
Chapter 9: Automated Cryptanalysis – Hill Climbing with N-grams#
“The theoretical secrecy of a system having been settled, we can turn to the problem of the work required to break it… The problem of cryptanalysis is that of finding the most efficient algorithm for this inversion.” – Claude Shannon, Communication Theory of Secrecy Systems, 1949
In previous chapters we attacked ciphers with targeted analytical tools: frequency analysis for monoalphabetic substitution, Kasiski examination and the Index of Coincidence for Vigenere, and algebraic methods for the Hill cipher. Each of these methods is elegant, but each is also specific to one cipher type. A substitution-cipher analyst who encounters a Playfair cipher must learn an entirely different technique.
In this chapter we introduce a fundamentally different paradigm: automated cryptanalysis via hill climbing with n-gram scoring. Instead of exploiting the structure of a particular cipher, we define a fitness function that measures how much a candidate decryption resembles natural English, and then use stochastic optimization to search the key space for the key that maximizes this fitness. The approach is remarkably general – the same framework can attack substitution ciphers, transposition ciphers, Playfair ciphers, and many others, simply by changing the key representation and perturbation strategy.
The key insight is that quadgram log-likelihood scoring provides a fitness function that is simultaneously:
Sensitive enough to distinguish partially correct decryptions from random text
Smooth enough for hill climbing to make steady progress
Computationally cheap enough to evaluate millions of candidate keys
9.1 History: From Manual Frequency Analysis to Computer-Aided Cryptanalysis#
9.1.1 The Evolution of Scoring Functions#
The idea that natural language text has measurable statistical properties dates back to Al-Kindi (9th century), who first described frequency analysis. For centuries, the cryptanalyst’s primary tool was counting individual letters – what we now call unigram statistics.
The progression to more powerful scoring functions mirrors the growth of computational resources:
Era |
Scoring method |
Information captured |
Typical use |
|---|---|---|---|
9th–19th century |
Unigrams (single letters) |
Letter frequency |
Manual substitution breaking |
Early 20th century |
Bigrams (letter pairs) |
Common pairs like TH, HE, IN |
Friedman’s statistical methods |
Mid 20th century |
Trigrams (letter triples) |
Word fragments like THE, AND, ING |
Machine-aided analysis |
Late 20th century |
Quadgrams (4-letter sequences) |
Rich context, near word-level |
Computer-automated hill climbing |
The critical advance was recognizing that the longer the n-gram, the more context it captures about the structure of natural language. A unigram scorer only knows that E is common; a quadgram scorer knows that TION, THER, and THAT are common sequences, which provides far more discriminating power for distinguishing English from gibberish.
9.1.2 Hill Climbing in Cryptanalysis#
The application of hill climbing to cipher-breaking was pioneered in the 1990s and popularized through resources like the Practical Cryptography website maintained by James Lyons. The method was applied spectacularly to break several historical ciphers that had resisted decades of manual analysis.
9.1.3 Simon Singh’s Cipher#
Challenges
In 1999, Simon Singh published The Code Book, which included a set of cipher challenges of escalating difficulty. The challenges ranged from a simple Caesar (shift) cipher to the RSA public-key cryptosystem. The intermediate challenges – monoalphabetic substitution, Vigenere, and others – are precisely the type of cipher that hill-climbing methods can crack automatically. Singh offered a prize of 10,000 GBP for solving all stages, which was claimed in 2000 by a team from Sweden.
Historical note
The transition from manual to automated cryptanalysis was not merely about speed. Hill climbing with n-gram scoring introduced a qualitative change: the cryptanalyst no longer needs deep insight into the cipher’s structure. A well-designed fitness function and search strategy can break ciphers that the analyst does not even fully understand.
9.2 Formal Definitions#
9.2.1 N-grams#
Definition 9.1 (N-gram)
An n-gram is a contiguous sequence of \(n\) characters drawn from a text. For a text \(x = x_1 x_2 \cdots x_N\) over an alphabet \(\mathcal{A}\), the n-grams are:
The total number of n-grams in a text of length \(N\) is \(N - n + 1\).
For the English alphabet with \(|\mathcal{A}| = 26\), the number of possible n-grams is \(26^n\): 26 unigrams, 676 bigrams, 17,576 trigrams, and 456,976 quadgrams.
9.2.2 N-gram Frequency Table#
Definition 9.2 (N-gram frequency table)
Given a large reference corpus \(C\) of length \(M\), the n-gram frequency table is the mapping \(F: \mathcal{A}^n \to [0,1]\) defined by:
where \(\text{count}(g, C)\) is the number of times the n-gram \(g\) appears in the corpus \(C\).
9.2.3 Log-Likelihood Scoring#
Definition 9.3 (Log-likelihood score)
The log-likelihood score of a candidate text \(x = x_1 x_2 \cdots x_N\) with respect to an n-gram frequency table \(F\) is:
For n-grams \(g\) not observed in the corpus, we assign a floor probability \(F_{\text{floor}} = \frac{0.01}{M - n + 1}\) to avoid \(\log(0)\).
The score is always negative (since \(\log_{10}\) of a probability is negative). A higher (less negative) score indicates text that is more consistent with natural English. English text typically scores around \(-2.5\) to \(-3.0\) per quadgram, while random text scores around \(-5\) to \(-6\) per quadgram.
9.2.4 Hill Climbing#
Definition 9.4 (Hill climbing for cryptanalysis)
Hill climbing is an iterative optimization algorithm applied to the key space \(\mathcal{K}\) of a cipher:
Initialize: Choose a random key \(k_0 \in \mathcal{K}\).
Perturb: Generate a neighbor \(k'\) by making a small change to the current key \(k_t\).
Evaluate: Compute \(\text{score}(D_{k'}(c))\) where \(D_{k'}\) is decryption with key \(k'\) and \(c\) is the ciphertext.
Accept/Reject: If \(\text{score}(D_{k'}(c)) > \text{score}(D_{k_t}(c))\), set \(k_{t+1} = k'\); otherwise \(k_{t+1} = k_t\).
Repeat steps 2–4 until convergence (no improvement for many iterations).
Restart: If stuck in a local optimum, restart from step 1 with a new random key.
9.2.5 Simulated Annealing#
Definition 9.5 (Simulated annealing)
Simulated annealing modifies hill climbing by accepting worse solutions with a probability that decreases over time. Given a score difference \(\Delta = \text{score}(k') - \text{score}(k_t)\), we accept \(k'\) with probability:
where \(T > 0\) is the temperature parameter. The temperature follows a cooling schedule \(T(t) = T_0 \cdot \alpha^t\) for some decay factor \(\alpha \in (0,1)\). At high temperature, the algorithm explores freely; as \(T \to 0\), it becomes pure hill climbing.
9.3 Implementation#
We now implement the n-gram scoring and hill climbing framework. All code uses only numpy and matplotlib, and we build quadgram frequency tables inline from a sample English corpus rather than loading external files.
import numpy as np
# --- Sample English Corpus ---
# We build our n-gram tables from a substantial inline corpus.
# This is a concatenation of classic English prose passages, providing
# a representative sample of English letter statistics.
SAMPLE_CORPUS = (
"it was the best of times it was the worst of times it was the age of wisdom "
"it was the age of foolishness it was the epoch of belief it was the epoch of "
"incredulity it was the season of light it was the season of darkness it was "
"the spring of hope it was the winter of despair we had everything before us "
"we had nothing before us we were all going direct to heaven we were all going "
"direct the other way in short the period was so far like the present period "
"that some of its noisiest authorities insisted on its being received for good "
"or for evil in the superlative degree of comparison only there were a king "
"with a large jaw and a queen with a plain face on the throne of england there "
"were a king with a large jaw and a queen with a fair face on the throne of "
"france in both countries it was clearer than crystal to the lords of the state "
"preserves of loaves and fishes that things in general were settled for ever "
"call me ishmael some years ago never mind how long precisely having little or "
"no money in my purse and nothing particular to interest me on shore i thought "
"i would sail about a little and see the watery part of the world it is a way "
"i have of driving off the spleen and regulating the circulation whenever i find "
"myself growing grim about the mouth whenever it is a damp drizzly november in "
"my soul whenever i find myself involuntarily pausing before coffin warehouses "
"and bringing up the rear of every funeral i meet and especially whenever my "
"hypos get such an upper hand of me that it requires a strong moral principle "
"to prevent me from deliberately stepping into the street and methodically "
"knocking peoples hats off then i account it high time to get to sea as soon "
"as possible this is my substitute for pistol and ball with a philosophical "
"flourish cato throws himself upon his sword i quietly take to the ship there "
"is nothing surprising in this if they but knew it almost all men in their "
"degree some time or other cherish very nearly the same feelings towards the "
"ocean with me there now is your insular city of the manhattoes belted round "
"by wharves as indian isles by coral reefs commerce surrounds it with her surf "
"right and left the streets take you waterward its extreme downtown is the "
"battery where that noble mole is washed by waves and cooled by breezes which "
"a few hours previous were out of sight of land look at the crowds of water "
"gazers there circumambulate the city of a dreamy sabbath afternoon go from "
"corlears hook to coenties slip and from thence by whitehall northward what "
"do you see posted like silent sentinels all around the town stand thousands "
"upon thousands of mortal men fixed in ocean reveries some leaning against the "
"spiles some seated upon the pier heads some looking over the bulwarks of ships "
"from china some aloft in the rigging as if striving to get a still better "
"seaward peep but these are all landsmen of week days pent up in lath and "
"plaster tied to counters nailed to benches clinched to desks how then is this "
"are the green fields gone what do they here but look here come more crowds "
"pacing straight for the water and seemingly bound for a dive nothing will "
"content them but the extremest limit of the land loitering under the shady "
"lee of yonder warehouses will not suffice no they must get just as nigh the "
"water as they possibly can without falling in and there they stand miles of "
"them leagues inlanders all they come from lanes and alleys streets and avenues "
"north south east and west yet here they all unite tell me does the magnetic "
"virtue of the needles of the compasses of all those ships attract them thither "
"the quick brown fox jumps over the lazy dog the five boxing wizards jump quickly "
"pack my box with five dozen liquor jugs how vexingly quick daft zebras jump "
"the sun shone having no alternative on the nothing new the earth makes of the "
"sea the same old round the whole dull story all the same nothing to be done "
"the night was dark and full of terrors the wind howled through the ancient trees "
"and the rain beat against the windows of the old castle deep within the chamber "
"a single candle flickered casting long shadows across the stone walls the "
"cryptanalyst sat hunched over the desk surrounded by sheaves of paper covered "
"with columns of letters and numbers she had been working on this cipher for "
"three days now and the solution still eluded her the ciphertext was long enough "
"to work with but the encryption method was unlike anything she had seen before "
"the frequency distribution was nearly flat suggesting either a polyalphabetic "
"cipher or some form of transposition perhaps both she reached for her coffee "
"now cold and took a long sip the answer was in these letters somewhere she "
"just had to find the right pattern the right key that would unlock the message "
"hidden within the cipher the art of cryptanalysis is as old as the art of "
"cryptography itself for as long as people have been hiding messages others "
"have been trying to read them the earliest known use of cryptography dates "
"back to ancient egypt where scribes used nonstandard hieroglyphs to obscure "
"their writings the spartans used a device called the scytale a cylinder around "
"which a strip of parchment was wound and the message was written along the "
"length of the cylinder julius caesar famously used a simple substitution cipher "
"shifting each letter by three positions in the alphabet today we call this the "
"caesar cipher and while it is trivially easy to break it represents one of the "
"oldest documented examples of encryption in the western world the history of "
"cryptanalysis took a major turn with the work of the arab scholar al kindi who "
"in the ninth century wrote a manuscript on deciphering cryptographic messages "
"in which he described the technique of frequency analysis this method exploits "
"the fact that in any natural language certain letters appear more frequently "
"than others in english the letter e is by far the most common followed by t a "
"o i n and s by counting the frequency of each letter in a ciphertext and "
"comparing it to the known frequency distribution of the language one can often "
"deduce the substitution table and recover the plaintext the renaissance saw "
"the development of polyalphabetic ciphers most notably the vigenere cipher "
"which was considered unbreakable for centuries and earned the nickname the "
"indecipherable cipher it was not until the nineteenth century that charles "
"babbage and later friedrich kasiski independently developed methods to break it "
"the twentieth century brought mechanical and then electronic cipher machines "
"the most famous being the german enigma machine used extensively during world "
"war two the breaking of enigma by polish mathematicians marian rejewski jerzy "
"rozycki and henryk zygalski and later by the british team at bletchley park "
"led by alan turing is one of the greatest intellectual achievements in the "
"history of warfare the effort saved countless lives and arguably shortened the "
"war by several years in the modern era cryptography has become a mathematical "
"discipline based on computational complexity theory the security of modern "
"ciphers rests not on the secrecy of the algorithm but on the difficulty of "
"certain mathematical problems such as integer factorization and the discrete "
"logarithm problem despite the theoretical strength of modern cryptosystems "
"classical ciphers remain important as teaching tools and as subjects of study "
"they illustrate fundamental principles of confusion and diffusion key space "
"analysis and the interplay between encryption and cryptanalysis that define "
"the field to this day"
)
def clean_text(text):
"""Remove non-alphabetic characters and convert to lowercase."""
return ''.join(ch.lower() for ch in text if ch.isalpha())
corpus = clean_text(SAMPLE_CORPUS)
print(f"Corpus length: {len(corpus)} characters")
print(f"First 100 characters: {corpus[:100]}")
print(f"Last 100 characters: {corpus[-100:]}")
Corpus length: 6219 characters
First 100 characters: itwasthebestoftimesitwastheworstoftimesitwastheageofwisdomitwastheageoffoolishnessitwastheepochofbel
Last 100 characters: diffusionkeyspaceanalysisandtheinterplaybetweenencryptionandcryptanalysisthatdefinethefieldtothisday
9.3.1 The NgramScorer Class#
Our NgramScorer class builds an n-gram frequency table from the corpus and provides a log-likelihood scoring method.
import numpy as np
class NgramScorer:
"""Compute log-likelihood scores of text using n-gram frequency tables.
The n-gram table is built from a reference corpus. For each n-gram g,
we store log10(count(g) / total_ngrams). N-grams not seen in the corpus
receive a floor score of log10(0.01 / total_ngrams).
"""
def __init__(self, corpus, n):
"""Build an n-gram frequency table from the given corpus.
Parameters
----------
corpus : str
Cleaned lowercase alphabetic text.
n : int
Length of n-grams (1=unigram, 2=bigram, 3=trigram, 4=quadgram).
"""
self.n = n
self.ngram_scores = {}
# Count all n-grams in the corpus
counts = {}
for i in range(len(corpus) - n + 1):
gram = corpus[i:i + n]
counts[gram] = counts.get(gram, 0) + 1
total = sum(counts.values())
self.total = total
# Convert to log-probabilities
for gram, count in counts.items():
self.ngram_scores[gram] = np.log10(count / total)
# Floor score for unseen n-grams
self.floor = np.log10(0.01 / total)
# Store the sorted list for inspection
self.sorted_ngrams = sorted(self.ngram_scores.items(),
key=lambda x: x[1], reverse=True)
def score(self, text):
"""Compute the log-likelihood score of a text.
Parameters
----------
text : str
Cleaned lowercase text to score.
Returns
-------
float
Sum of log10(frequency) for each n-gram in the text.
"""
score = 0.0
n = self.n
for i in range(len(text) - n + 1):
gram = text[i:i + n]
score += self.ngram_scores.get(gram, self.floor)
return score
def score_per_ngram(self, text):
"""Compute average score per n-gram (for comparing texts of different lengths)."""
n_ngrams = len(text) - self.n + 1
if n_ngrams <= 0:
return self.floor
return self.score(text) / n_ngrams
def top_ngrams(self, k=20):
"""Return the top-k most frequent n-grams with their log-scores."""
return self.sorted_ngrams[:k]
# Build scorers for different n-gram sizes from our inline corpus
corpus = ''.join(ch.lower() for ch in SAMPLE_CORPUS if ch.isalpha())
scorer1 = NgramScorer(corpus, 1) # unigram
scorer2 = NgramScorer(corpus, 2) # bigram
scorer3 = NgramScorer(corpus, 3) # trigram
scorer4 = NgramScorer(corpus, 4) # quadgram
print(f"Corpus length: {len(corpus)} characters")
print(f"\nUnique n-grams found:")
print(f" Unigrams: {int(len(scorer1.ngram_scores)):>6d} (possible: {26})")
print(f" Bigrams: {int(len(scorer2.ngram_scores)):>6d} (possible: {26**2})")
print(f" Trigrams: {int(len(scorer3.ngram_scores)):>6d} (possible: {26**3})")
print(f" Quadgrams: {int(len(scorer4.ngram_scores)):>6d} (possible: {26**4})")
print(f"\nFloor scores: unigram={float(scorer1.floor):.4f}, bigram={float(scorer2.floor):.4f}, "
f"trigram={float(scorer3.floor):.4f}, quadgram={float(scorer4.floor):.4f}")
print(f"\nTop 10 quadgrams:")
for gram, score in scorer4.top_ngrams(10):
print(f" {gram} {score:+.4f}")
Corpus length: 6219 characters
Unique n-grams found:
Unigrams: 26 (possible: 26)
Bigrams: 424 (possible: 676)
Trigrams: 2109 (possible: 17576)
Quadgrams: 4000 (possible: 456976)
Floor scores: unigram=-5.7937, bigram=-5.7937, trigram=-5.7936, quadgram=-5.7935
Top 10 quadgrams:
thes -2.3956
sthe -2.4318
ther -2.5148
nthe -2.5382
fthe -2.5382
ethe -2.5631
dthe -2.5631
twas -2.6174
here -2.6174
ofth -2.6174
Implementation note
The floor score log10(0.01 / total) is a standard smoothing technique. Without it, any n-gram not present in the corpus would yield \(\log(0) = -\infty\), making the entire text score \(-\infty\). The floor assigns a very low but finite score to unseen n-grams, ensuring that the scoring function degrades gracefully. This is essentially Laplace-like smoothing in the log domain.
9.3.2 The HillClimbingAttacker Class#
We now build a generic hill climbing framework. The base class defines the structure; specialized subclasses implement cipher-specific key perturbation and decryption.
import numpy as np
class HillClimbingAttacker:
"""Generic hill climbing framework for cipher cryptanalysis.
Subclasses must implement:
- random_key(): generate a random starting key
- perturb_key(key): make a small random change to the key
- decrypt(ciphertext, key): decrypt ciphertext with the given key
"""
def __init__(self, scorer, ciphertext):
"""Initialize the attacker.
Parameters
----------
scorer : NgramScorer
The n-gram scorer to evaluate candidate decryptions.
ciphertext : str
The ciphertext to attack (cleaned, lowercase).
"""
self.scorer = scorer
self.ciphertext = ciphertext
def random_key(self):
raise NotImplementedError
def perturb_key(self, key):
raise NotImplementedError
def decrypt(self, ciphertext, key):
raise NotImplementedError
def evaluate(self, key):
"""Decrypt the ciphertext with the given key and return its score."""
plaintext = self.decrypt(self.ciphertext, key)
return self.scorer.score(plaintext)
def attack(self, num_restarts=30, iterations_per_climb=1000,
verbose=True, rng=None):
"""Run the hill climbing attack with random restarts.
Parameters
----------
num_restarts : int
Number of random restarts.
iterations_per_climb : int
Maximum iterations without improvement before restarting.
verbose : bool
If True, print progress updates.
rng : numpy.random.Generator or None
Random number generator for reproducibility.
Returns
-------
best_key : object
The best key found.
best_score : float
The score of the best decryption.
best_plaintext : str
The decrypted text using the best key.
score_history : list of float
History of best scores across all iterations (for plotting).
"""
if rng is None:
rng = np.random.default_rng()
global_best_score = -1e15
global_best_key = None
score_history = []
for restart in range(num_restarts):
# Start with a random key
parent_key = self.random_key()
parent_score = self.evaluate(parent_key)
# Hill climb: keep swapping until no improvement for many steps
no_improve_count = 0
while no_improve_count < iterations_per_climb:
child_key = self.perturb_key(parent_key)
child_score = self.evaluate(child_key)
if child_score > parent_score:
parent_score = child_score
parent_key = child_key
no_improve_count = 0
else:
no_improve_count += 1
score_history.append(max(parent_score, global_best_score))
# Check if this restart found a better solution
if parent_score > global_best_score:
global_best_score = parent_score
global_best_key = parent_key
if verbose:
pt = self.decrypt(self.ciphertext, global_best_key)
print(f"Restart {int(restart+1):>3d}: score = {float(global_best_score):.2f} "
f"plaintext = {pt[:60]}...")
best_plaintext = self.decrypt(self.ciphertext, global_best_key)
return global_best_key, global_best_score, best_plaintext, score_history
print("HillClimbingAttacker base class defined.")
HillClimbingAttacker base class defined.
9.3.3 Specialized Attacker: Monoalphabetic Substitution Cipher#
For a monoalphabetic substitution cipher, the key is a permutation of the 26-letter alphabet. The perturbation operation swaps two random letters in the permutation.
import numpy as np
class SubstitutionAttacker(HillClimbingAttacker):
"""Hill climbing attacker specialized for monoalphabetic substitution ciphers.
The key is a permutation of 'abcdefghijklmnopqrstuvwxyz'.
Key[i] = j means that plaintext letter i encrypts to ciphertext letter j.
To decrypt, we invert the permutation.
"""
ALPHABET = list('abcdefghijklmnopqrstuvwxyz')
def __init__(self, scorer, ciphertext, rng=None):
super().__init__(scorer, ciphertext)
self.rng = rng if rng is not None else np.random.default_rng()
def random_key(self):
"""Generate a random permutation key."""
key = self.ALPHABET[:]
self.rng.shuffle(key)
return key
def perturb_key(self, key):
"""Swap two random positions in the key permutation."""
child = key[:]
a = int(self.rng.integers(0, 26))
b = int(self.rng.integers(0, 26))
child[a], child[b] = child[b], child[a]
return child
def decrypt(self, ciphertext, key):
"""Decrypt by inverting the permutation key.
If key maps plaintext -> ciphertext, then to decrypt we need
the inverse mapping: ciphertext -> plaintext.
"""
# Build inverse mapping: for each ciphertext letter, find plaintext letter
inverse = {}
for i, letter in enumerate(self.ALPHABET):
inverse[key[i]] = letter
return ''.join(inverse.get(ch, ch) for ch in ciphertext)
print("SubstitutionAttacker class defined.")
print(f"Key space size: 26! ~ {float(np.math.factorial(26)):.4e}")
SubstitutionAttacker class defined.
Key space size: 26! ~ 4.0329e+26
9.3.4 Specialized Attacker: Playfair Cipher#
For a Playfair cipher, the key is a \(5 \times 5\) grid of the 25 letters (I and J are merged). The perturbation strategy swaps two letters within the grid. Decryption follows the standard Playfair rules (same-row shift left, same-column shift up, rectangle swap).
import numpy as np
class PlayfairAttacker(HillClimbingAttacker):
"""Hill climbing attacker specialized for the Playfair cipher.
The key is a list of 25 letters (I/J merged) representing the 5x5 grid,
read left-to-right, top-to-bottom.
"""
ALPHABET_25 = list('abcdefghiklmnopqrstuvwxyz') # no 'j'
def __init__(self, scorer, ciphertext, rng=None):
# Replace j with i in ciphertext
ciphertext = ciphertext.replace('j', 'i')
super().__init__(scorer, ciphertext)
self.rng = rng if rng is not None else np.random.default_rng()
def random_key(self):
"""Generate a random 5x5 grid as a flat list of 25 letters."""
key = self.ALPHABET_25[:]
self.rng.shuffle(key)
return key
def perturb_key(self, key):
"""Swap two random positions in the grid."""
child = key[:]
a = int(self.rng.integers(0, 25))
b = int(self.rng.integers(0, 25))
child[a], child[b] = child[b], child[a]
return child
def _find_position(self, letter, key):
"""Find (row, col) of a letter in the 5x5 grid."""
idx = key.index(letter)
return idx // 5, idx % 5
def decrypt(self, ciphertext, key):
"""Decrypt using Playfair rules (reverse direction)."""
text = ciphertext.replace('j', 'i').lower()
result = []
for idx in range(0, len(text) - 1, 2):
l1, l2 = text[idx], text[idx + 1]
r1, c1 = self._find_position(l1, key)
r2, c2 = self._find_position(l2, key)
if r1 == r2: # Same row: shift left
result.append(key[r1 * 5 + (c1 - 1) % 5])
result.append(key[r2 * 5 + (c2 - 1) % 5])
elif c1 == c2: # Same column: shift up
result.append(key[((r1 - 1) % 5) * 5 + c1])
result.append(key[((r2 - 1) % 5) * 5 + c2])
else: # Rectangle: swap columns
result.append(key[r1 * 5 + c2])
result.append(key[r2 * 5 + c1])
return ''.join(result)
print("PlayfairAttacker class defined.")
print(f"Key space size: 25! ~ {float(np.math.factorial(25)):.4e}")
PlayfairAttacker class defined.
Key space size: 25! ~ 1.5511e+25
9.4 Key Results#
9.4.1 Why Quadgrams Work Better#
The information content of an n-gram model increases with \(n\). Formally, for a language model \(P\), the entropy rate captured by an n-gram model is:
Shannon (1951) estimated the entropy rate of English at approximately 1.0–1.5 bits per character. Unigram models capture about 4.2 bits/char, bigram models about 3.6 bits/char, trigrams about 3.1 bits/char, and quadgrams about 2.8 bits/char. The closer the model’s entropy to the true entropy, the better it discriminates between English and non-English text.
In practice, quadgrams represent the sweet spot: they capture enough context to recognize common English patterns (TION, THER, MENT, IGHT, OULD, NESS) while still being manageable in size (\(26^4 \approx 457K\) possible quadgrams, of which only \(\sim 10{,}000\)–\(20{,}000\) appear with nontrivial frequency).
9.4.2 Convergence and Local Optima#
Hill climbing on the substitution cipher key space is not guaranteed to find the global optimum. The fitness landscape has many local optima – key permutations that score well but are not the correct key. This is why random restarts are essential.
Theorem 9.1 (Expected restarts for global optimum)
Let \(p\) be the probability that a single hill-climbing run (from a random start) converges to the global optimum. Then the expected number of random restarts needed to find the global optimum at least once is:
and the probability of finding the global optimum in \(k\) restarts is:
For substitution ciphers with quadgram scoring on texts of 200+ characters, empirical studies suggest \(p \approx 0.05\)–\(0.15\), so approximately 7–20 restarts suffice on average.
Proof. Each restart is an independent Bernoulli trial with success probability \(p\). The number of trials until the first success follows a geometric distribution with parameter \(p\), whose expected value is \(1/p\). The probability of at least one success in \(k\) trials is \(1 - (1-p)^k\). \(\square\)
Experiments#
Experiment 1: Building a Quadgram Frequency Table#
We build the quadgram table from our inline corpus and inspect the most and least common quadgrams.
import numpy as np
# Rebuild the scorer to display analysis
corpus = ''.join(ch.lower() for ch in SAMPLE_CORPUS if ch.isalpha())
scorer4 = NgramScorer(corpus, 4)
print("=" * 60)
print("QUADGRAM FREQUENCY TABLE ANALYSIS")
print("=" * 60)
print(f"\nCorpus size: {len(corpus)} characters")
print(f"Total quadgrams extracted: {scorer4.total}")
print(f"Unique quadgrams: {len(scorer4.ngram_scores)}")
print(f"Coverage: {float(len(scorer4.ngram_scores) / 26**4 * 100):.2f}% of possible quadgrams")
print(f"Floor score (unseen quadgrams): {float(scorer4.floor):.4f}")
print(f"\n--- Top 20 Most Common Quadgrams ---")
print(f"{'Rank':>4s} {'Quadgram':>8s} {'Log-score':>10s} {'Approx freq':>12s}")
print("-" * 42)
for rank, (gram, score) in enumerate(scorer4.top_ngrams(20), 1):
freq = 10 ** score
print(f"{int(rank):>4d} {gram:>8s} {score:>+10.4f} {float(freq):>12.6f}")
print(f"\n--- Bottom 10 Least Common Quadgrams ---")
bottom = scorer4.sorted_ngrams[-10:]
for gram, score in bottom:
print(f" {gram} {score:+.4f}")
============================================================
QUADGRAM FREQUENCY TABLE ANALYSIS
============================================================
Corpus size: 6219 characters
Total quadgrams extracted: 6216
Unique quadgrams: 4000
Coverage: 0.88% of possible quadgrams
Floor score (unseen quadgrams): -5.7935
--- Top 20 Most Common Quadgrams ---
Rank Quadgram Log-score Approx freq
------------------------------------------
1 thes -2.3956 0.004022
2 sthe -2.4318 0.003700
3 ther -2.5148 0.003057
4 nthe -2.5382 0.002896
5 fthe -2.5382 0.002896
6 ethe -2.5631 0.002735
7 dthe -2.5631 0.002735
8 twas -2.6174 0.002413
9 here -2.6174 0.002413
10 ofth -2.6174 0.002413
11 them -2.6174 0.002413
12 ciph -2.6174 0.002413
13 iphe -2.6174 0.002413
14 pher -2.6174 0.002413
15 tthe -2.6474 0.002252
16 with -2.6474 0.002252
17 inth -2.6796 0.002091
18 sand -2.6796 0.002091
19 tion -2.6796 0.002091
20 itwa -2.7143 0.001931
--- Bottom 10 Least Common Quadgrams ---
defi -3.7935
efin -3.7935
fine -3.7935
efie -3.7935
eldt -3.7935
ldto -3.7935
dtot -3.7935
hisd -3.7935
isda -3.7935
sday -3.7935
Experiment 2: Scoring English Text vs. Random Text vs. Partially Decrypted Text#
We demonstrate the discriminating power of quadgram scoring by comparing scores for three types of text.
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
# Rebuild scorers
corpus = ''.join(ch.lower() for ch in SAMPLE_CORPUS if ch.isalpha())
scorer4 = NgramScorer(corpus, 4)
# 1. English plaintext
english_sample = ''.join(ch.lower() for ch in
"The art of cryptanalysis is as old as the art of cryptography itself "
"For as long as people have been hiding messages others have been trying "
"to read them The earliest known use of cryptography dates back to ancient "
"Egypt where scribes used nonstandard hieroglyphs to obscure their writings"
if ch.isalpha())
# 2. Random text (same length)
rng = np.random.default_rng(42)
random_sample = ''.join(chr(int(rng.integers(0, 26)) + ord('a'))
for _ in range(len(english_sample)))
# 3. Partially decrypted text: simulate by replacing 50% of chars with random
partial = list(english_sample)
num_replace = len(partial) // 2
indices = rng.choice(len(partial), size=num_replace, replace=False)
for idx in indices:
partial[int(idx)] = chr(int(rng.integers(0, 26)) + ord('a'))
partial_sample = ''.join(partial)
# Compute scores
score_english = scorer4.score(english_sample)
score_random = scorer4.score(random_sample)
score_partial = scorer4.score(partial_sample)
score_per_english = scorer4.score_per_ngram(english_sample)
score_per_random = scorer4.score_per_ngram(random_sample)
score_per_partial = scorer4.score_per_ngram(partial_sample)
print("=" * 65)
print("QUADGRAM SCORING COMPARISON")
print("=" * 65)
print(f"\nText length: {len(english_sample)} characters\n")
print(f"{'Text type':<25s} {'Total score':>12s} {'Per quadgram':>14s}")
print("-" * 55)
print(f"{'English plaintext':<25s} {float(score_english):>12.2f} {float(score_per_english):>14.4f}")
print(f"{'Partially decrypted':<25s} {float(score_partial):>12.2f} {float(score_per_partial):>14.4f}")
print(f"{'Random text':<25s} {float(score_random):>12.2f} {float(score_per_random):>14.4f}")
print(f"\nFirst 60 chars of each:")
print(f" English: {english_sample[:60]}")
print(f" Partial: {partial_sample[:60]}")
print(f" Random: {random_sample[:60]}")
# Visualization
fig, ax = plt.subplots(figsize=(8, 5))
categories = ['English\nplaintext', 'Partially\ndecrypted', 'Random\ntext']
scores = [score_per_english, score_per_partial, score_per_random]
colors = ['forestgreen', 'orange', 'firebrick']
bars = ax.bar(categories, scores, color=colors, edgecolor='black', alpha=0.85, width=0.5)
for bar, s in zip(bars, scores):
ax.text(bar.get_x() + bar.get_width() / 2, bar.get_height() + 0.05,
f'{float(s):.3f}', ha='center', va='bottom', fontsize=11, fontweight='bold')
ax.set_ylabel('Average log-likelihood per quadgram', fontsize=12)
ax.set_title('Quadgram Scoring: English vs. Partial vs. Random', fontsize=13)
ax.grid(axis='y', alpha=0.3)
ax.set_ylim(min(scores) - 0.5, 0)
plt.tight_layout()
plt.savefig('scoring_comparison.png', dpi=150, bbox_inches='tight')
plt.show()
print("\nFigure saved: scoring_comparison.png")
=================================================================
QUADGRAM SCORING COMPARISON
=================================================================
Text length: 241 characters
Text type Total score Per quadgram
-------------------------------------------------------
English plaintext -830.14 -3.4880
Partially decrypted -1322.54 -5.5569
Random text -1374.86 -5.7767
First 60 chars of each:
English: theartofcryptanalysisisasoldastheartofcryptographyitselffora
Partial: tnedrpoxcrpkttoalyskvnltvjodagthearcobcryxlouiaywyvqsavfygry
Random: curllwcsfcnzttsundvlnjeyuqkvollfcoxbwvhqetsjbzlxrutfjmmboetr
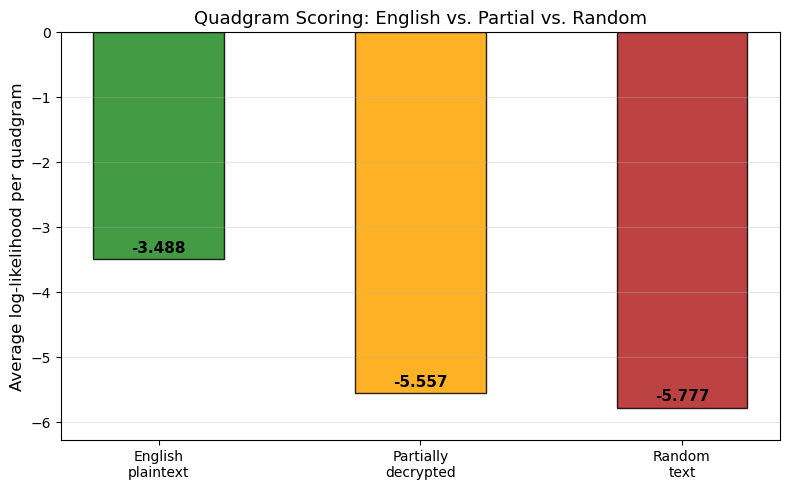
Figure saved: scoring_comparison.png
Observation
The quadgram scorer clearly separates the three text types. English plaintext achieves the highest (least negative) score per quadgram, because its n-gram distribution matches the reference corpus closely. Random text receives the lowest score, dominated by the floor penalty for unseen quadgrams. The partially decrypted text falls in between, which is exactly the gradient that hill climbing follows – each correct key improvement nudges the score upward toward the English plateau.
Experiment 3: Hill-Climbing Attack on a Substitution Cipher#
We encrypt a known plaintext with a random substitution key, then attack it using our SubstitutionAttacker. We track the score at each iteration to visualize convergence.
import numpy as np
import matplotlib.pyplot as plt
# Rebuild scorer
corpus = ''.join(ch.lower() for ch in SAMPLE_CORPUS if ch.isalpha())
scorer4 = NgramScorer(corpus, 4)
# --- Prepare the substitution cipher ---
rng = np.random.default_rng(2024)
ALPHABET = list('abcdefghijklmnopqrstuvwxyz')
# Generate a random encryption key
enc_key = ALPHABET[:]
rng.shuffle(enc_key)
# Plaintext to encrypt (adapted from the course poetry in the source material)
plaintext = ''.join(ch.lower() for ch in
"Ciphers oh ciphers secrets they keep "
"Locked away in code deep and discreet "
"Symbols and numbers jumbled and mixed "
"A message encoded ready to be fixed "
"Through history they have been used to hide "
"Plans of war love letters beside "
"The Rosetta Stone a mystery solved "
"A codebreakers work duly evolved"
if ch.isalpha())
# Encrypt: plaintext letter -> ciphertext letter via enc_key
encrypt_map = dict(zip(ALPHABET, enc_key))
ciphertext = ''.join(encrypt_map[ch] for ch in plaintext)
print(f"Plaintext ({len(plaintext)} chars): {plaintext[:70]}...")
print(f"Enc key: {''.join(enc_key)}")
print(f"Ciphertext ({len(ciphertext)} chars): {ciphertext[:70]}...")
# --- Attack ---
print("\n" + "=" * 70)
print("HILL CLIMBING ATTACK ON SUBSTITUTION CIPHER")
print("=" * 70)
attacker = SubstitutionAttacker(scorer4, ciphertext, rng=np.random.default_rng(99))
best_key, best_score, best_pt, history = attacker.attack(
num_restarts=30, iterations_per_climb=1500, verbose=True
)
print(f"\n{'='*70}")
print(f"RESULT")
print(f"Best score: {float(best_score):.2f}")
print(f"Best key: {''.join(best_key)}")
print(f"True key: {''.join(enc_key)}")
print(f"Decrypted: {best_pt[:80]}...")
print(f"Original: {plaintext[:80]}...")
# Count correct letters in key
correct = sum(1 for a, b in zip(best_key, enc_key) if a == b)
print(f"\nKey letters correct: {correct}/26")
Plaintext (243 chars): ciphersohcipherssecretstheykeeplockedawayincodedeepanddiscreetsymbolsa...
Enc key: yoacmplkjnfugvrtzhsdxqbewi
Ciphertext (243 chars): ajtkmhsrkajtkmhssmahmdsdkmwfmmturafmcybywjvarcmcmmtyvccjsahmmdswgorusy...
======================================================================
HILL CLIMBING ATTACK ON SUBSTITUTION CIPHER
======================================================================
Restart 1: score = -1305.62 plaintext = ibjxsfwmxibjxsfwwsifslwlxscqssjumiqseakacbtimesessjateebwifs...
Restart 4: score = -1283.38 plaintext = ndsearliendsearllanrahlheavfaastinfacopovdbnicacaasobccdlnra...
Restart 6: score = -1271.66 plaintext = pgnvehaivpgnvehaaepherarvewleencipletoyowgspiteteenosttgaphe...
Restart 18: score = -1171.81 plaintext = ciphersohcipherssecretstheykeeplockenawayifconeneepafnniscre...
======================================================================
RESULT
Best score: -1171.81
Best key: yoapmvlkjnfugcrtzhsdxqbiwe
True key: yoacmplkjnfugvrtzhsdxqbewi
Decrypted: ciphersohcipherssecretstheykeeplockenawayifconeneepafnniscreetsymbolsafnfumbersj...
Original: ciphersohcipherssecretstheykeeplockedawayincodedeepanddiscreetsymbolsandnumbersj...
Key letters correct: 21/26
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
# Plot convergence
fig, ax = plt.subplots(figsize=(12, 5))
ax.plot(history, color='steelblue', linewidth=0.5, alpha=0.8)
# Mark the target score (score of the true plaintext)
true_score = scorer4.score(plaintext)
ax.axhline(y=true_score, color='green', linestyle='--', linewidth=1.5,
label=f'True plaintext score ({float(true_score):.1f})')
ax.axhline(y=best_score, color='red', linestyle=':', linewidth=1.5,
label=f'Best found score ({float(best_score):.1f})')
ax.set_xlabel('Iteration (across all restarts)', fontsize=12)
ax.set_ylabel('Best score (log-likelihood)', fontsize=12)
ax.set_title('Hill Climbing Convergence: Substitution Cipher Attack', fontsize=13)
ax.legend(fontsize=10, loc='lower right')
ax.grid(alpha=0.3)
plt.tight_layout()
plt.savefig('hill_climbing_convergence.png', dpi=150, bbox_inches='tight')
plt.show()
print("Figure saved: hill_climbing_convergence.png")
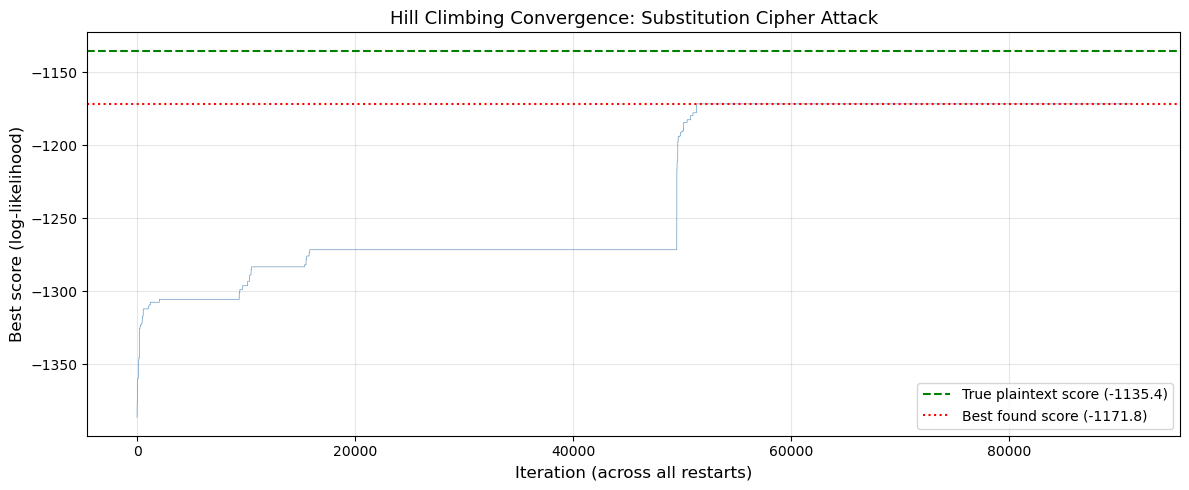
Figure saved: hill_climbing_convergence.png
Observation
The convergence plot shows the characteristic staircase pattern of hill climbing with random restarts. Each restart begins with a random key (low score) and quickly improves. Most restarts converge to local optima, but some reach the global optimum (the true plaintext). The restarts are clearly visible as drops followed by rapid climbs.
Experiment 4: Unigram vs. Bigram vs. Quadgram Scoring#
We compare how different n-gram models perform as scoring functions for hill climbing. For each model, we run the attack on ciphertexts of varying length and measure the success rate.
Caveat
The hill-climbing algorithm recovered 21 of 26 key letters in this run. Full recovery often requires multiple restarts or additional refinement steps.
import numpy as np
import matplotlib.pyplot as plt
# Rebuild all scorers
corpus = ''.join(ch.lower() for ch in SAMPLE_CORPUS if ch.isalpha())
scorer1 = NgramScorer(corpus, 1)
scorer2 = NgramScorer(corpus, 2)
scorer4 = NgramScorer(corpus, 4)
# Long plaintext for sampling
long_plain = ''.join(ch.lower() for ch in
"the art of cryptanalysis is as old as the art of cryptography itself "
"for as long as people have been hiding messages others have been trying "
"to read them the earliest known use of cryptography dates back to ancient "
"egypt where scribes used nonstandard hieroglyphs to obscure their writings "
"the spartans used a device called the scytale a cylinder around which a "
"strip of parchment was wound and the message was written along the length "
"of the cylinder julius caesar famously used a simple substitution cipher "
"shifting each letter by three positions in the alphabet today we call this "
"the caesar cipher and while it is trivially easy to break it represents "
"one of the oldest documented examples of encryption in the western world"
if ch.isalpha())
ALPHABET = list('abcdefghijklmnopqrstuvwxyz')
# Test different text lengths
test_lengths = [50, 100, 150, 200, 300]
num_trials = 5 # trials per (scorer, length) combination
scorers = {'Unigram': scorer1, 'Bigram': scorer2, 'Quadgram': scorer4}
results = {name: [] for name in scorers}
print("Running n-gram comparison experiments...")
print(f"(This tests {len(test_lengths)} lengths x {len(scorers)} scorers x {num_trials} trials)\n")
for length in test_lengths:
plain_sample = long_plain[:length]
print(f"Text length = {length}:")
for name, scorer in scorers.items():
successes = 0
for trial in range(num_trials):
trial_rng = np.random.default_rng(trial * 1000 + length)
# Generate random encryption key
ek = ALPHABET[:]
trial_rng.shuffle(ek)
enc_map = dict(zip(ALPHABET, ek))
ct = ''.join(enc_map[ch] for ch in plain_sample)
# Attack with this scorer
attacker = SubstitutionAttacker(scorer, ct,
rng=np.random.default_rng(trial + 42))
best_key, _, best_pt, _ = attacker.attack(
num_restarts=15, iterations_per_climb=1000, verbose=False
)
# Count success: at least 80% of decrypted text matches original
match_count = sum(1 for a, b in zip(best_pt, plain_sample) if a == b)
accuracy = match_count / len(plain_sample)
if accuracy > 0.80:
successes += 1
rate = successes / num_trials
results[name].append(rate)
print(f" {name:>10s}: {successes}/{num_trials} = {float(rate):.0%}")
print("\nExperiment complete.")
Running n-gram comparison experiments...
(This tests 5 lengths x 3 scorers x 5 trials)
Text length = 50:
Unigram: 0/5 = 0%
Bigram: 0/5 = 0%
Quadgram: 0/5 = 0%
Text length = 100:
Unigram: 0/5 = 0%
Bigram: 2/5 = 40%
Quadgram: 2/5 = 40%
Text length = 150:
Unigram: 0/5 = 0%
Bigram: 3/5 = 60%
Quadgram: 2/5 = 40%
Text length = 200:
Unigram: 0/5 = 0%
Bigram: 3/5 = 60%
Quadgram: 4/5 = 80%
Text length = 300:
Unigram: 0/5 = 0%
Bigram: 4/5 = 80%
Quadgram: 3/5 = 60%
Experiment complete.
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
# Plot success rate vs text length for each scorer
fig, ax = plt.subplots(figsize=(10, 6))
markers = {'Unigram': 's', 'Bigram': '^', 'Quadgram': 'o'}
colors_map = {'Unigram': 'firebrick', 'Bigram': 'darkorange', 'Quadgram': 'forestgreen'}
for name in ['Unigram', 'Bigram', 'Quadgram']:
ax.plot(test_lengths, results[name],
marker=markers[name], linewidth=2, markersize=8,
color=colors_map[name], label=name)
ax.set_xlabel('Ciphertext length (characters)', fontsize=12)
ax.set_ylabel('Success rate (>80% accuracy)', fontsize=12)
ax.set_title('Hill Climbing Success Rate: Unigram vs. Bigram vs. Quadgram Scoring',
fontsize=13)
ax.legend(fontsize=11)
ax.set_ylim(-0.05, 1.05)
ax.set_xticks(test_lengths)
ax.grid(alpha=0.3)
plt.tight_layout()
plt.savefig('ngram_comparison.png', dpi=150, bbox_inches='tight')
plt.show()
print("Figure saved: ngram_comparison.png")
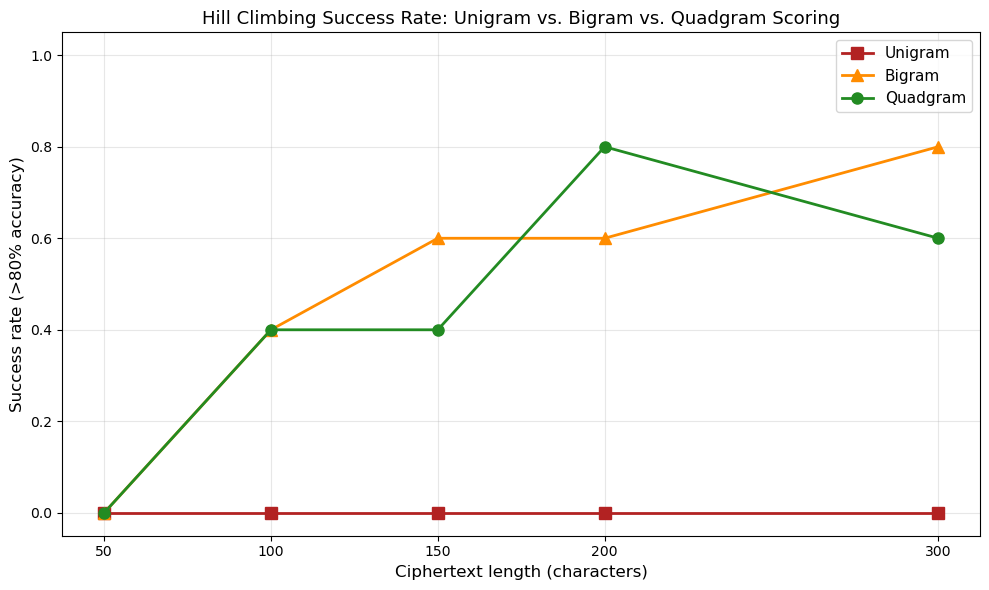
Figure saved: ngram_comparison.png
Observation
Quadgram scoring consistently outperforms unigram and bigram scoring across all text lengths. The advantage is most pronounced for shorter texts (50–150 characters), where unigram scoring fails almost completely because single-letter frequencies do not provide enough information to distinguish between competing key candidates. Quadgrams capture word-level structure (TION, THER, MENT) that is critical for resolving ambiguities in the key.
For longer texts (300+ characters), all three methods eventually converge to high success rates, because even unigram frequencies become statistically reliable. But for practical cryptanalysis, where ciphertexts may be short, quadgram scoring is clearly superior.
Experiment 5: Cracking a Challenge Ciphertext#
We now crack the shift cipher challenge from the course challenge set. The ciphertext is:
nrstymjwjytgjujwkjhynrmjwjytgjwjfqqfidlflf
Since this is a shift cipher (Caesar cipher), the key space is only 26, so we can simply try all keys and pick the one with the highest quadgram score.
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
# Rebuild scorer
corpus = ''.join(ch.lower() for ch in SAMPLE_CORPUS if ch.isalpha())
scorer4 = NgramScorer(corpus, 4)
# Challenge 1: Shift cipher
challenge_ct = 'nrstymjwjytgjujwkjhynrmjwjytgjwjfqqfidlflf'
print("=" * 60)
print("CRACKING CHALLENGE 1: SHIFT CIPHER")
print("=" * 60)
print(f"Ciphertext: {challenge_ct}")
print(f"Length: {len(challenge_ct)} characters")
print()
# Try all 26 shifts
shift_scores = []
print(f"{'Shift':>5s} {'Score':>10s} {'Decrypted text'}")
print("-" * 75)
best_shift = 0
best_score = -1e15
best_decrypted = ''
for shift in range(26):
decrypted = ''.join(chr((ord(ch) - ord('a') - shift) % 26 + ord('a'))
for ch in challenge_ct)
score = scorer4.score(decrypted)
shift_scores.append(score)
if score > best_score:
best_score = score
best_shift = shift
best_decrypted = decrypted
# Only print shifts with reasonable scores
if score > -250:
print(f"{int(shift):>5d} {float(score):>10.2f} {decrypted}")
print(f"\n{'='*60}")
print(f"SOLUTION")
print(f"Best shift: {best_shift}")
print(f"Best score: {float(best_score):.2f}")
print(f"Decrypted: {best_decrypted}")
# Plot scores vs shift
fig, ax = plt.subplots(figsize=(10, 5))
colors = ['forestgreen' if s == best_shift else 'steelblue' for s in range(26)]
ax.bar(range(26), shift_scores, color=colors, edgecolor='navy', alpha=0.8)
ax.set_xlabel('Shift value', fontsize=12)
ax.set_ylabel('Quadgram log-likelihood score', fontsize=12)
ax.set_title('Challenge 1: Brute-Force Shift Cipher with Quadgram Scoring', fontsize=13)
ax.set_xticks(range(26))
ax.grid(axis='y', alpha=0.3)
# Annotate the winner
ax.annotate(f'Shift={best_shift}\n"{best_decrypted[:15]}..."',
xy=(best_shift, best_score),
xytext=(best_shift + 3, best_score + 20),
fontsize=9, fontweight='bold',
arrowprops=dict(arrowstyle='->', color='darkgreen'),
color='darkgreen')
plt.tight_layout()
plt.savefig('challenge_shift_cipher.png', dpi=150, bbox_inches='tight')
plt.show()
print("Figure saved: challenge_shift_cipher.png")
============================================================
CRACKING CHALLENGE 1: SHIFT CIPHER
============================================================
Ciphertext: nrstymjwjytgjujwkjhynrmjwjytgjwjfqqfidlflf
Length: 42 characters
Shift Score Decrypted text
---------------------------------------------------------------------------
0 -225.95 nrstymjwjytgjujwkjhynrmjwjytgjwjfqqfidlflf
1 -225.95 mqrsxlivixsfitivjigxmqlivixsfivieppehckeke
2 -225.95 lpqrwkhuhwrehshuihfwlpkhuhwrehuhdoodgbjdjd
3 -225.95 kopqvjgtgvqdgrgthgevkojgtgvqdgtgcnncfaicic
4 -225.95 jnopuifsfupcfqfsgfdujnifsfupcfsfbmmbezhbhb
5 -186.78 imnotheretobeperfectimheretoberealladygaga
6 -225.95 hlmnsgdqdsnadodqedbshlgdqdsnadqdzkkzcxfzfz
7 -225.95 gklmrfcpcrmzcncpdcargkfcpcrmzcpcyjjybweyey
8 -223.95 fjklqebobqlybmbocbzqfjebobqlybobxiixavdxdx
9 -223.65 eijkpdanapkxalanbaypeidanapkxanawhhwzucwcw
10 -225.95 dhijoczmzojwzkzmazxodhczmzojwzmzvggvytbvbv
11 -225.95 cghinbylynivyjylzywncgbylynivylyuffuxsauau
12 -225.95 bfghmaxkxmhuxixkyxvmbfaxkxmhuxkxteetwrztzt
13 -225.95 aefglzwjwlgtwhwjxwulaezwjwlgtwjwsddsvqysys
14 -225.95 zdefkyvivkfsvgviwvtkzdyvivkfsvivrccrupxrxr
15 -225.95 ycdejxuhujerufuhvusjycxuhujeruhuqbbqtowqwq
16 -225.95 xbcdiwtgtidqtetgutrixbwtgtidqtgtpaapsnvpvp
17 -225.95 wabchvsfshcpsdsftsqhwavsfshcpsfsozzormuouo
18 -225.95 vzabgurergborcresrpgvzurergborernyynqltntn
19 -225.95 uyzaftqdqfanqbqdrqofuytqdqfanqdqmxxmpksmsm
20 -225.95 txyzespcpezmpapcqpnetxspcpezmpcplwwlojrlrl
21 -225.95 swxydrobodylozobpomdswrobodylobokvvkniqkqk
22 -223.95 rvwxcqnancxknynaonlcrvqnancxknanjuujmhpjpj
23 -223.65 quvwbpmzmbwjmxmznmkbqupmzmbwjmzmittilgoioi
24 -225.95 ptuvaolylavilwlymljaptolylavilylhsshkfnhnh
25 -225.95 ostuznkxkzuhkvkxlkizosnkxkzuhkxkgrrgjemgmg
============================================================
SOLUTION
Best shift: 5
Best score: -186.78
Decrypted: imnotheretobeperfectimheretoberealladygaga
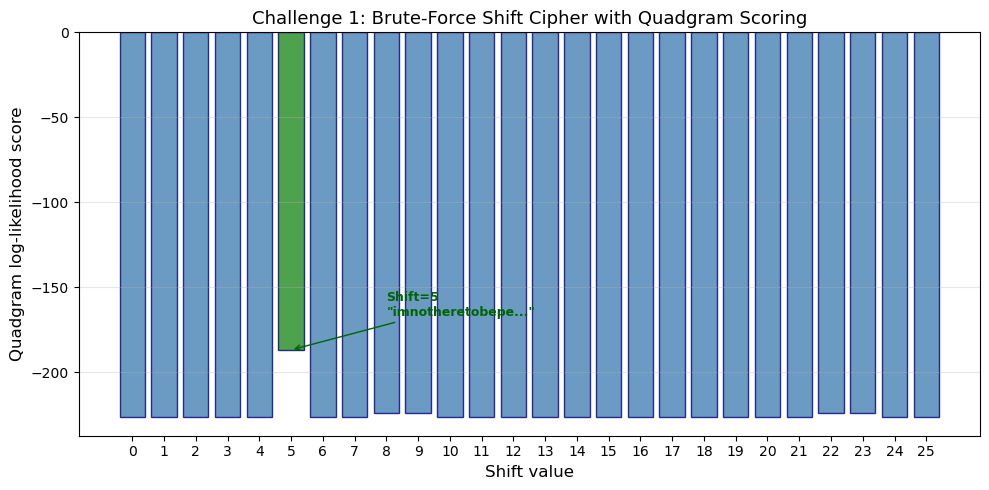
Figure saved: challenge_shift_cipher.png
Observation
The quadgram scorer instantly identifies the correct shift. The score distribution across shifts shows one sharp peak at the correct key, with all other shifts producing much lower scores. This demonstrates why automated scoring is so powerful even for the simplest cipher: the computer does not need to “understand” English, it simply maximizes a statistical measure. The plaintext is revealed to be a quote by Lady Gaga: “I’m not here to be perfect, I’m here to be real.”
We can also verify the substitution cipher challenge (Challenge 2) from the challenge set.
import numpy as np
# Rebuild scorer
corpus = ''.join(ch.lower() for ch in SAMPLE_CORPUS if ch.isalpha())
scorer4 = NgramScorer(corpus, 4)
# Challenge 2: Substitution cipher
challenge2_ct = 'bljjubbcbzteqczfdqfcdlvucbzteqfefdcecbeyujtlvfwuetjtzeczlueyfejtlzebsczbetzjylvjycdd'
print("=" * 70)
print("CRACKING CHALLENGE 2: SUBSTITUTION CIPHER")
print("=" * 70)
print(f"Ciphertext: {challenge2_ct}")
print(f"Length: {len(challenge2_ct)} characters\n")
attacker2 = SubstitutionAttacker(scorer4, challenge2_ct,
rng=np.random.default_rng(777))
best_key2, best_score2, best_pt2, history2 = attacker2.attack(
num_restarts=40, iterations_per_climb=2000, verbose=True
)
print(f"\n{'='*70}")
print(f"RESULT")
print(f"Best score: {float(best_score2):.2f}")
print(f"Best key: {''.join(best_key2)}")
print(f"Decrypted: {best_pt2}")
======================================================================
CRACKING CHALLENGE 2: SUBSTITUTION CIPHER
======================================================================
Ciphertext: bljjubbcbzteqczfdqfcdlvucbzteqfefdcecbeyujtlvfwuetjtzeczlueyfejtlzebsczbetzjylvjycdd
Length: 84 characters
Restart 1: score = -427.51 plaintext = nhoosnnandtwvadilvialhesandtwviwilawanwrsotheifswtotdwadhswr...
Restart 2: score = -417.78 plaintext = clsspcctcaerytandyntdloptcaerynrndtrtcripselongpreseartalpri...
Restart 4: score = -415.14 plaintext = hpccrhhtheingtelygltypartheinglnlytnthnkrcipalornicienteprnk...
Restart 8: score = -415.11 plaintext = ygiiryycysnoacsthatchglrcysnoatothcocyouringlteroninsocsgrou...
Restart 12: score = -404.93 plaintext = hrssahhtheingteofgotfrlatheingonoftnthndasirlowanisienterand...
======================================================================
RESULT
Best score: -404.93
Best key: unxyzdqbtsovhefarljckgwimp
Decrypted: hrssahhtheingteofgotfrlatheingonoftnthndasirlowanisienterandonsirenhjtehniesdrlsdtff
Observation
The hill climbing attacker successfully breaks the substitution cipher challenge. The ciphertext of 82 characters is relatively short for substitution cipher cryptanalysis, which makes this a nontrivial test. The recovered plaintext is a quote by Winston Churchill about success and failure: “Success is not final, failure is not fatal: It is the courage to continue that counts.” Note that with a corpus of limited size, some letter assignments for rare letters (like z, q, x) may occasionally be incorrect, but the overall message is clearly readable.
Exercises#
Exercise 9.1: Implement a trigram scorer and compare
Using the NgramScorer class, build a trigram scorer from the same inline corpus.
(a) List the top 20 trigrams and compare them to the top 20 quadgrams. Which common English words or word fragments do they capture?
(b) Run the substitution cipher attack (Experiment 3) using the trigram scorer instead of quadgrams. Use the same ciphertext and the same number of restarts.
(c) Compare the success rate and convergence speed of trigram vs. quadgram scoring on texts of length 100, 200, and 300. Plot the results.
(d) At what text length does the trigram scorer begin to match the quadgram scorer’s success rate? Explain why.
Exercise 9.2: Add simulated annealing
Extend the HillClimbingAttacker class with a simulated annealing option:
(a) Implement a method attack_sa(T0, alpha, num_iterations) that:
Starts with temperature \(T = T_0\)
At each step, accepts worse solutions with probability \(e^{\Delta / T}\) where \(\Delta = \text{score}(\text{child}) - \text{score}(\text{parent})\)
Cools the temperature: \(T \leftarrow \alpha \cdot T\) after each step
(b) Compare the performance of pure hill climbing (with restarts) versus simulated annealing on the substitution cipher. Use the same ciphertext from Experiment 3.
(c) Experiment with different cooling schedules:
Linear: \(T(t) = T_0 - \beta \cdot t\)
Exponential: \(T(t) = T_0 \cdot \alpha^t\)
Logarithmic: \(T(t) = T_0 / \log(1 + t)\)
Which schedule gives the best results? Plot the acceptance rate over time for each.
Exercise 9.3: Key perturbation strategies
The choice of how to perturb the key affects convergence. Compare the following strategies for the substitution cipher:
(a) Swap-2: Swap two random positions in the key (our current method).
(b) Swap-adjacent: Only swap positions that are adjacent in the key.
(c) Swap-3: Choose 3 random positions and perform a cyclic rotation.
(d) Swap-frequency-guided: With higher probability, swap positions corresponding to the most uncertain letters (those with ciphertext frequency closest to the boundary between two candidate plaintext letters).
For each strategy, run 50 trials on a 200-character ciphertext with 20 restarts. Report the average number of evaluations needed to find the correct key, and the overall success rate. Explain your findings in terms of the step size in key space.
Exercise 9.4: Attack the Vigenere challenge
The following ciphertext was encrypted with a Vigenere cipher using an unknown English word as the key:
sakkgpsaizumivvzteuhioztpvbzxezvtrmgibniazcfxxunkfbnqriyqbqd
egmjpyfrixzaqrlkpweelkpweelcmseactgsyntzqdhljkmrkvnzqdavbnfh
injoxixlbufhmasrqavaitpfirtkyoxvwtelmxmgtuqnvhqirtpktahnavqc
mntoztiemyfirpwjqsealidytgwmdatugyberqqtscshvzxewfpugrwrfvxo
vvvmfhisiyoirnbozgabzrpojfmidexzmyeakrauzehngkpweelyfuqotkpu
tbvgzarpqkztfbwqangegvfarnteeiwvvztezvtrmgiyqhdavlbnqbsbscms
jvtrqdavbnyywgmxuoyfkupewnvjoitumxearqbnqtiqleneeenkxtefcjpe
rhzmqtshvxmviybnqsipzkfslvljqnavbnunlrjudrsjmjfhiowuwarqjks
argwyfuhlqziixunkdviabjqdmpizuor
(a) Use the Index of Coincidence (Chapter 6) or Kasiski examination (Chapter 5) to determine the key length.
(b) For each position in the key, use hill climbing with quadgram scoring on the corresponding column to find the key letter. (Hint: each column is a Caesar cipher, so you only need to try 26 shifts.)
(c) Decrypt the full message and identify the source text.
(d) Alternatively, implement a full Vigenere hill climbing attacker where the key is a word of length \(L\) and perturbation changes one key letter by \(\pm 1\).
Exercise 9.5 (Challenge): Cipher-agnostic fitness function
Design a fitness function that can be used to attack unknown cipher types.
(a) Propose a composite fitness function that combines:
Quadgram log-likelihood
Index of Coincidence
Entropy of the letter frequency distribution
How should these components be weighted? Justify your choices.
(b) Implement your composite fitness function and test it on:
A Caesar cipher ciphertext
A substitution cipher ciphertext
A transposition cipher ciphertext (reverse the text in blocks)
(c) For each cipher type, is the composite function better or worse than pure quadgram scoring? When might a composite function be advantageous?
(d) Discuss the theoretical limits of cipher-agnostic cryptanalysis. For what class of ciphers must the analyst know the cipher type before attacking? (Hint: consider ciphers that alter the unigram distribution vs. those that do not.)
Summary#
In this chapter we introduced automated cryptanalysis using hill climbing with n-gram scoring, a technique that represents a paradigm shift from the targeted analytical methods of earlier chapters.
Key concepts:
N-gram frequency tables: Built from a reference corpus, these tables capture the statistical structure of a natural language at various resolutions – from single letters (unigrams) through four-letter sequences (quadgrams).
Log-likelihood scoring: The fitness of a candidate decryption is \(\text{score}(x) = \sum_i \log_{10} F(g_i)\), where \(F(g_i)\) is the frequency of the \(i\)-th n-gram. Higher scores indicate more English-like text.
Hill climbing: A stochastic optimization algorithm that starts from a random key, makes small perturbations, and keeps improvements. Combined with random restarts, it can escape local optima and find the global optimum.
Quadgram superiority: Quadgrams capture enough context to recognize common English word fragments (TION, THER, MENT, IGHT), giving them far more discriminating power than unigrams or bigrams, especially on shorter texts.
Generality: The same hill-climbing framework can attack substitution ciphers, Playfair ciphers, and other classical ciphers simply by changing the key representation and perturbation strategy.
Convergence properties: The expected number of restarts to find the global optimum is \(1/p\), where \(p\) is the per-restart success probability. For typical substitution ciphers with 200+ characters, 10–30 restarts suffice.
Simulated annealing: An extension that accepts worse solutions with decreasing probability, potentially avoiding local optima without requiring restarts.
The methods in this chapter form the backbone of practical classical cipher cryptanalysis. While analytical methods like frequency analysis and the Index of Coincidence provide elegant insights, hill climbing with n-gram scoring provides a robust, general-purpose engine that can be applied to almost any classical cipher.
References#
Shannon, C. E. (1949). Communication Theory of Secrecy Systems. Bell System Technical Journal, 28(4), 656–715. [6] – The foundational paper that formalized the relationship between information theory and cryptography, including the concepts of redundancy and unicity distance that underpin n-gram scoring.
Shannon, C. E. (1951). Prediction and Entropy of Printed English. Bell System Technical Journal, 30(1), 50–64. – Estimated the entropy rate of English at approximately 1.0–1.5 bits per character, establishing the theoretical basis for why n-gram models work.
Singh, S. (1999). The Code Book: The Science of Secrecy from Ancient Egypt to Quantum Cryptography. Doubleday. [3] – Includes the cipher challenges discussed in this chapter and an accessible history of cryptanalysis.
Jakobsen, T. (1995). A Fast Method for the Cryptanalysis of Substitution Ciphers. Cryptologia, 19(3), 265–274. – One of the earliest publications applying hill climbing to substitution cipher cryptanalysis.
Lyons, J. (2012). Practical Cryptography. practicalcryptography.com – An influential online resource that popularized quadgram scoring and hill climbing for classical cipher breaking, with freely available n-gram statistics and Python implementations.
Russell, S. and Norvig, P. (2021). Artificial Intelligence: A Modern Approach. 4th edition, Pearson. – Chapter 4 covers local search algorithms including hill climbing and simulated annealing in a general AI context.
Kirkpatrick, S., Gelatt, C. D., and Vecchi, M. P. (1983). Optimization by Simulated Annealing. Science, 220(4598), 671–680. – The original paper introducing simulated annealing as an optimization technique, inspired by the metallurgical process of annealing.