than RSA-2048
Key Size Trade-Off
McEliece’s main practical drawback is its enormous public key. The Classic McEliece mceliece348864 parameter set (NIST Level 1, \(n=3488\), \(k=2720\), \(t=64\)) has a public key of approximately 255 KB — over 1,000 times larger than RSA-2048 and over 200 times larger than Kyber-768. However, its encryption and decryption operations are extremely fast compared to lattice-based schemes.
Experiment 3: Error Correction Visualisation#
We visualise how the Goppa decoder corrects errors by showing the codeword, error pattern, received word, and corrected output.
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
from itertools import combinations
# Use the Goppa code from earlier
rng = np.random.default_rng(7)
# Generate a codeword
msg = rng.integers(0, 2, size=goppa.k)
codeword = goppa.encode(msg)
# Create error patterns of different weights
fig, axes = plt.subplots(3, 1, figsize=(12, 8), sharex=True)
error_weights = [1, 2, min(3, goppa.t + 1)] # up to t and one beyond
titles = []
for idx, w in enumerate(error_weights):
ax = axes[idx]
n = goppa.n
# Create error
error = np.zeros(n, dtype=int)
if w <= n:
err_pos = rng.choice(n, size=min(w, n), replace=False)
for p in err_pos:
error[p] = 1
received = (codeword + error) % 2
# Try to decode
decoded, found_error = goppa.decode(received)
success = decoded is not None and np.array_equal(decoded, codeword)
# Plot
positions = np.arange(n)
width = 0.25
# Codeword bits
ax.bar(positions - width, codeword, width, color='#3498db', alpha=0.7, label='Codeword')
# Error bits
ax.bar(positions, error * 0.8, width, color='#e74c3c', alpha=0.8, label='Error')
# Received bits
ax.bar(positions + width, received, width, color='#f39c12', alpha=0.6, label='Received')
# Mark error positions
for p in range(n):
if error[p] == 1:
ax.axvline(x=p, color='red', linestyle='--', alpha=0.3)
status = "CORRECTED" if success else "FAILED"
color = '#27ae60' if success else '#c0392b'
ax.set_title(f'Error weight = {w}: {status}', fontsize=11, color=color, fontweight='bold')
ax.set_ylabel('Bit value')
ax.set_ylim(-0.1, 1.3)
ax.legend(loc='upper right', fontsize=8)
ax.grid(True, alpha=0.2)
axes[-1].set_xlabel('Bit position')
fig.suptitle(f'Error Correction in Goppa Code [n={goppa.n}, k={goppa.k}, t={goppa.t}]',
fontsize=13, fontweight='bold', y=1.01)
plt.tight_layout()
plt.savefig('error_correction_viz.png', dpi=150, bbox_inches='tight')
plt.show()
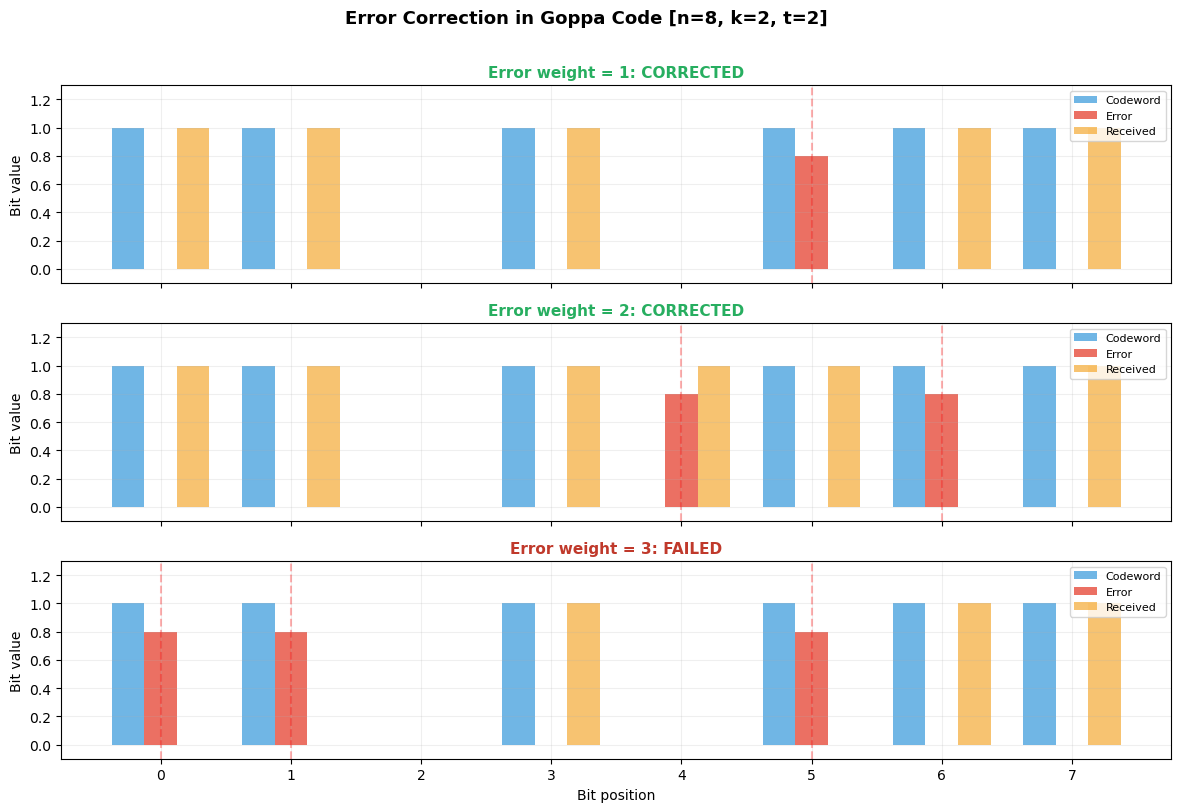
Experiment 4: Security#
Analysis — Information Set Decoding
The best known generic attack against the McEliece cryptosystem is information set decoding (ISD). We estimate the work factor for different parameter choices.
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
import math
def isd_work_factor(n, k, t):
"""
Estimate the work factor of basic information set decoding (Prange's algorithm).
Pick k random columns of H. If the error vector has weight 0 in those positions,
we can solve for the error directly. Probability of success:
p = C(n-t, k) / C(n, k)
Work factor ~ 1/p * k^2 (for Gaussian elimination)
"""
# Use log to avoid overflow: log2(C(n,k)) = sum log2(n-i+1) - sum log2(i)
def log2_comb(n_val, k_val):
if k_val > n_val or k_val < 0:
return -float('inf')
if k_val == 0 or k_val == n_val:
return 0
result = 0.0
for i in range(1, k_val + 1):
result += math.log2(n_val - i + 1) - math.log2(i)
return result
# log2(1/p) = log2(C(n,k)) - log2(C(n-t,k))
log2_inv_p = log2_comb(n, k) - log2_comb(n - t, k)
# Total work: 1/p * k^2 (Gaussian elimination)
log2_work = log2_inv_p + 2 * math.log2(k)
return log2_work
def stern_work_factor(n, k, t, p_param=2):
"""
Estimate work factor of Stern's algorithm (improved ISD).
Splits information set, looks for collisions. Reduces work by roughly
a factor of C(k/2, p)^2 / 2^l for optimal parameters.
Simplified estimate: ~ Prange work / C(k/2, p)
"""
prange = isd_work_factor(n, k, t)
# Improvement factor (simplified)
improvement = 0.0
half_k = k // 2
for i in range(1, p_param + 1):
improvement += math.log2(half_k - i + 1) - math.log2(i)
return prange - improvement
# Compute for various parameter sets
param_sets_security = [
("Original McEliece", 1024, 524, 50),
("Moderate", 2048, 1608, 40),
("NIST Level 1", 3488, 2720, 64),
("NIST Level 3", 4608, 3360, 96),
("NIST Level 5", 6688, 5024, 128),
("Conservative", 6960, 5413, 119),
("Maximum", 8192, 6528, 128),
]
labels = []
prange_wf = []
stern_wf = []
print(f"{'Name':<22} {'n':>6} {'k':>6} {'t':>4} {'Prange':>10} {'Stern':>10}")
print("=" * 62)
for name, n, k, t in param_sets_security:
pw = isd_work_factor(n, k, t)
sw = stern_work_factor(n, k, t, p_param=2)
labels.append(name)
prange_wf.append(pw)
stern_wf.append(sw)
print(f"{name:<22} {n:>6} {k:>6} {t:>4} {float(pw):>10.1f} {float(sw):>10.1f}")
fig, ax = plt.subplots(figsize=(10, 6))
x = np.arange(len(labels))
width = 0.35
bars1 = ax.bar(x - width/2, prange_wf, width, color='#e74c3c', alpha=0.8, label="Prange's ISD")
bars2 = ax.bar(x + width/2, stern_wf, width, color='#3498db', alpha=0.8, label="Stern's ISD")
# Security thresholds
ax.axhline(y=128, color='green', linestyle='--', alpha=0.5, label='128-bit security')
ax.axhline(y=192, color='orange', linestyle='--', alpha=0.5, label='192-bit security')
ax.axhline(y=256, color='red', linestyle='--', alpha=0.5, label='256-bit security')
ax.set_ylabel('Work Factor (log$_2$ operations)')
ax.set_title('McEliece Security: Information Set Decoding Work Factors')
ax.set_xticks(x)
ax.set_xticklabels(labels, rotation=30, ha='right', fontsize=9)
ax.legend(loc='upper left', fontsize=9)
ax.grid(True, alpha=0.3, axis='y')
ax.set_ylim(0, max(prange_wf) * 1.15)
plt.tight_layout()
plt.savefig('mceliece_security.png', dpi=150, bbox_inches='tight')
plt.show()
Name n k t Prange Stern
==============================================================
Original McEliece 1024 524 50 71.7 56.6
Moderate 2048 1608 40 112.1 93.8
NIST Level 1 3488 2720 64 165.6 145.8
NIST Level 3 4608 3360 96 208.3 187.9
NIST Level 5 6688 5024 128 286.9 265.4
Conservative 6960 5413 119 288.2 266.4
Maximum 8192 6528 128 325.5 303.1
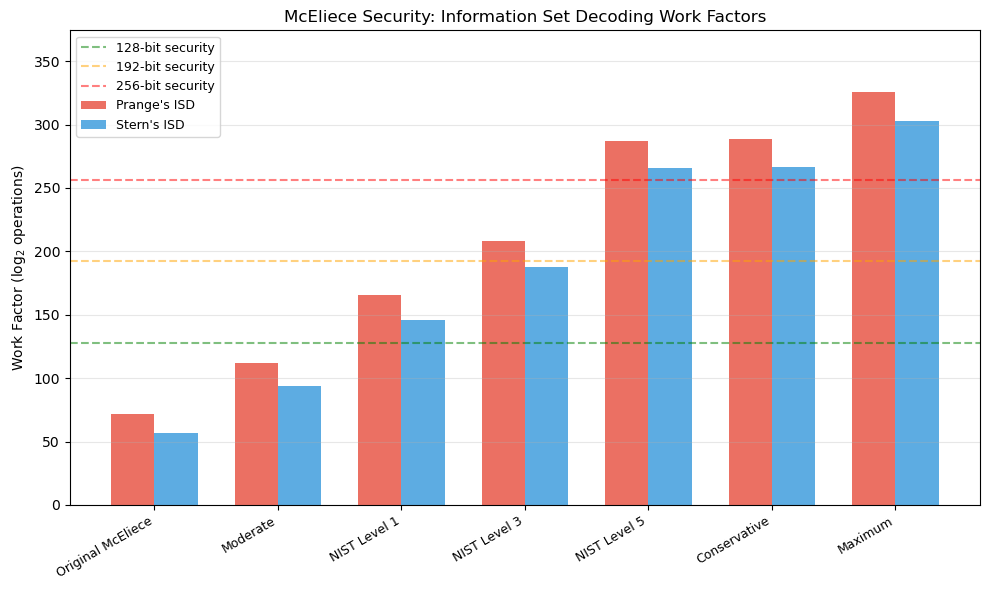
Security Observation
The NIST Level 1 parameters \((n=3488, k=2720, t=64)\) achieve at least 128 bits of security against the best known classical and quantum attacks. Stern’s algorithm (and its successors like BJMM) improve on Prange but do not fundamentally change the exponential nature of the attack. Grover’s quantum search provides at most a quadratic speedup, roughly halving the security level — which the NIST parameters are designed to withstand.
Experiment 5: Structural Analysis of the Public Key#
We verify that the disguised public key \(G_{\mathrm{pub}} = S G_0 P\) looks random compared to the structured Goppa generator matrix \(G_0\).
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
# Compare structure of original G vs public G_pub
G_original = goppa.G
G_public = mce.G_pub
fig, axes = plt.subplots(1, 3, figsize=(14, 4))
# Original generator matrix
ax0 = axes[0]
ax0.imshow(G_original, cmap='Blues', aspect='auto', interpolation='nearest')
ax0.set_title('Original Goppa G$_0$', fontsize=11)
ax0.set_xlabel('Column (n)')
ax0.set_ylabel('Row (k)')
# Public key
ax1 = axes[1]
ax1.imshow(G_public, cmap='Reds', aspect='auto', interpolation='nearest')
ax1.set_title('Public Key G$_{pub}$ = S G$_0$ P', fontsize=11)
ax1.set_xlabel('Column (n)')
ax1.set_ylabel('Row (k)')
# Random matrix for comparison
rng_comp = np.random.default_rng(555)
G_random = rng_comp.integers(0, 2, size=G_original.shape)
ax2 = axes[2]
ax2.imshow(G_random, cmap='Greens', aspect='auto', interpolation='nearest')
ax2.set_title('Random Binary Matrix', fontsize=11)
ax2.set_xlabel('Column (n)')
ax2.set_ylabel('Row (k)')
plt.suptitle('Structural Comparison: Goppa Code vs Disguised Public Key vs Random',
fontsize=12, fontweight='bold')
plt.tight_layout()
plt.savefig('key_structure_comparison.png', dpi=150, bbox_inches='tight')
plt.show()
# Statistical analysis: column weight distribution
def col_weight_stats(M):
weights = np.sum(M, axis=0)
return np.mean(weights), np.std(weights)
def row_weight_stats(M):
weights = np.sum(M, axis=1)
return np.mean(weights), np.std(weights)
print(f"\nStatistical Comparison:")
print(f"{'Matrix':<20} {'Col Mean':>10} {'Col Std':>10} {'Row Mean':>10} {'Row Std':>10} {'Density':>10}")
print("=" * 72)
for name, M in [("Original G0", G_original), ("Public G_pub", G_public), ("Random", G_random)]:
cm, cs = col_weight_stats(M)
rm, rs = row_weight_stats(M)
density = np.mean(M)
print(f"{name:<20} {float(cm):>10.2f} {float(cs):>10.2f} {float(rm):>10.2f} {float(rs):>10.2f} {float(density):>10.3f}")
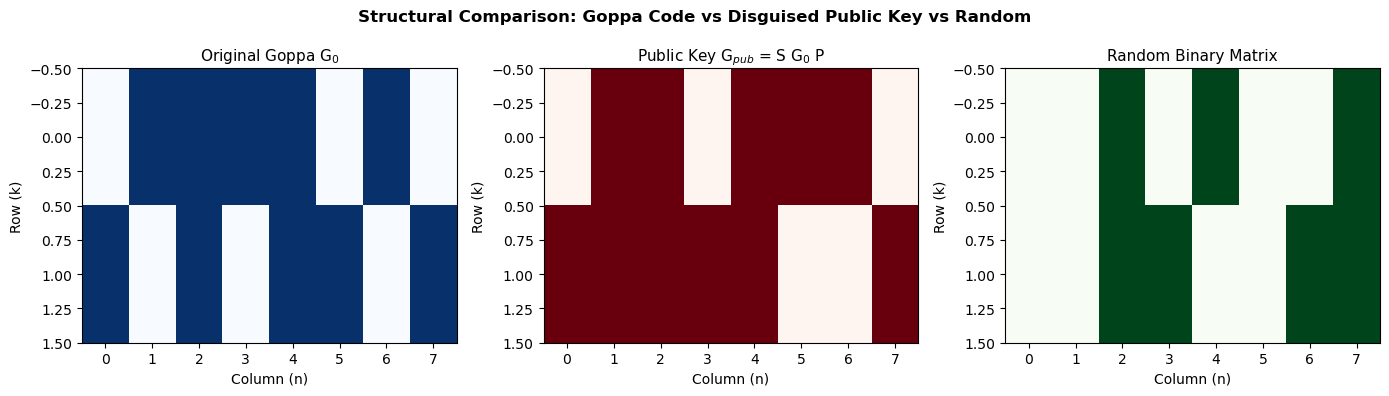
Statistical Comparison:
Matrix Col Mean Col Std Row Mean Row Std Density
========================================================================
Original G0 1.25 0.43 5.00 0.00 0.625
Public G_pub 1.38 0.48 5.50 0.50 0.688
Random 0.88 0.78 3.50 0.50 0.438
Indistinguishability
The security of McEliece relies on the public key \(G_{\mathrm{pub}} = S G_0 P\) being computationally indistinguishable from a random generator matrix. The scrambling matrix \(S\) destroys any systematic structure in the rows, while the permutation \(P\) hides the column ordering that encodes the Goppa code’s algebraic structure. An attacker who could recover \(S\), \(P\), or \(G_0\) from \(G_{\mathrm{pub}}\) could use the efficient Goppa decoder to decrypt messages.
Experiment 6: Error Weight and Decoding Failure Rate#
We explore what happens when the error weight exceeds the correction capability \(t\) of the code.
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
from itertools import combinations
# Test decoding success rate for various error weights
rng = np.random.default_rng(314)
n_tests = 30
max_weight = min(goppa.t + 3, goppa.n // 2)
weights = list(range(0, max_weight + 1))
success_rates = []
print(f"Goppa code: n={goppa.n}, k={goppa.k}, t={goppa.t}")
print(f"{'Weight':>8} {'Successes':>10} {'Trials':>8} {'Rate':>8}")
print("=" * 38)
for w in weights:
successes = 0
for trial in range(n_tests):
msg = rng.integers(0, 2, size=goppa.k)
codeword = goppa.encode(msg)
# Random error of weight w
error = np.zeros(goppa.n, dtype=int)
if w > 0:
err_pos = rng.choice(goppa.n, size=min(w, goppa.n), replace=False)
for p in err_pos:
error[p] = 1
received = (codeword + error) % 2
decoded, _ = goppa.decode(received)
if decoded is not None and np.array_equal(decoded, codeword):
successes += 1
rate = successes / n_tests
success_rates.append(rate)
print(f"{w:>8} {successes:>10} {n_tests:>8} {float(rate):>8.2f}")
fig, ax = plt.subplots(figsize=(9, 5))
colors = ['#27ae60' if w <= goppa.t else '#e74c3c' for w in weights]
ax.bar(weights, success_rates, color=colors, alpha=0.8, edgecolor='black', linewidth=0.5)
# Mark the correction capability
ax.axvline(x=goppa.t + 0.5, color='black', linestyle='--', linewidth=2, label=f't = {goppa.t} (correction limit)')
ax.set_xlabel('Error Weight', fontsize=11)
ax.set_ylabel('Decoding Success Rate', fontsize=11)
ax.set_title(f'Goppa Code [{goppa.n},{goppa.k}] Decoding vs Error Weight', fontsize=12)
ax.set_ylim(-0.05, 1.1)
ax.legend(fontsize=10)
ax.grid(True, alpha=0.3, axis='y')
plt.tight_layout()
plt.savefig('decoding_failure_rate.png', dpi=150, bbox_inches='tight')
plt.show()
Goppa code: n=8, k=2, t=2
Weight Successes Trials Rate
======================================
0 30 30 1.00
1 30 30 1.00
2 30 30 1.00
3 0 30 0.00
4 0 30 0.00
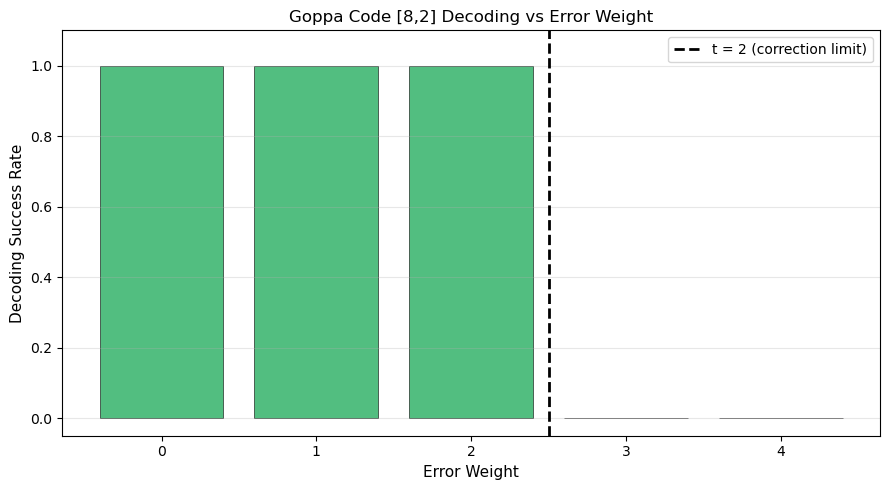
Danger
Using an error weight \(w > t\) in the McEliece scheme does not increase security — it causes decryption failure. The error weight must be exactly \(t\) for correct operation. An attacker who can induce the sender to use the wrong error weight could mount a denial-of-service attack.
Experiment 7: Syndrome Weight Distribution#
We analyse the distribution of syndrome weights for random error patterns to understand the information leakage from syndromes.
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
# Analyse syndrome weights for the Hamming code
# (easier to enumerate all possibilities)
hamming_code = LinearCode(G_hamming)
# All possible error patterns and their syndromes
syndrome_weights_by_error_weight = {}
n = hamming_code.n
for val in range(2**n):
e = np.array([(val >> b) & 1 for b in range(n)], dtype=int)
ew = int(np.sum(e))
s = hamming_code.syndrome(e)
sw = int(np.sum(s))
if ew not in syndrome_weights_by_error_weight:
syndrome_weights_by_error_weight[ew] = []
syndrome_weights_by_error_weight[ew].append(sw)
fig, axes = plt.subplots(2, 2, figsize=(10, 8))
for idx, ew in enumerate([0, 1, 2, 3]):
ax = axes[idx // 2][idx % 2]
sw_list = syndrome_weights_by_error_weight.get(ew, [])
if sw_list:
max_sw = max(sw_list)
bins = np.arange(-0.5, max_sw + 1.5, 1)
ax.hist(sw_list, bins=bins, color='#3498db', alpha=0.8, edgecolor='black', linewidth=0.5)
ax.set_title(f'Error weight = {ew} ({len(sw_list)} patterns)', fontsize=10)
ax.set_xlabel('Syndrome weight')
ax.set_ylabel('Count')
ax.grid(True, alpha=0.3)
fig.suptitle('Syndrome Weight Distribution for Hamming [7,4,3] Code',
fontsize=12, fontweight='bold')
plt.tight_layout()
plt.savefig('syndrome_distribution.png', dpi=150, bbox_inches='tight')
plt.show()
print("Syndrome weight statistics:")
print(f"{'Error wt':>10} {'Count':>8} {'Mean S wt':>10} {'Max S wt':>10}")
print("=" * 42)
for ew in sorted(syndrome_weights_by_error_weight.keys()):
sw_list = syndrome_weights_by_error_weight[ew]
if ew <= 4:
print(f"{ew:>10} {len(sw_list):>8} {float(np.mean(sw_list)):>10.2f} {max(sw_list):>10}")
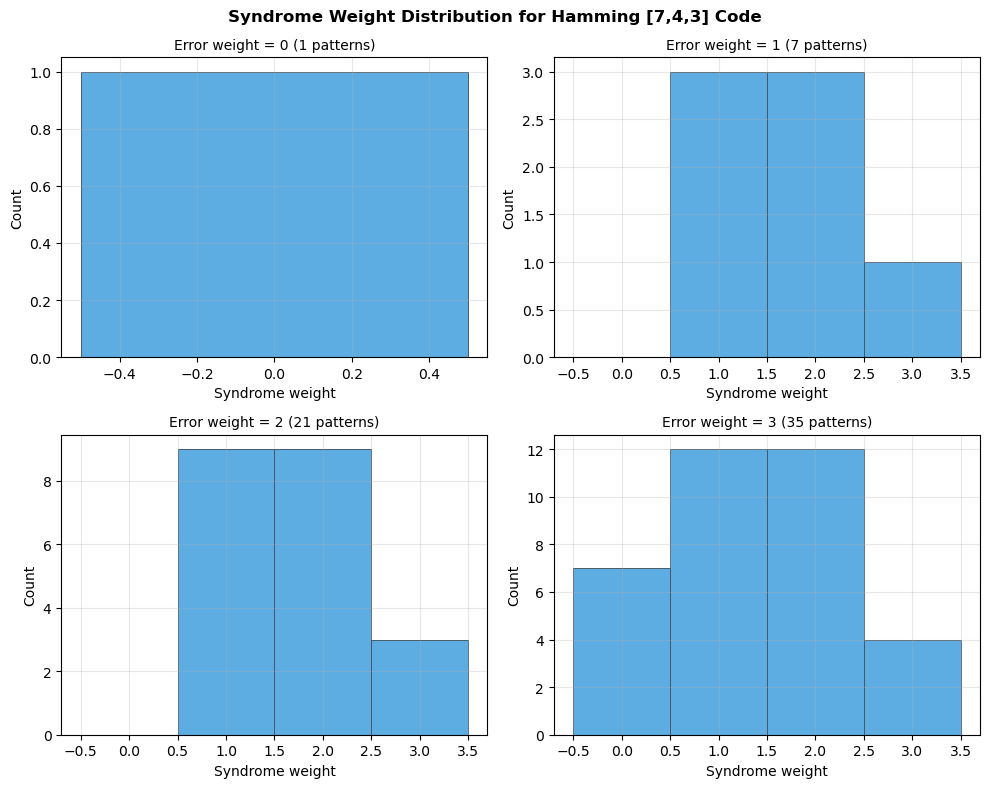
Syndrome weight statistics:
Error wt Count Mean S wt Max S wt
==========================================
0 1 0.00 0
1 7 1.71 3
2 21 1.71 3
3 35 1.37 3
4 35 1.37 3
Experiment 8: McEliece vs Niederreiter — Structural Comparison#
The Niederreiter variant encrypts by computing the syndrome of an error vector, rather than adding errors to an encoded message. We compare the two approaches.
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
import math
def niederreiter_key_sizes(m, t):
"""
Niederreiter public key size.
Public key: (n-k) x n parity-check matrix in systematic form -> (n-k) x k bits.
But the message space is the set of weight-t vectors, so
message bits = floor(log2(C(n, t))).
"""
n = 2**m
k = n - m * t
r = n - k # = m*t
# Public key: systematic H -> r x k bits
pub_bits = r * k
# Message space
# log2(C(n, t))
msg_bits = 0.0
for i in range(1, t + 1):
msg_bits += math.log2(n - i + 1) - math.log2(i)
return n, k, r, pub_bits, int(msg_bits)
def mceliece_key_sizes(m, t):
"""McEliece public key size."""
n = 2**m
k = n - m * t
pub_bits = k * n
msg_bits = k
return n, k, n - k, pub_bits, msg_bits
params = [(10, 50), (11, 50), (12, 62), (12, 96), (13, 119)]
print(f"{'m':>3} {'t':>4} {'n':>6} | {'McEliece PK (KB)':>18} {'msg bits':>10} | {'Niederreiter PK (KB)':>22} {'msg bits':>10}")
print("=" * 100)
mc_sizes = []
ni_sizes = []
labels = []
for m, t in params:
mn, mk, mr, mc_pub, mc_msg = mceliece_key_sizes(m, t)
nn, nk, nr, ni_pub, ni_msg = niederreiter_key_sizes(m, t)
mc_kb = mc_pub / 8 / 1024
ni_kb = ni_pub / 8 / 1024
mc_sizes.append(mc_kb)
ni_sizes.append(ni_kb)
labels.append(f"m={m},t={t}")
print(f"{m:>3} {t:>4} {mn:>6} | {float(mc_kb):>16.1f} {mc_msg:>10} | {float(ni_kb):>20.1f} {ni_msg:>10}")
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
x = np.arange(len(labels))
width = 0.35
ax1.bar(x - width/2, mc_sizes, width, color='#e74c3c', alpha=0.8, label='McEliece')
ax1.bar(x + width/2, ni_sizes, width, color='#3498db', alpha=0.8, label='Niederreiter')
ax1.set_xlabel('Parameter Set')
ax1.set_ylabel('Public Key Size (KB)')
ax1.set_title('Public Key Size Comparison')
ax1.set_xticks(x)
ax1.set_xticklabels(labels, rotation=30, ha='right')
ax1.legend()
ax1.grid(True, alpha=0.3, axis='y')
# Ratio plot
ratios = [mc / ni for mc, ni in zip(mc_sizes, ni_sizes)]
ax2.bar(x, ratios, color='#2ecc71', alpha=0.8)
ax2.set_xlabel('Parameter Set')
ax2.set_ylabel('McEliece / Niederreiter Size Ratio')
ax2.set_title('Relative Key Size (McEliece / Niederreiter)')
ax2.set_xticks(x)
ax2.set_xticklabels(labels, rotation=30, ha='right')
ax2.axhline(y=1, color='black', linestyle='--', alpha=0.5)
ax2.grid(True, alpha=0.3, axis='y')
for i, r in enumerate(ratios):
ax2.text(i, r + 0.02, f'{float(r):.2f}', ha='center', va='bottom', fontsize=9)
plt.tight_layout()
plt.savefig('mceliece_vs_niederreiter.png', dpi=150, bbox_inches='tight')
plt.show()
m t n | McEliece PK (KB) msg bits | Niederreiter PK (KB) msg bits
====================================================================================================
10 50 1024 | 65.5 524 | 32.0 284
11 50 2048 | 374.5 1498 | 100.6 334
12 62 4096 | 1676.0 3352 | 304.4 459
12 96 4096 | 1472.0 2944 | 414.0 652
13 119 8192 | 6645.0 6645 | 1254.9 892
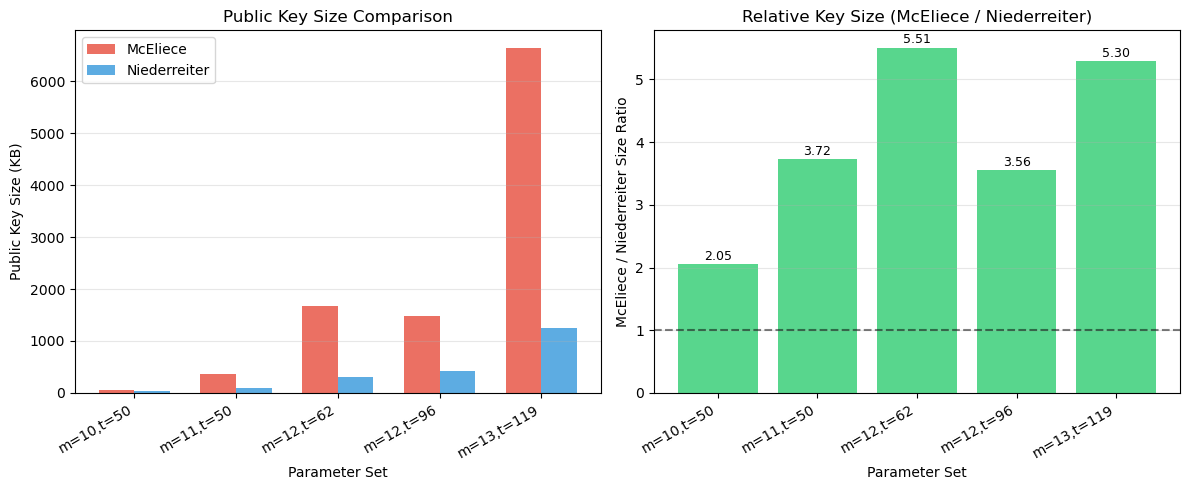
McEliece vs Niederreiter
The Niederreiter variant uses the parity-check matrix \(H\) as the public key instead of the generator matrix \(G\). Since \(H\) is \((n-k) \times n\) vs \(G\) being \(k \times n\), and typically \(k > n-k\), Niederreiter has smaller public keys. However, encryption in Niederreiter requires generating a weight-\(t\) error vector that encodes the message (via a constant-weight encoding), making the message space \(\lfloor \log_2 \binom{n}{t} \rfloor\) bits instead of \(k\) bits.
Li, Deng, and Wang (1994) proved that the two schemes are equivalent in terms of security: breaking one implies breaking the other.
43.7 Exercises#
Exercise 43.1 (Warm-up) Construct the Hamming \([7, 4, 3]\) code’s syndrome decoding table: for each of the 7 possible single-bit error patterns, compute the syndrome and verify that all syndromes are distinct. Explain why this guarantees single-error correction.
Hint
The syndrome of error \(\mathbf{e}_i\) (error in position \(i\)) equals the \(i\)-th column of \(H\). Since \(H\) has \(2^r - 1 = 7\) distinct nonzero columns (one for each nonzero 3-bit vector), each single-bit error produces a unique syndrome.
Exercise 43.2 (Applied) Implement a brute-force attack on the McEliece cryptosystem for the small parameters used in this chapter. Given only the public key \(G_{\mathrm{pub}}\) and a ciphertext \(\mathbf{c}\), try all \(\binom{n}{t}\) possible error patterns to find the message. Measure how long this takes and compare with legitimate decryption.
Hint
For each candidate error \(\mathbf{e}\) of weight \(t\), compute
\(\mathbf{c}' = \mathbf{c} - \mathbf{e}\) and check whether \(\mathbf{c}'\) lies
in the row space of \(G_{\mathrm{pub}}\) (i.e., solve \(\mathbf{m} G_{\mathrm{pub}} = \mathbf{c}'\)
over \(\mathbb{F}_2\)). Use itertools.combinations for the enumeration.
Exercise 43.3 (Analysis) Compute the exact number of codewords in the Goppa code constructed in Section 43.4.2. Verify that it equals \(2^k\). Then compute the covering radius — the maximum Hamming distance from any \(n\)-bit vector to the nearest codeword.
Hint
Enumerate all \(2^k\) messages and their codewords. For the covering radius, you need to find the \(n\)-bit vector that is farthest from any codeword. For small \(n\), try all \(2^n\) vectors.
Exercise 43.4 (Theory) Prove that a binary Goppa code \(\Gamma(L, g)\) with \(\deg g = t\) has minimum distance \(d \geq 2t + 1\) (not just \(t + 1\) as for general alternant codes). The key step is showing that if \(g(x)\) is square-free over \(\mathbb{F}_{2^m}\), then \(\Gamma(L, g) = \Gamma(L, g^2) \cap \mathbb{F}_2^n\).
Hint
Show that for binary codes, the parity-check condition \(\sum c_i / (x - \alpha_i) \equiv 0 \pmod{g(x)}\) can be strengthened to \(\sum c_i / (x - \alpha_i) \equiv 0 \pmod{g(x)^2}\) because over \(\mathbb{F}_2\), the formal derivative of \(\sum c_i / (x - \alpha_i)\) equals \(\sum c_i / (x - \alpha_i)^2\), which is the square of the original sum in characteristic 2.
Exercise 43.5 (Challenge) Implement Patterson’s decoding algorithm (as described in the admonition in Section 43.4.2) for the small Goppa codes used in this chapter. Compare its performance with the brute-force decoder. For which parameter sizes does the algebraic decoder become faster?
Hint
The critical step is computing the square root \(\tau(x) = \sqrt{T(x)} \pmod{g(x)}\). Over \(\mathbb{F}_{2^m}\), the square root of \(a\) is \(a^{2^{m-1}}\). For polynomials modulo \(g(x)\), compute the matrix representation of the Frobenius map \(\phi: f(x) \mapsto f(x)^2 \pmod{g(x)}\) and invert it to get the square root.
43.8 Summary#
Concept |
Key Point |
|---|---|
Linear codes |
\([n, k, d]\) subspaces of \(\mathbb{F}_2^n\); correct \(\lfloor(d-1)/2\rfloor\) errors |
Goppa codes |
Algebraic codes with efficient decoding; \(d \geq 2t+1\) for degree-\(t\) polynomial |
McEliece encryption |
Disguise Goppa code with \(G_{\mathrm{pub}} = S G_0 P\); add weight-\(t\) errors |
Niederreiter variant |
Encrypt via syndromes; equivalent security; smaller keys |
Patterson’s algorithm |
\(O(nt)\) decoding for binary Goppa codes using square roots in char 2 |
Security basis |
NP-hardness of generic syndrome decoding; resists quantum attacks |
Key size trade-off |
Public keys are 100-1000x larger than RSA/ECC; fast encryption/decryption |
NIST standardisation |
Classic McEliece: conservative, 45+ years of cryptanalytic confidence |
Tip
Code-based cryptography provides one of the strongest known defences against quantum computers. While the large key sizes pose practical challenges, the McEliece system’s speed and its decades of resistance to cryptanalysis make it a compelling choice for high-security applications. In the next chapter, we will explore lattice-based cryptography, which offers a different balance of key sizes and computational efficiency.
References#
McEliece, R. J. (1978). A Public-Key Cryptosystem Based on Algebraic Coding Theory. DSN Progress Report, 42-44, 114–116.
Goppa, V. D. (1970). A New Class of Linear Correcting Codes. Problems of Information Transmission, 6(3), 207–212.
Niederreiter, H. (1986). Knapsack-Type Cryptosystems and Algebraic Coding Theory. Problems of Control and Information Theory, 15(2), 159–166.
Patterson, N. J. (1975). The Algebraic Decoding of Goppa Codes. IEEE Transactions on Information Theory, 21(2), 203–207.
Berlekamp, E. R., McEliece, R. J., and van Tilborg, H. C. A. (1978). On the Inherent Intractability of Certain Coding Problems. IEEE Transactions on Information Theory, 24(3), 384–386.
Bernstein, D. J., Lange, T., and Peters, C. (2008). Attacking and Defending the McEliece Cryptosystem. PQCrypto 2008, LNCS 5299, 31–46.
Bernstein, D. J. et al. (2017). Classic McEliece: Conservative Code-Based Cryptography. NIST PQC Submission.