The experiment
What does the Chapter 41 decoder-only Transformer learn from different streams of symbols? Twelve copies of the same model, same hyperparameters, same training script — only the corpus changes. The contrast is the data, not the architecture.
Eight genres are drawn from the music21 built-in corpora — six centuries of Western classical / folk repertoire, plus a synthetic 12-tone control case. Four are synthesised programmatically from genre-characteristic patterns — heavy metal power chords, rock chord-progressions, pop melody templates, and a hip-hop drum pattern — because public-domain MIDI of these genres is scarce. Each synthesised genre captures the most identifiable musical features of its style; the model then learns the rest from the symbol stream.
Tokenisation is event-based: each note becomes a NOTE_ON_<p> /
NOTE_OFF_<p> pair separated by TIME_SHIFT_<d> tokens
(d in 16th-note units). Total vocab: 291 tokens. Architecture: 3-layer decoder-only
Transformer, d_model=128, n_heads=4, max_len=256, ~400 K parameters.
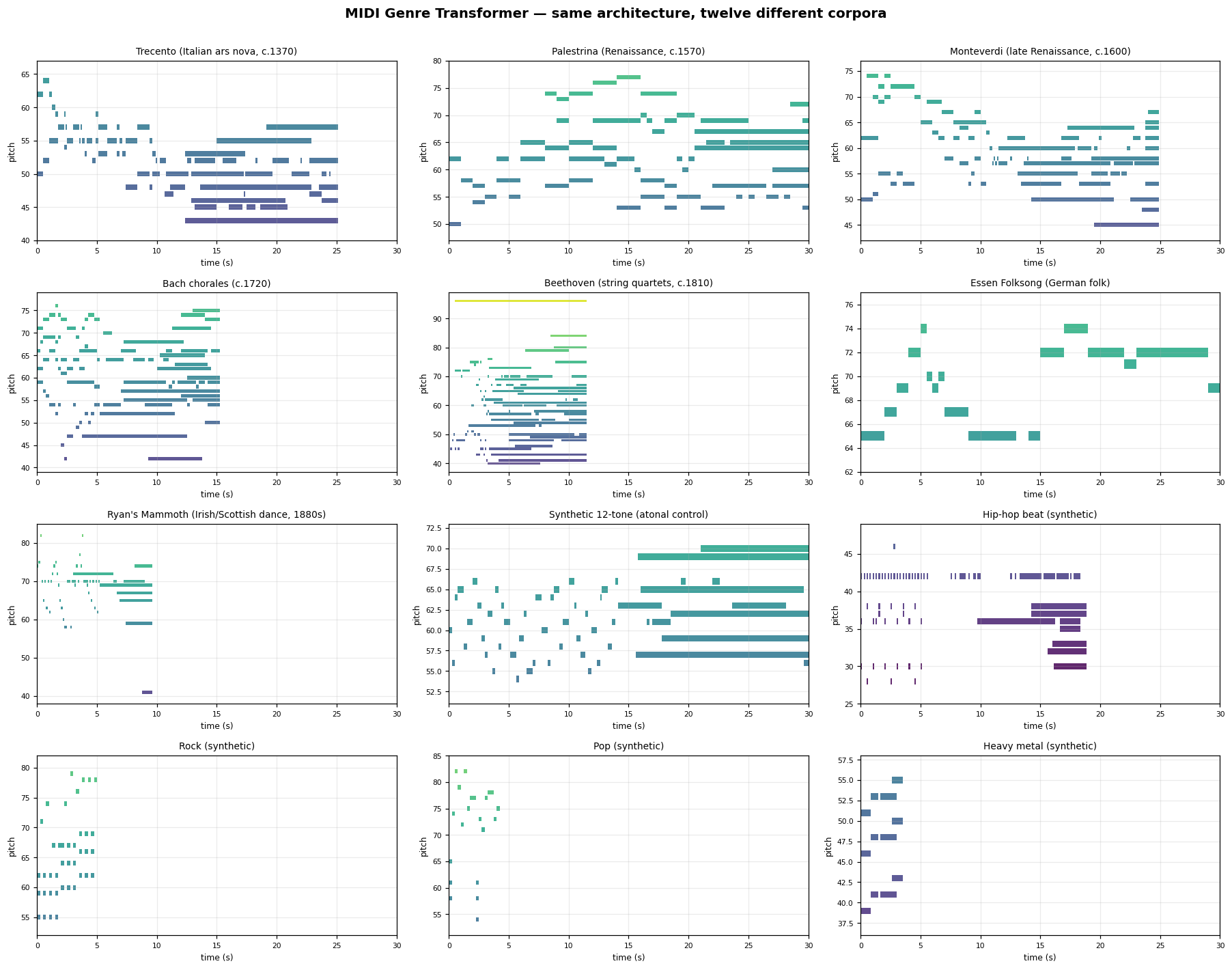
Generated samples — all 12 genres
Each model sampled ~30 seconds autoregressively from a single [BOS] token,
temperature 0.9, top-k 40. Click any .mid file to download and play. Piano-roll
previews below show the first 30 seconds; horizontal axis is time, vertical axis is MIDI pitch.
Pre-baroque polyphony
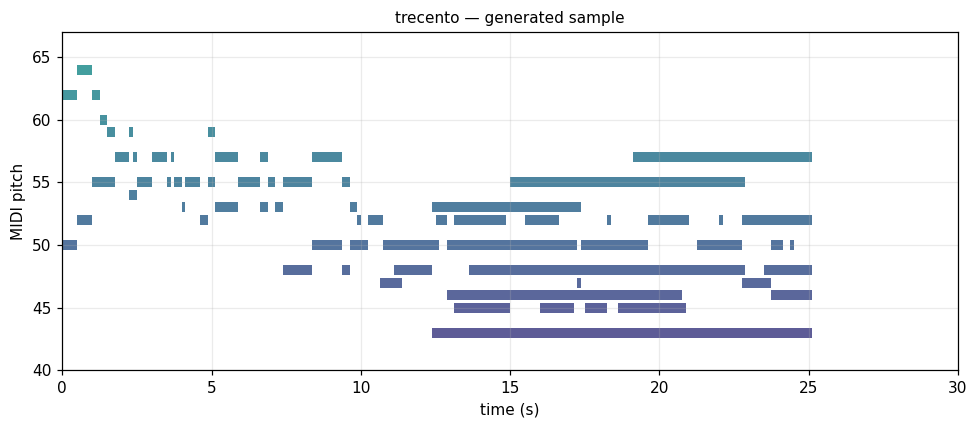
Trecento Italian ars nova, c.1370
14th-c. Italian secular polyphony. Modal, rhythmically complex, bass-heavy. music21
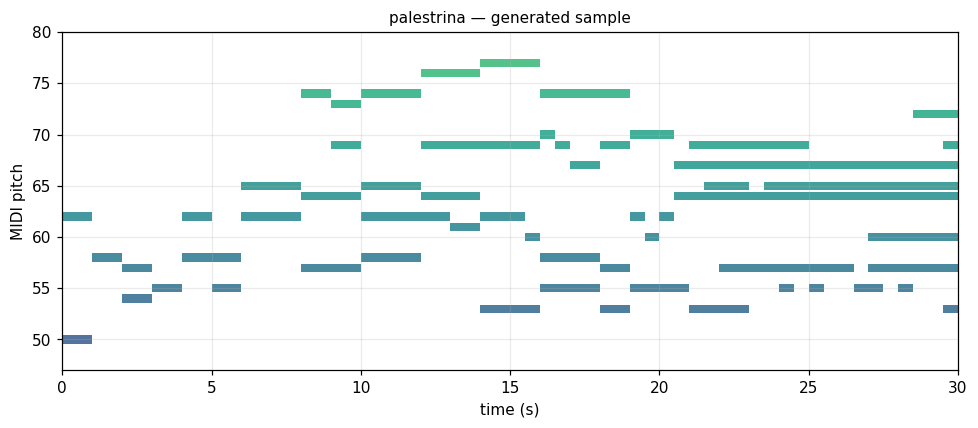
Palestrina Renaissance, c.1570
Modal sacred polyphony. Stepwise voice-leading, long durations. music21
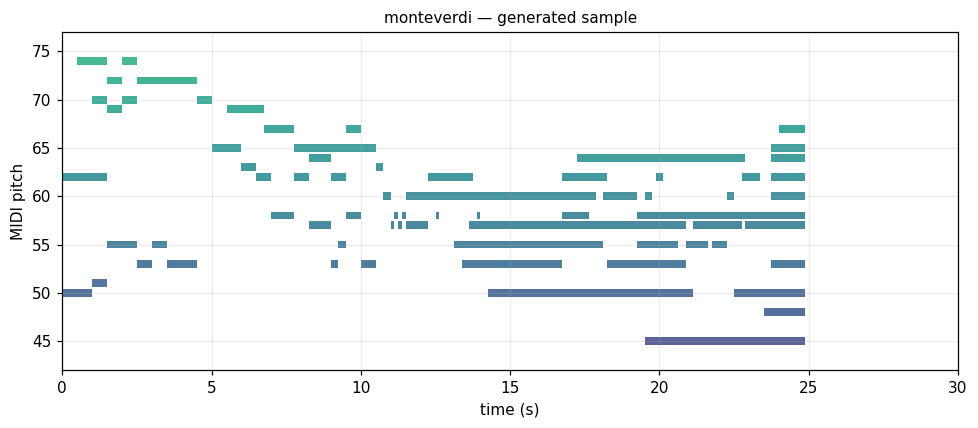
Tonal Western classical / folk
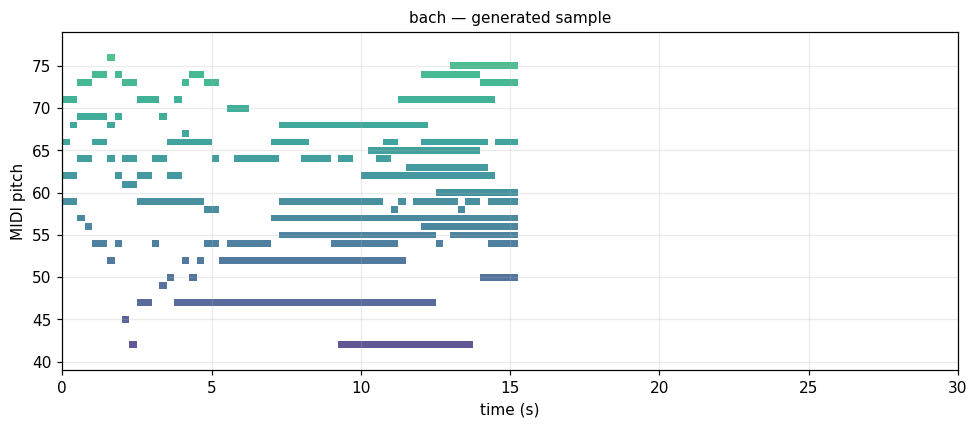
Bach chorales c.1720
Tonal 4-voice polyphony. Dense vertical sonorities, V-I cadences. music21
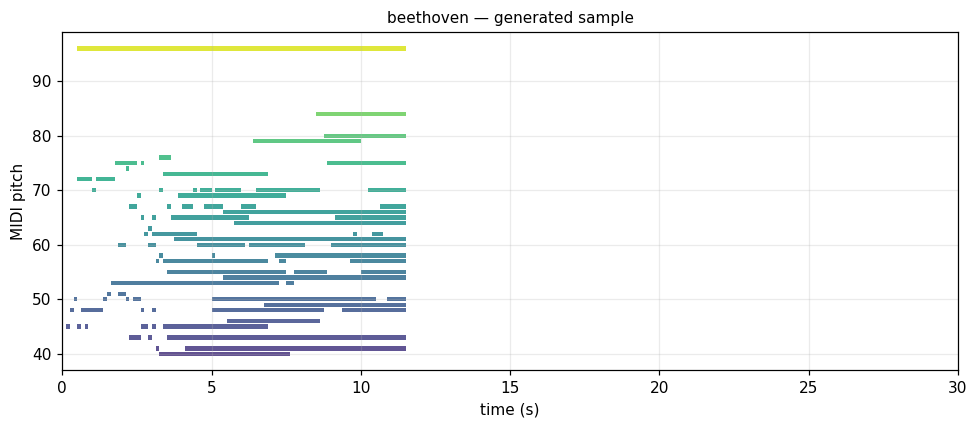
Beethoven Classical/Romantic, c.1810
String quartets. Sonata-form, modulations through distant keys. music21
Pre-modern dance + atonal control
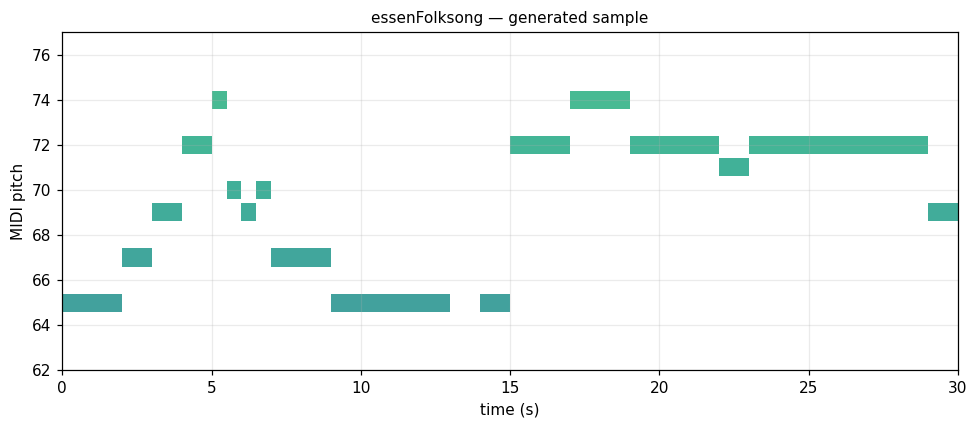
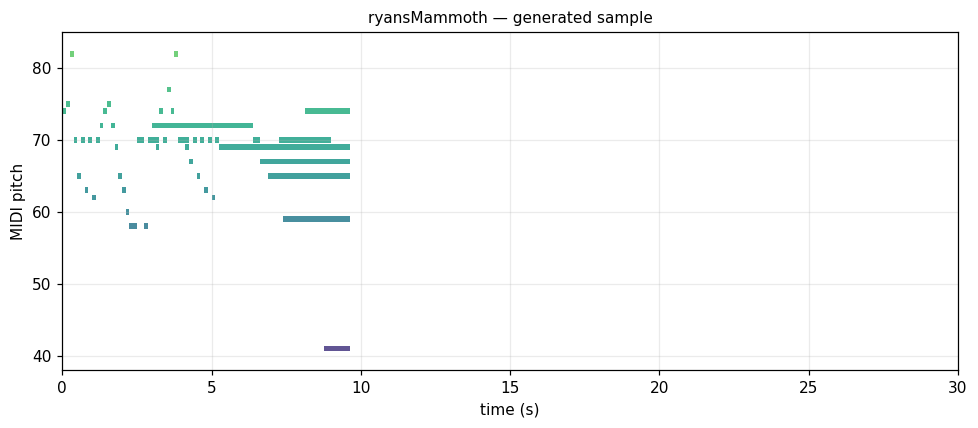
Ryan's Mammoth Irish/Scottish dance, 1880s
Jigs, reels, hornpipes. Monophonic, fast 8ths, narrow register. music21
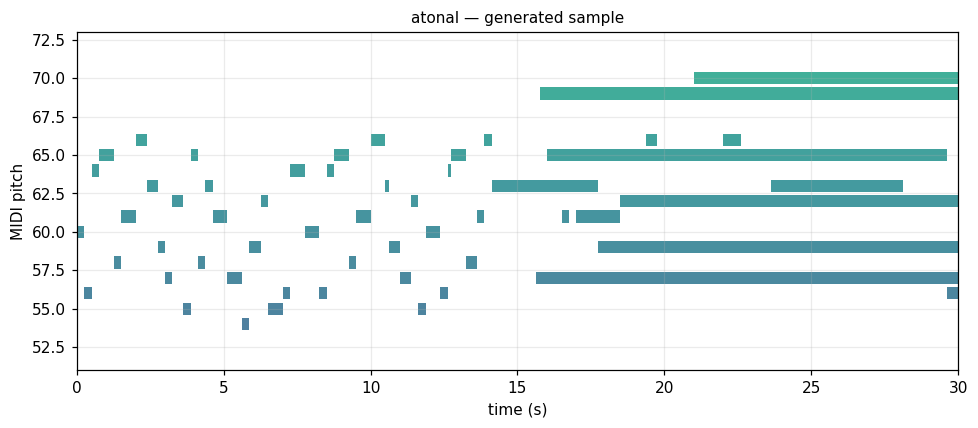
Atonal (12-tone) control case
Synthetic Schoenberg-style 12-tone rows with random rhythms. Tests what the model learns without tonal grammar. synthetic
Modern popular genres
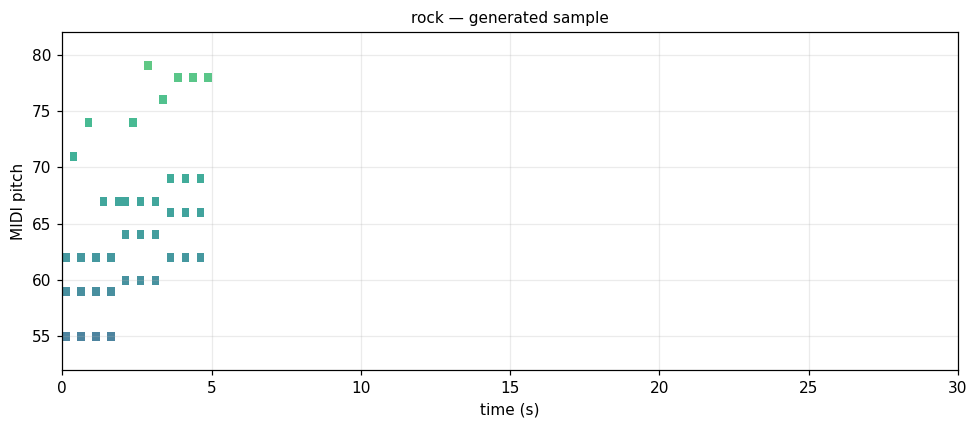
Rock I-IV-V, backbeat
Mid-register triads (I-IV-V or I-V-vi-IV), melody on offbeats. synthetic
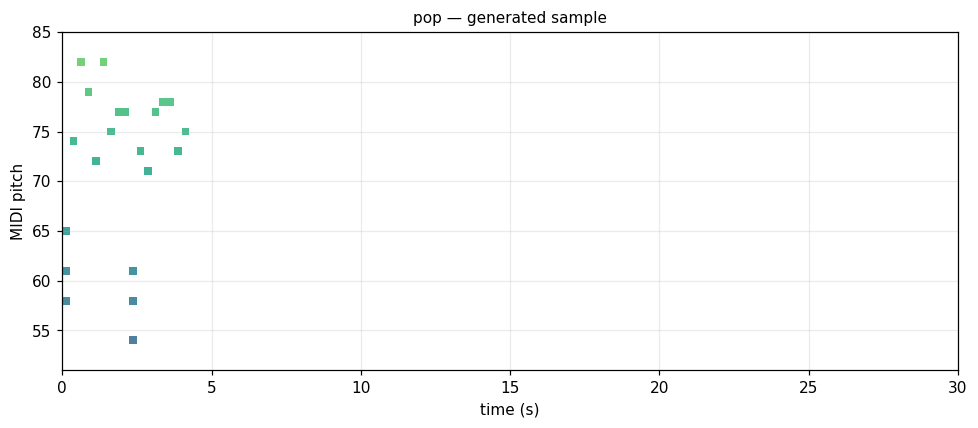
Pop I-V-vi-IV, melody-driven
Predictable chord progressions, high-register melody, even 8th-note flow. synthetic
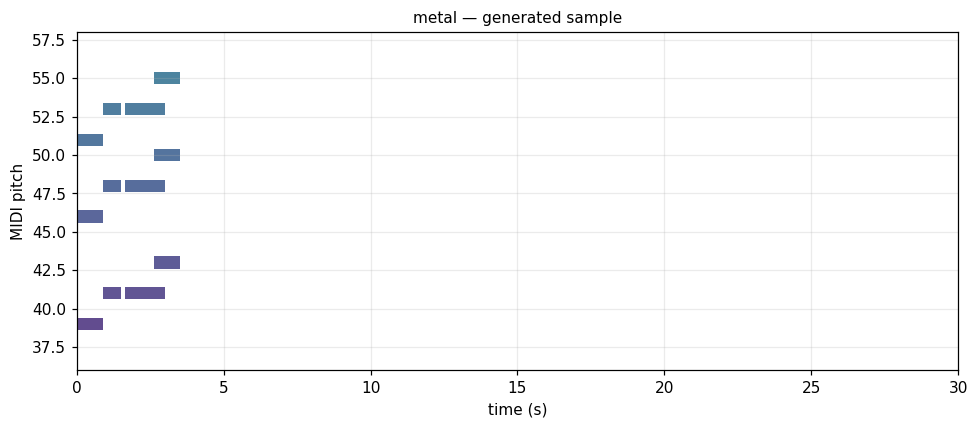
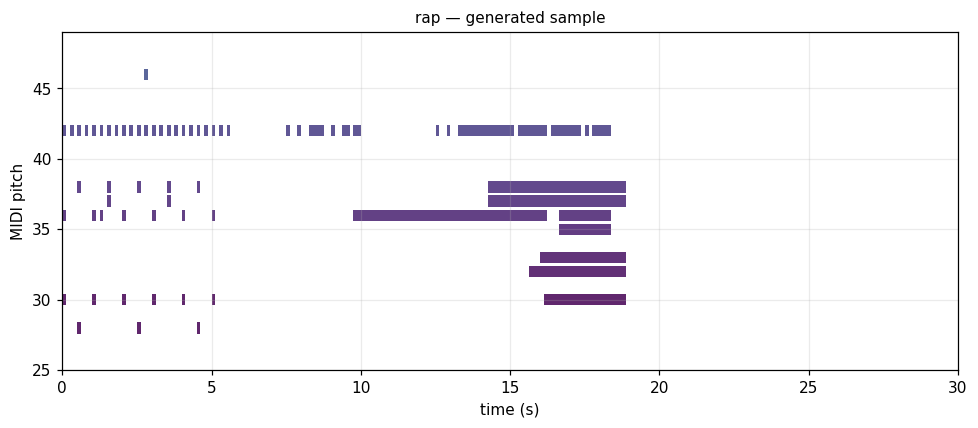
All twelve samples side-by-side
The code
Four files in experiments/midi_genres/:
midi_tokenizer.py— event-based MIDI tokeniser.NOTE_ON_<p>,NOTE_OFF_<p>,TIME_SHIFT_<d>with full round-trip support.train_genres.py— the experiment driver. Music21 corpus loaders + Opus expansion + four synthetic generators (atonal, metal, rock, pop, rap) + training loop + per-genre piano-roll generation.build_comparison.py— assembles the 12-panel comparison plot from existingsamples/*.mid.checkpoints/<genre>.pt— pre-trained weights for each of the 12 genres.
Reproducing the experiment
git clone https://github.com/nasqret/classical-foundations-ann cd classical-foundations-ann/experiments/midi_genres pip install torch music21 pretty_midi matplotlib # train all 12 — about 25 minutes on a laptop CPU python train_genres.py --steps 1200 \ --genres bach,palestrina,trecento,ryansMammoth,\ monteverdi,beethoven,essenFolksong,atonal,\ metal,rock,pop,rap # regenerate the 12-panel comparison plot python build_comparison.py
The architecture is the Chapter 41 model, unchanged
vocab_size = 291 # event-based MIDI vocabulary d_model = 128 n_heads = 4 n_layers = 3 max_len = 256 parameters = ~400 K training = 1200 steps Adam + cosine LR, ~2 min/genre on CPU
The point is exactly that the architecture is uninteresting. The interesting thing is the data — and what the same machinery learns from twelve different streams of symbols. This flips the Chapter 41 thesis ("the mask matrix is the worldview"): the architecture is shared, the data is the worldview.
Open ends
- Cross-genre prompting. Feed the Bach model a Trecento prefix. Does the Bach model "Bach-ify" the continuation? Does the pop model refuse?
- Conditional generation. Tag every piece with a leading
[GENRE_<name>]token, train one combined model on all 12 corpora, condition at generation time. - Real metal / pop / rap MIDIs. Replace the synthetic generators with curated subsets of the Lakh MIDI Dataset (matched genre labels). The architecture stays the same; the comparison gets more interesting.
- REMI-style tokenisation. Use bar-position + chord + tempo tokens (Huang & Yang, ISMIR 2020). Better long-range structure, longer sequences.
- Audio rendering. Use
fluidsynthormidi2audioto render.midto WAV/MP3 directly in the notebook; embed audio players in the page.
Classical Foundations of Artificial Neural Networks · Bartosz Naskręcki · source on GitHub